Clear Sky Science · ru
QPSODRL: усовершенствованный протокол интеллектуальной кластеризации и маршрутизации для беспроводных сенсорных сетей на основе улучшённой квантово-стихийной оптимизации и глубокого обучения с подкреплением
Более разумные сенсорные сети для связанного мира
От прецизионного сельского хозяйства до систем оповещения о катастрофах — беспроводные сенсорные сети тихо наблюдают за окружающим миром, собирая данные со сотен или тысяч крошечных устройств, разбросанных на больших территориях. Их главная уязвимость — в то же время и ключевая особенность: каждый датчик работает от небольшой батарейки, которую трудно или невозможно заменить. В этой статье предложен новый способ организации и управления потоком данных в таких сетях, который позволяет батареям служить дольше, делает передачу информации более надёжной и помогает сети адаптироваться к изменяющимся условиям.
Почему крошечным устройствам нужна серьёзная интеллектуальная поддержка
В беспроводной сенсорной сети каждый узел может измерять, вычислять и передавать данные, но энергия на вес золота. Если некоторые узлы выполняют слишком много работы, они раньше исчерпывают запас энергии, создавая «мертвые зоны», где данные не собираются. Чтобы этого избежать, проектировщики обычно группируют узлы в кластеры. Внутри каждого кластера один узел становится головой кластера: он собирает показания соседей и пересылает их к центральной базовой станции. Выбор того, какие узлы должны быть головами кластеров, и как данные должны перескакивать по сети, — сложная задача, которая меняется по мере разряда батарей. Традиционные правила или одноалгоритмные решения часто слишком быстро сходятся к неоптимальным схемам или терпят неудачу, когда форма сети и уровни энергии эволюционируют со временем.
Сочетание квантово-вдохновлённых стай с обучающимися системами
В данном исследовании представлен QPSODRL — протокол, объединяющий две мощные идеи: квантово-вдохновлённый метод стай для формирования кластеров и движок глубокого обучения с подкреплением для маршрутизации. На первом этапе виртуальные «частицы» исследуют различные способы назначения голов кластеров и их участников. Их поведение направляется мерой того, насколько равномерно распределена энергия по сети, известной как энтропия. При неравномерном энергопотреблении алгоритм поощряет широкое изучение новых схем кластеризации; когда ситуация стабильна, он тонко настраивает перспективные конфигурации. Специальный шаг «элитной перестановки» время от времени подталкивает лучшие кандидаты в новые направления, помогая поиску вырваться из локальных тупиков и избегать чрезмерной нагрузки на одни и те же узлы с высокой энергопотребляемостью. 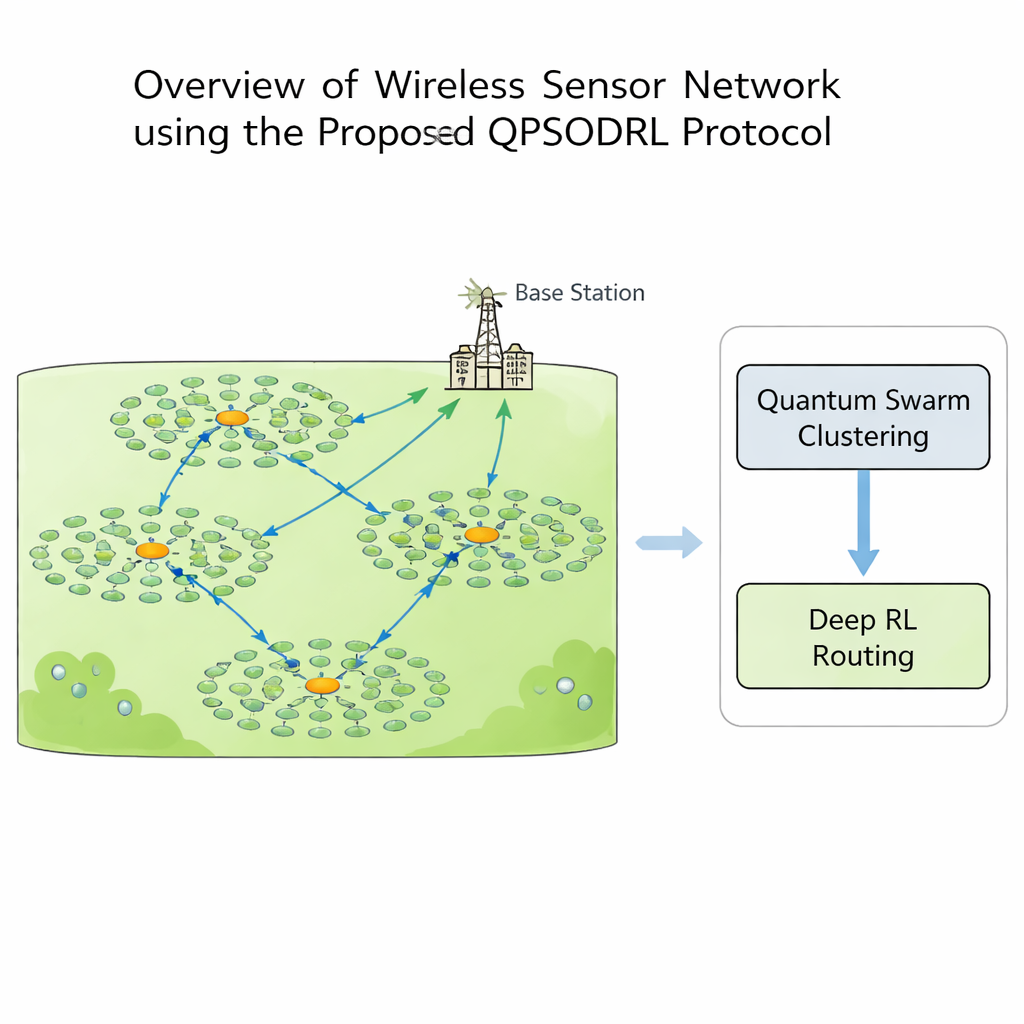
Обучение сети прокладывать лучшие маршруты
После формирования кластеров второй этап решает, как каждая голова кластера должна отправлять свои данные на базовую станцию. Вместо следования фиксированным маршрутам QPSODRL рассматривает каждую голову как агента в процессе обучения. На каждом шаге агент наблюдает за оставшейся энергией самого себя, энергией и расстояниями до соседних голов и оценками задержек, затем выбирает следующий хоп. Специализированная форма глубокого Q‑обучения, называемая Dueling Double Deep Q‑Network, оценивает, насколько хорош каждый выбор в долгосрочной перспективе. Авторы добавляют компонент «энтропии», чтобы препятствовать чрезмерной уверенности системы слишком рано, тем самым поддерживая исследование альтернативных маршрутов. Они также разрабатывают улучшенный механизм воспроизведения опыта, который сознательно фокусируется на наиболее информативных ситуациях — например, при низком заряде батареи или всплесках задержек — чтобы модель быстрее обучалась в тех сценариях, которые имеют наибольшее значение. 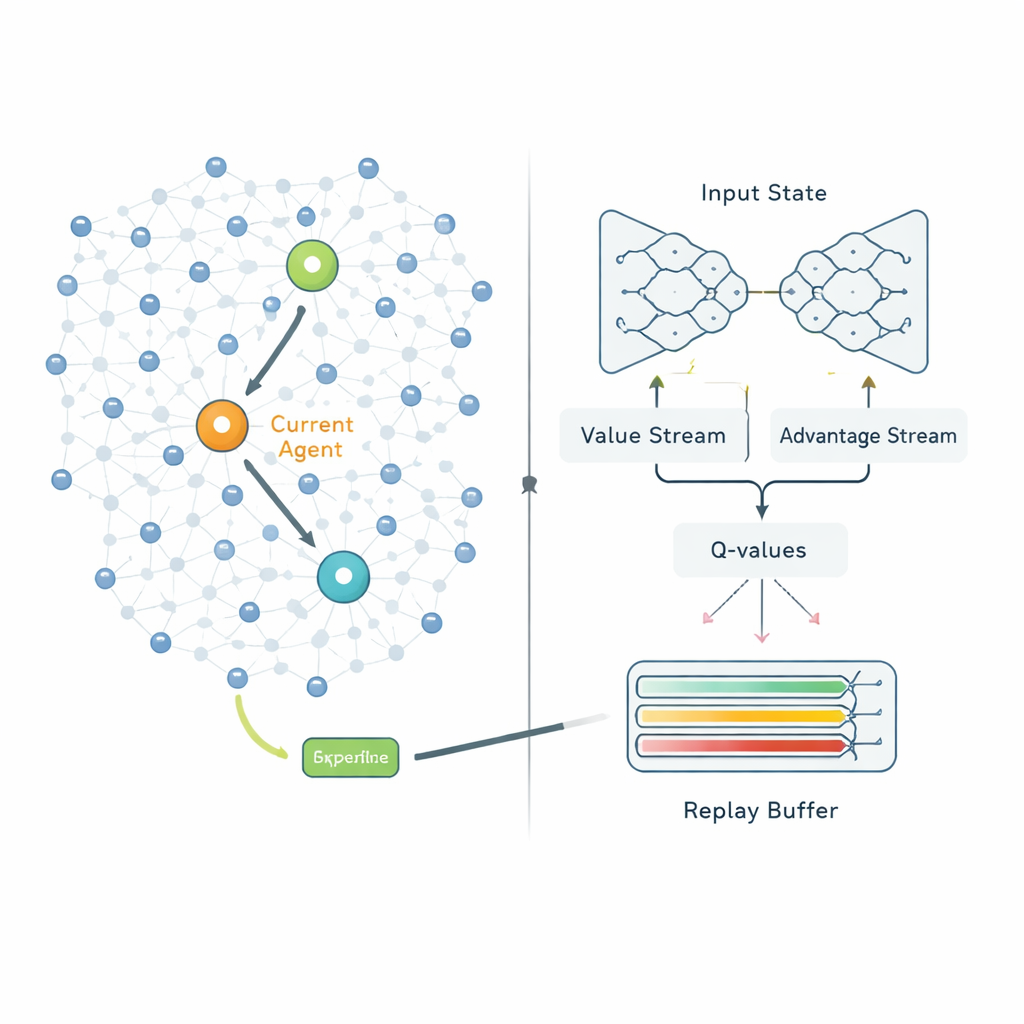
Проверка подхода на практике
Чтобы оценить эффективность QPSODRL, автор проводит подробные компьютерные симуляции сетей с 100 и 200 узлами, распределённых по площадям разного размера и с разной долей узлов, выступающих головами кластеров. Новый протокол сравнивается с четырьмя современными конкурентами, использующими методы частичных стай, оптимизацию китов, нечёткую логику и другие гибридные и обучаемые схемы. Во всех протестированных конфигурациях QPSODRL поддерживает сеть живой на большее число раундов коммуникации, доставляет больше пакетов данных до базовой станции и потребляет меньше суммарной энергии. Он также более равномерно распределяет нагрузку между головами кластеров, что видно по меньшей вариации объёма трафика на каждую голову. Эти преимущества особенно заметны в тяжёлых раскладках, где базовая станция расположена на краю поля, вынуждая некоторые узлы совершать более дальние пересылки.
Что это означает для реальных систем
Для неспециалистов главный вывод таков: предоставление сенсорным сетям способности как глобально оптимизировать свою структуру, так и локально учиться на опыте может значительно продлить их срок полезной службы. Кластеризация QPSODRL, вдохновлённая квантовыми идеями, поддерживает баланс энергопотребления, в то время как маршрутизация на основе глубокого обучения адаптируется к меняющимся условиям без постоянной ручной настройки. Хотя результаты получены на моделях с неподвижными, фиксированными узлами, они указывают на то, что будущие развертывания сенсорных систем — от умных городов до экологических обсерваторий — могли бы работать дольше, реже выходить из строя и эффективнее использовать ограничённую батарейную энергию, приняв аналогичные интеллектуальные стратегии управления.
Цитирование: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Ключевые слова: беспроводные сенсорные сети, энергоэффективная маршрутизация, глубокое обучение с подкреплением, стихийная оптимизация, кластеризация сети