Clear Sky Science · ru
Сочетание фрагментации параметров и перестановки групп для защиты от недобросовестного сервера в федеративном обучении
Почему важно защищать совместно используемые модели
Наши телефоны, больницы и банки всё чаще работают на основе искусственного интеллекта. Часто несколько организаций хотели бы совместно обучать общую модель, но законы и здравый смысл запрещают им объединять необработанные данные в одном месте. Федеративное обучение было придумано, чтобы решить это противоречие: каждый участник обучается на своём устройстве и передаёт только обновления модели. Но эта статья показывает, что даже такие обновления могут раскрывать приватную информацию, если центральный сервер любопытен или недобросовестен — и предлагает новый способ сделать как данные, так и личности пользователей более защищёнными.
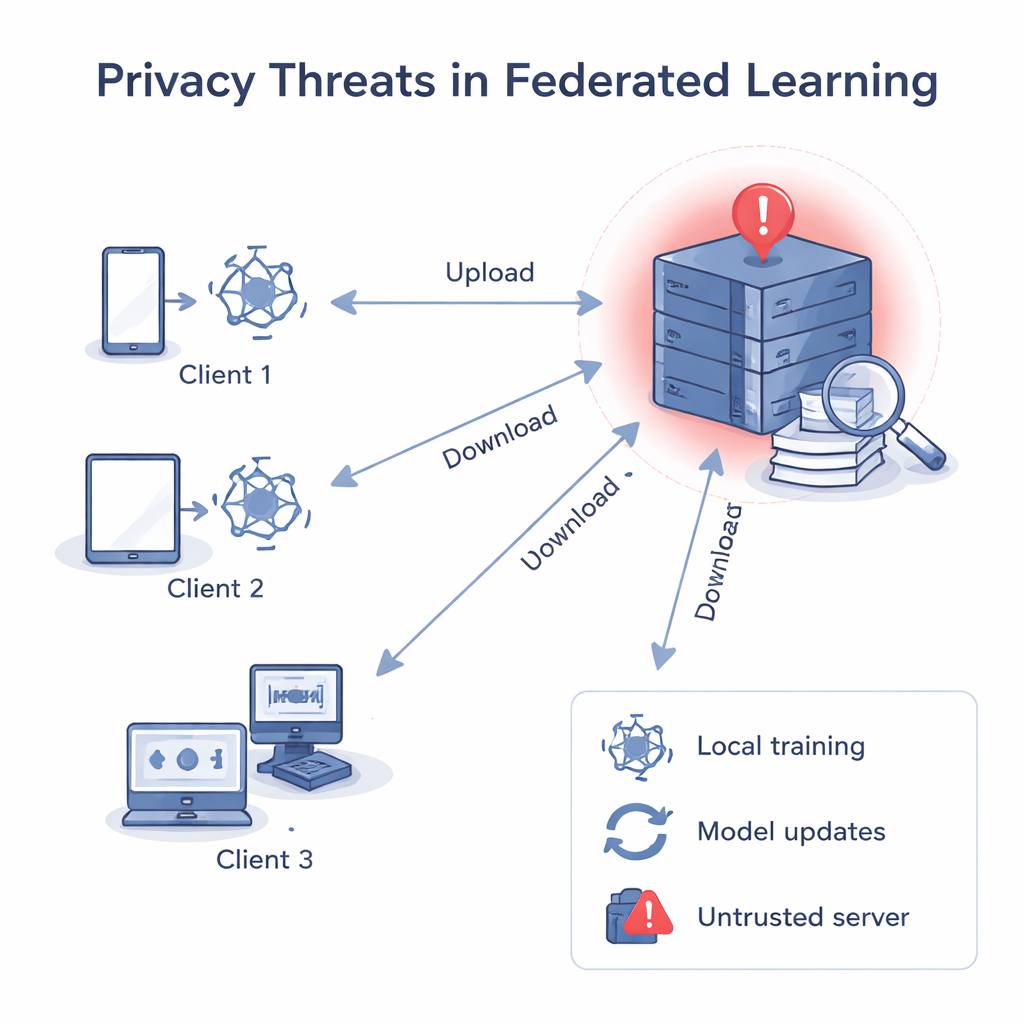
Когда серверу нельзя доверять
В классическом федеративном обучении центральный сервер отправляет общую модель, каждый клиент улучшает её на своих данных и возвращает обновлённую версию. Сервер усредняет эти обновления, получая улучшенную глобальную модель. Хотя необработанные данные никогда не покидают устройства, предыдущие исследования показали, что градиенты и веса — числа внутри модели — можно «прокрутить назад», чтобы восстановить приватные данные, например изображения или текст, или определить, использовалась ли конкретная запись при обучении. Если центральный сервер недобросовестен, он может анализировать обновления каждого клиента по отдельности, узнать о локальных данных этого клиента и даже связать обновление с конкретным человеком или организацией.
Разбиение обновлений на безвредные куски
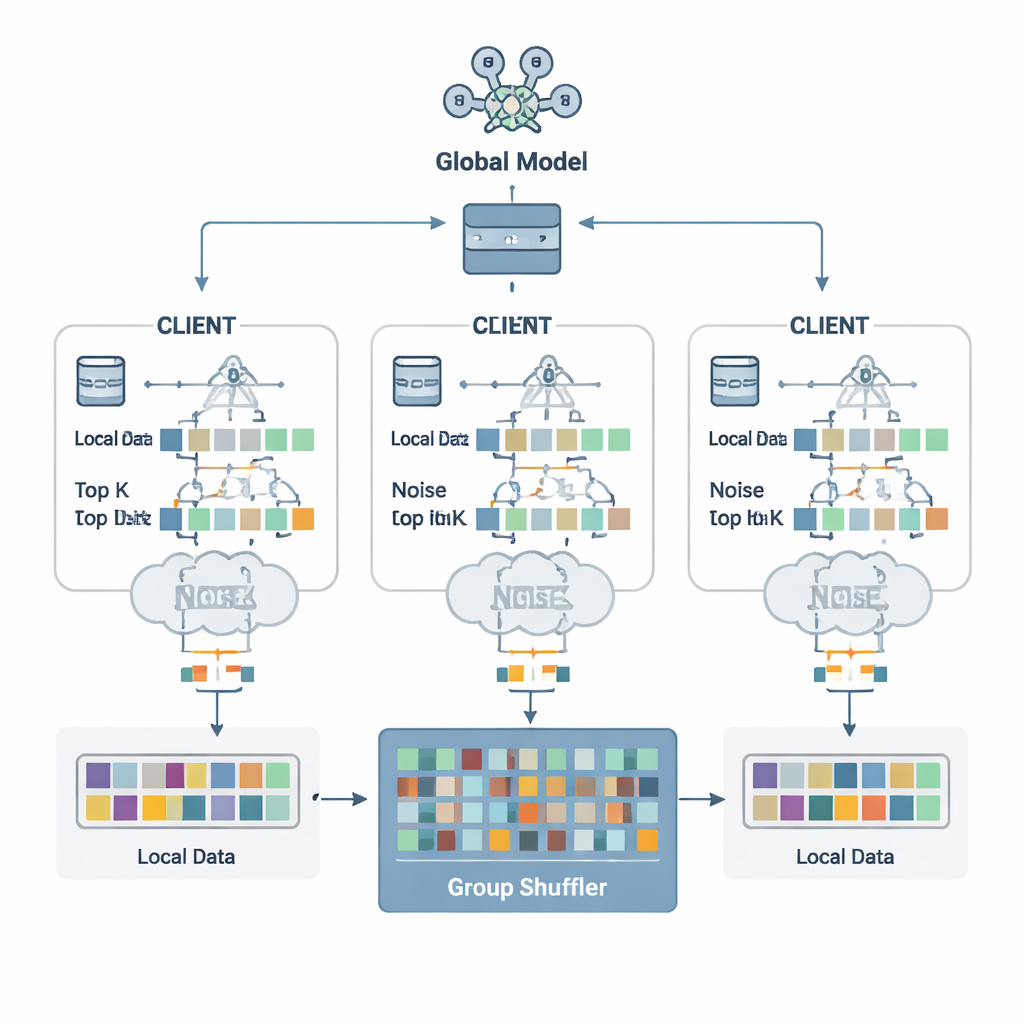
Авторы предлагают схему защиты под названием Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). Первая идея проста, но эффективна: никогда не отправлять полное обновление. Вместо этого каждый клиент разбивает своё обновление модели на несколько искусственных «фрагментов». Большинство таких фрагментов заполняется случайными числами, а только последний корректируется так, чтобы все фрагменты в сумме давали истинное обновление. Любой отдельный фрагмент или даже несколько из них выглядят как шум и почти ничего не выдают о исходных данных. Этот математический приём схож с секретным шейрингом: лишь при объединении всех частей можно восстановить целое.
Добавление шума и перемешивание
Отправка множества фрагментов по‑прежнему могла бы быть расточительной и, если их собрать вместе, позволить атакующему вывести больше информации. Чтобы избежать этого, каждый клиент выбирает только наиболее важные значения фрагментов — Top‑K записей, наиболее значимых для обучения — и добавляет к ним тщательно откалиброванный случайный шум в соответствии с принципами дифференциальной приватности. Этот шум статистически затрудняет определение того, повлияли ли данные какого‑то конкретного человека на данное значение. Другая ключевая часть — групповая перестановка. Вместо прямой отправки фрагментов на сервер клиенты пересылают их доверенному «мешалке» (shuffler), который перемешивает фрагменты от многих клиентов в группы и затем пересылает дальше. После такого перемешивания сервер уже не может определить, какой фрагмент от какого клиента, разрывая связь между обновлениями и личностями.
Сохранение точности при сокращении утечек
Команда протестировала SDPFGS на стандартных наборах для изображений и текста, включая рукописные цифры (MNIST), фотографии одежды (Fashion‑MNIST) и цветные изображения (CIFAR‑10 и CIFAR‑100), а также на задаче классификации новостей. Они сравнили свой метод с несколькими современными техниками приватности, использующими только шум, только перемешивание или простое сжатие градиентов. Во всех экспериментах SDPFGS последовательно соответствовал или превосходил по точности конкурирующие методы, одновременно требуя меньшей коммуникации и времени обучения, чем многие из них. Наиболее заметно, что при атаках инверсии модели — когда злоумышленник пытается восстановить обучающие примеры — SDPFGS показал наименьшую успешность атак, то есть меньше всего раскрывал сведения об исходных данных.
Что это значит для обычных пользователей
Для непрофессионала главный вывод таков: «скрывать данные» недостаточно; нужно также скрывать то, что наши устройства отправляют во время обучения. SDPFGS делает это, превращая каждое обновление модели в зашумлённые, перемешанные фрагменты, бесполезные по отдельности, но совместно дающие высококачественную глобальную модель. В результате получается более прочный щит против любопытного или скомпрометированного сервера при незначительной ценe в точности и эффективности. По мере того как федеративное обучение внедряется в здравоохранение, финансы и умные устройства, такие методы, как SDPFGS, могут помочь обеспечить людям выгоду от мощных совместных моделей, не отдавая ключи от их частной жизни.
Цитирование: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Ключевые слова: федеративное обучение, конфиденциальность данных, дифференциальная приватность, атаки инверсии модели, безопасная агрегация