Clear Sky Science · ru
Гибридная модель прогнозирования концентрации PM2.5 на основе высокочастотных и низкочастотных IMF после разложения EMD
Почему точные прогнозы чистоты воздуха важны в повседневной жизни
Мелкие частицы в воздухе, известные как PM2.5, настолько малы, что проникают глубоко в лёгкие и даже попадают в кровоток. В Северном Китае, где сосредоточены тяжёлая промышленность и отопление зимой, эти частицы часто достигают уровней, при которых объявляются предупреждения о риске для здоровья, нарушается транспортное сообщение и даже закрываются заводы и школы. В этом исследовании ставится очень практичный вопрос: можно ли точнее предсказывать почасовые уровни PM2.5, чтобы города и жители получали более ранние и надёжные предупреждения до того, как воздух станет опасным?
Более детальный взгляд на загрязнение воздуха в Северном Китае
Исследователи сосредоточились на шести крупных городах Северного Китая: Пекине, Тяньцзине, Шицзячжуане, Тайюане, Цзинане и Чжэнчжоу. Эти города представляют густонаселённые, индустриализованные территории, где эпизоды загрязнения возникают часто, особенно зимой. Используя официальные данные мониторинга, команда собрала почасовые показания PM2.5 за весь 2021 год, что дало по 8 760 точек данных для каждого города. Было установлено, что уровни загрязнения сильно различаются между городами: например, в Тайюане был зафиксирован самый высокий средний уровень PM2.5, тогда как в Пекине — самый низкий. Экстремальные события были поразительными: в Тайюане концентрации взлетели до 652 микрограммов на кубический метр во время мартовской пыльной и загрязняющей эпизоды, что подтолкнуло индекс качества воздуха к максимальному уровню — явный признак крайне загрязнённого воздуха.
Почему предсказать PM2.5 так сложно
Уровни PM2.5 формируются под воздействием множества факторов одновременно — местные выбросы от транспорта и заводов, региональная транспортировка пыли и дыма, скорость ветра, влажность и другие параметры. В результате запись загрязнения ведёт себя не как плавная кривая, а скорее как изрезанное, беспокойное сердцебиение. Традиционные статистические методы или даже современные нейронные сети могут испытывать трудности с такими данными: они могут уловить общий тренд, но пропустить резкие всплески, или показывать хорошие результаты в одном городе и проваливаться в другом. Ранее исследования пытались улучшить прогнозы либо добавлением большей физической подробности (например, моделей химической транспортировки), либо полагаясь только на сложные методы машинного обучения. В этой работе авторы комбинируют несколько методов, каждый из которых выбран для работы с разным «ритмом» в данных.
Разложение сигнала на быстрые и медленные ритмы
Ключевой шаг — метод, называемый эмпирическим модальным разложением (EMD), который разделяет исходный временной ряд PM2.5 на несколько более простых компонент. Некоторые из этих компонент быстро колеблются и фиксируют краткосрочные всплески и шум; другие меняются медленно и отражают базовый тренд. Авторы объединяют первые пять компонент как «высокочастотные» части, а оставшиеся компоненты вместе с остаточным трендом — как «низкочастотные». Высокочастотные компоненты, которые более нерегулярны и сильно нелинейны, подаются в сеть с долгой краткосрочной памятью (LSTM) — тип глубокой нейронной сети, хорошо подходящий для обучения временным закономерностям. Более гладкие низкочастотные компоненты направляются в классический метод временных рядов ARIMA, эффективный при более регулярном, близком к линейному поведении данных.
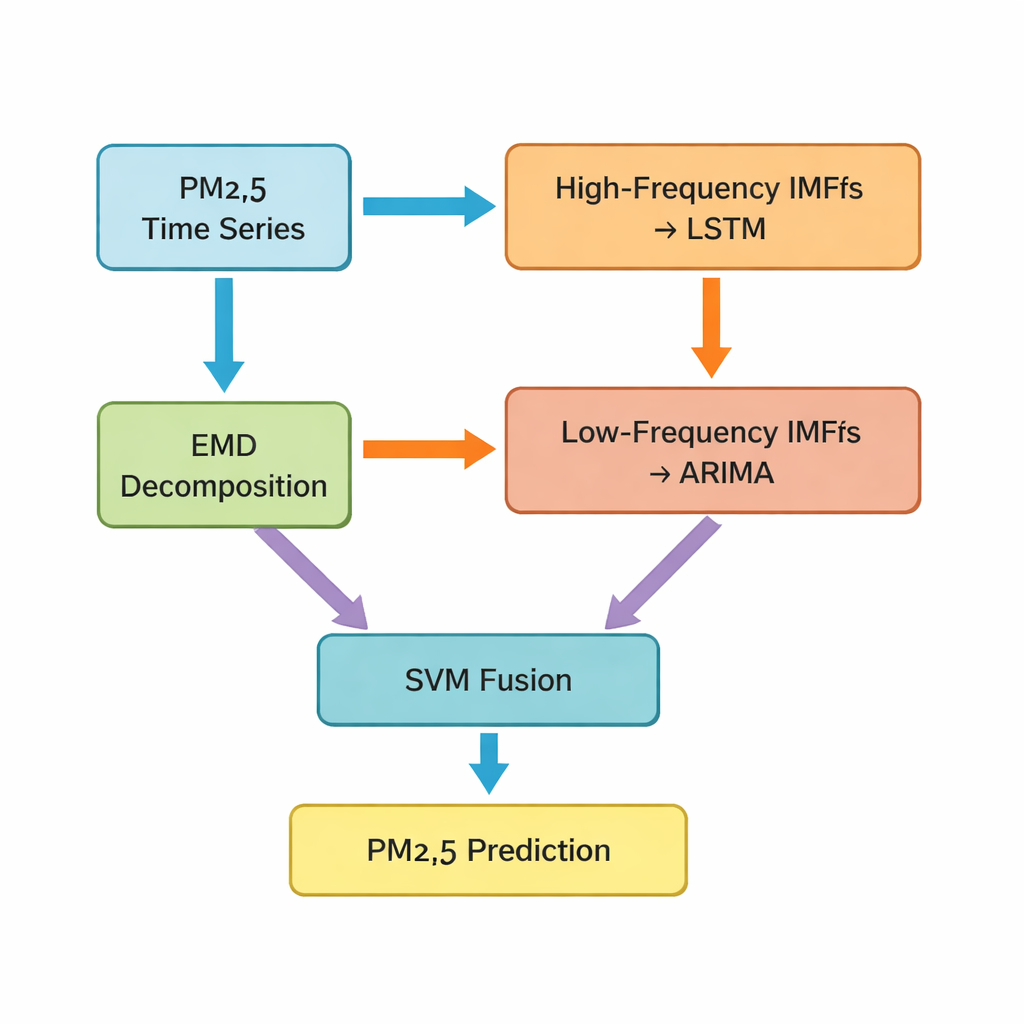
Смешение разных моделей в один более точный прогноз
После того как LSTM и ARIMA дают свои частичные прогнозы, перед исследователями встаёт ещё одна задача: как объединить эти отдельные предсказания в одно итоговое, наилучшее предположение о значении PM2.5 на следующий час. Для этого авторы используют метод опорных векторов (SVM) — ещё один метод машинного обучения, который научается взвешивать и комбинировать два входа. По сути, SVM выступает рефери, решая, когда важнее «быстрый» взгляд на мир (высокочастотные шаблоны), а когда должна доминировать «медленная» перспектива (долгосрочные тенденции). Комбинированная система, которую авторы называют Hybrid‑EMDHL, затем оценивается по нескольким показателям эффективности, включая среднюю ошибку, насколько близко прогнозы соответствуют наблюдаемым значениям и насколько хорошо модель предсказывает направление изменения — будет ли уровень расти или падать.
Более ясные предупреждения и лучшее планирование
Гибридная модель превосходит каждую из своих основных составляющих, использованных по отдельности, во всех шести городах. Она не только сокращает средние и квадратичные ошибки, но и значительно улучшает способность правильно предсказывать, вырастет ли PM2.5 или снизится в следующем часу — критически важная характеристика для своевременных санитарных предупреждений. Во многих случаях гибридный подход уменьшает показатели ошибки более чем вдвое по сравнению с одной нейронной сетью, а точность предсказания направления превышает 0,69, то есть в значительно более чем двух третях тестовых случаев модель верно предсказывает тренд. Для непрофессионала это означает прогнозы качества воздуха в стиле прогноза погоды, при этом более чёткие и надёжные. Для городских планировщиков и органов здравоохранения это практичный инструмент для поддержки целевых ранних действий — например, корректировки работы промышленности или регулирования трафика — до пика эпизода загрязнения, что помогает снизить воздействие и защитить повседневную жизнь в одних из наиболее загрязнённых городских районов Китая.
Цитирование: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Ключевые слова: прогнозирование PM2.5, загрязнение воздуха, Северный Китай, машинное обучение, декомпозиция временных рядов