Clear Sky Science · ru
Разногласия между оценкой планов лечения людьми и ИИ
Почему это важно для повседневной медицинской практики
По мере того как инструменты искусственного интеллекта (ИИ) начинают помогать врачам в выборе лечения, встает ключевой вопрос: чьему суждению мы доверяем больше — людям или машинам? В этом исследовании рассматривается простая, но тревожная возможность: врачи и ИИ могут расходиться не только в выборе «лучшего» лечения, но и в том, что вообще считается «хорошим» планом лечения. Понимание этого разрыва важно, если мы хотим, чтобы ИИ поддерживал, а не тихо искажал, реальные медицинские решения.
Прямое сравнение советов по лечению
Исследователи сосредоточились на дерматологии — области, где врачи ведут хронические кожные заболевания, которые редко имеют единственно «правильный» ответ. Десять опытных дерматологов и две большие языковые модели (LLM) — универсальная модель и модель, ориентированная на рассуждение, — получили задание составить планы лечения для пяти сложных, вымышленных случаев, таких как тяжелый экзема, псориаз при сопутствующих заболеваниях и акне при беременности. Чтобы обеспечить равные условия, все 60 планов были отредактированы в общий формат: одинаковая длина, структура и тон. Любые явные подсказки о том, был ли план написан человеком или ИИ, были удалены, чтобы последующие судьи оценивали содержание, а не стиль.
Как люди и ИИ выступали в роли оценщиков
Затем планы прошли через два раунда слепого оценивания по одной и той же шкале. Сначала та же группа из десяти дерматологов оценила каждый план по общей качественной шкале от 0 до 10, учитывая эффективность, безопасность, практичность и ориентированность на пациента. Во втором раунде отдельная модель ИИ — использованная только как судья, а не как составитель планов — оценила те же самые планы по тем же инструкциям. Существенно, ни человеческие рецензенты, ни ИИ-судья не знали автора каждого плана. Такая схема позволила авторам выделить один ключевой фактор: зависит ли оценка от того, кто оценивает — человек или ИИ.
Люди поддерживают людей, ИИ поддерживает ИИ
Результаты показали четкий «эффект оценщика». Когда планы оценивали люди, они ставили более высокие оценки планам, написанным их коллегами-дерматологами, по сравнению с планами, созданными любой из систем ИИ. Планам, созданным людьми, в среднем ставили немного более высокие баллы, и они заняли первые пять позиций в рейтинге. Одна из моделей ИИ, продвинутая система рассуждений, оказалась ближе к низу списка. Но когда судить стал ИИ, картина перевернулась. Два плана, созданные ИИ, поднялись в верхнюю часть ранжирования, а все планы дерматологов опустились ниже. В среднем ИИ-судья ставил более высокие оценки планам, сгенерированным ИИ, чем человеческим, несмотря на то, что он читал точно такие же стандартизованные тексты, какие видели дерматологи.
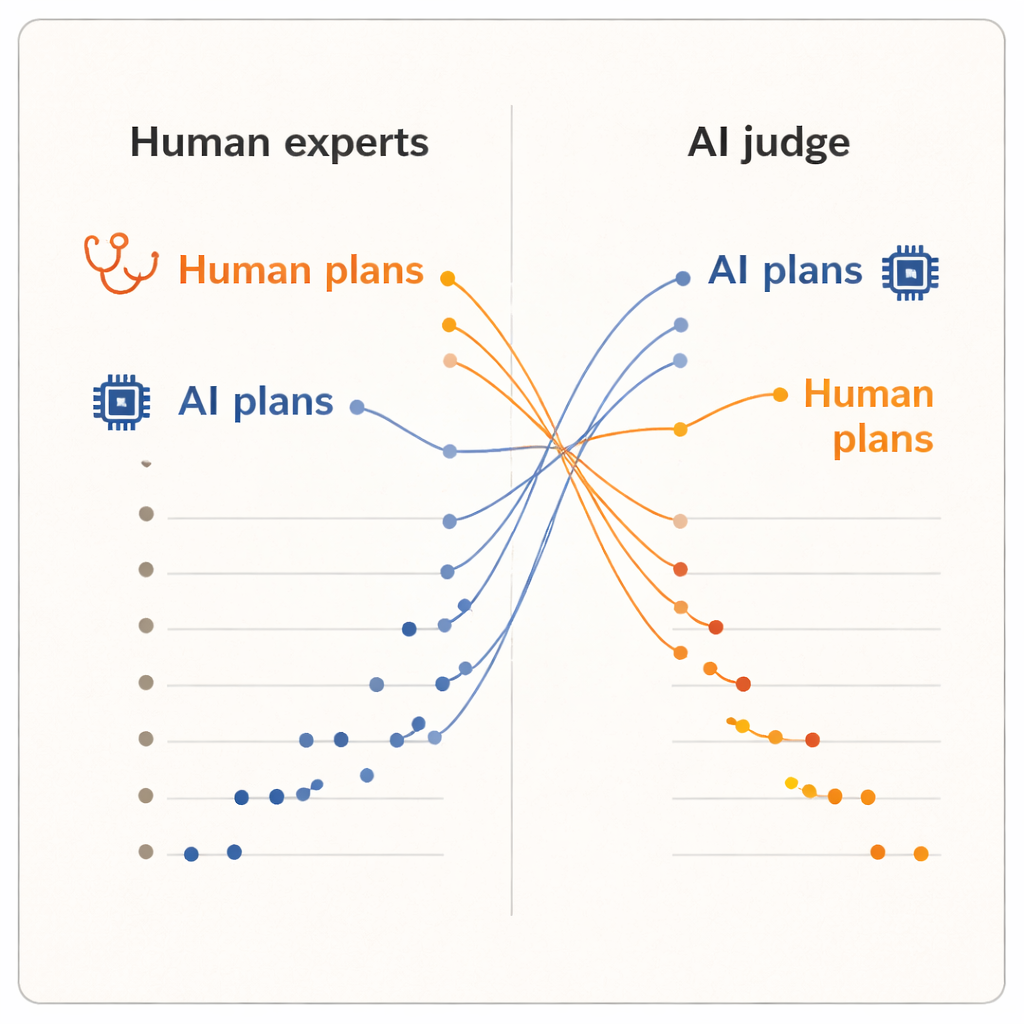
Разные представления о том, что делает план «хорошим»
Поскольку планы были нормализованы по формулировкам, а оценщики не знали источника, авторы утверждают, что этот раскол нельзя объяснить поверхностной обработкой текста. Скорее всего, это указывает на то, что люди и системы ИИ используют разные внутренние «мерки». Клиницисты, вероятно, опираются на реальный опыт: что обычно выполнимо в их клиниках, как пациенты реагируют и какие компромиссы приемлемы на практике. Напротив, ИИ-судья, обученный на больших корпусах текстов, может отдавать предпочтение планам, соответствующим шаблонам, распространенным в медицинской литературе или руководствах, даже если эти шаблоны не в полной мере отражают местные ограничения или предпочтения пациентов. Исследование имеет скромный масштаб — всего десять клиницистов, пять случаев и один ИИ-судья — и оно измеряет восприятие качества, а не реальные исходы пациентов. Тем не менее такое обращение рейтингов достаточно впечатляюще, чтобы поставить более глубокие вопросы о том, как мы оцениваем клинический ИИ.
Переосмысление тестирования и использования клинического ИИ
Из этих результатов авторы делают два широких вывода. Во-первых, традиционные тесты «правильного ответа» для медицинского ИИ упускают многое из того, что важно в реальной медицине, где планы должны учитывать эффективность, безопасность, стоимость, логистику и пожелания пациента. Они призывают к более богатым, многомерным системам оценки, которые явно оценивают эти измерения, используют несколько человеческих и ИИ-оценщиков и анализируют, где и почему возникают разногласия, вместо того чтобы сводить всё к единой цифре. Во-вторых, они предполагают, что различия между человеческими и ИИ-оценками могут быть особенностью, а не просто ошибкой. При осторожном использовании планы, сгенерированные ИИ, могут служить вдумчивым вторым мнением, побуждающим врачей пересмотреть свои предположения, тогда как врачи обеспечивают реальный контекст и этическое суждение, которого не хватает ИИ. Создание надежных, прозрачных интерфейсов, которые показывают предпосылки, позволяют клиницистам настраивать приоритеты и приглашают к критическому обзору, может помочь превратить это напряжение между человеческими и ИИ-перспективами в более безопасный и сбалансированный процесс принятия решений.
Цитирование: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Ключевые слова: поддержка клинических решений, искусственный интеллект в медицине, сотрудничество человека и ИИ, планирование лечения, смещение в оценке