Clear Sky Science · ru
Интеграция знаний для физически-информированной символической регрессии с использованием предварительно обученных больших языковых моделей
Обучая компьютеры угадывать формулы природы
Многие ключевые идеи в науке выражаются аккуратными формулами: от того, как падает мяч, до того, как световые волны распространяются в пространстве. В этой статье рассматривается новый способ помочь компьютерам автоматически заново открывать такие уравнения по сырым данным, позволяя им консультироваться с большой языковой моделью — тем же типом ИИ, который стоит за современными чат-ботами — чтобы их предположения были не только точными, но и физически осмысленными.
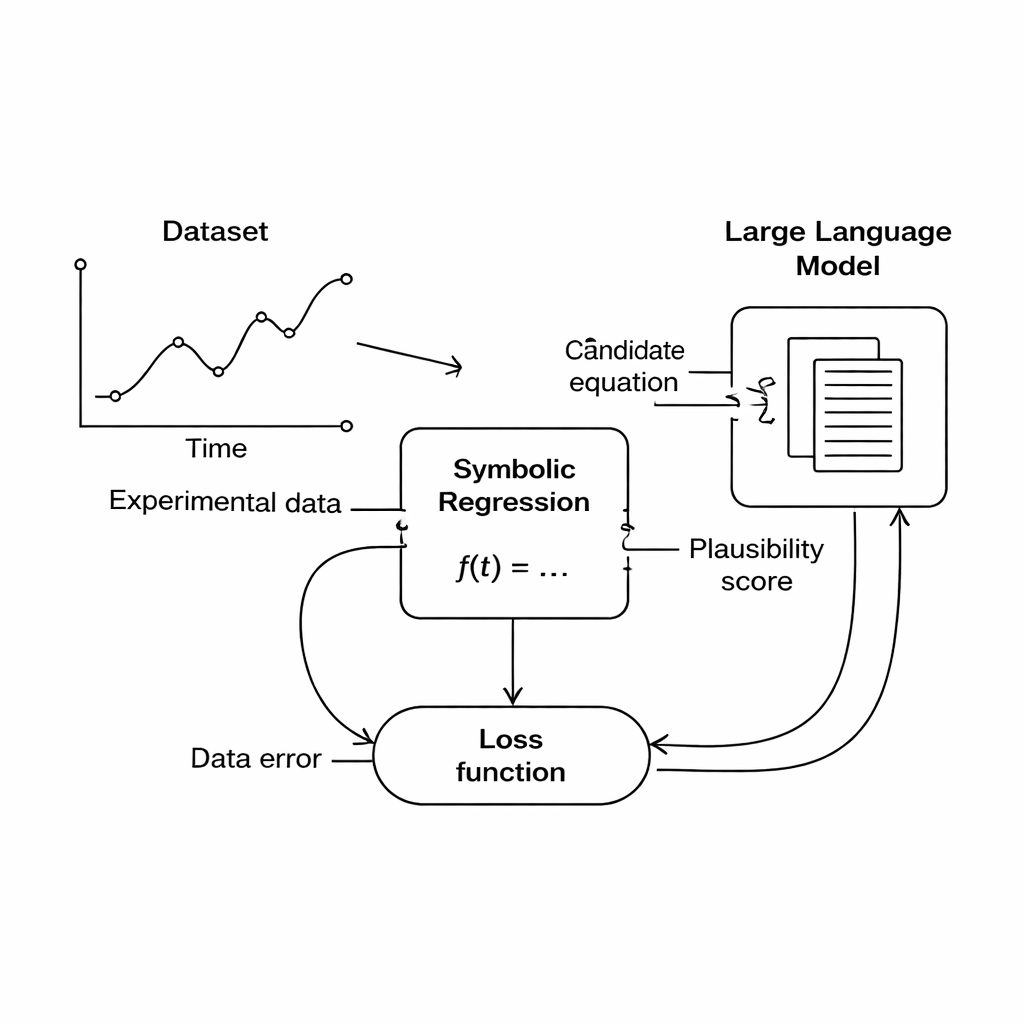
От сырых данных к законам, понятным человеку
Авторы сосредотачиваются на методе, называемом символической регрессией, который ищет математическую формулу, связывающую измеренные входы и выходы. В отличие от обычной аппроксимации кривых, символическая регрессия не начинается с фиксированной формы формулы; вместо этого она строит и эволюционирует кандидаты в уравнения, пока одно из них хорошо не подойдёт к данным. Это делает метод перспективным для научных открытий, поскольку он потенциально может выявлять новые зависимости, которых раньше никто не записывал. Однако есть загвоздка: формула, идеально подогнанная под данные, всё ещё может быть бессмыслицей с точки зрения физики — например, складывать расстояние и время или давать размерности, не соответствующие никакой реальной величине.
Почему физическая интуиция всё ещё важна
Чтобы избежать таких абсурдов, исследователи разработали «физически-информированные» варианты символической регрессии, встраивающие известные правила природы в поиск. Эти методы поощряют уравнения, которые, например, сохраняют энергию или соблюдают размерную согласованность. Однако кодирование таких знаний обычно требует от экспертов вручную создавать ограничения и специальные функции потерь для каждой новой задачи. Это делает подход мощным, но трудным для обобщения. Для каждой новой физической системы может потребоваться собственная тщательная проработка, что ограничивает доступность этих инструментов для непрофессионалов.
Позволить языковым моделям оценивать уравнения
В этом исследовании предлагается другой путь: вместо жёсткого кодирования правил предметной области использовать большую языковую модель (LLM) в качестве гибкого судьи научной правдоподобности. Во время поиска движок символической регрессии генерирует кандидатные уравнения, которые в той или иной степени подгоняют данные. Каждое уравнение затем переводится в текст и отправляется LLM вместе с коротким подсказом, описывающим задействованные величины и любые известные физические ограничения. LLM возвращает оценки по трем аспектам: соответствуют ли размерности уравнения, насколько оно просто и кажется ли оно физически правдоподобным. Эти оценки включаются в основную целевую функцию, так что компьютер теперь балансирует между «подходит под данные» и «выглядит как хорошая физика» при выборе уравнений для дальнейшего улучшения.
Проверка метода на практике
Чтобы оценить, насколько это работает, авторы провели обширные компьютерные эксперименты на трех классических задачах: свободное падение шара в земной гравитации, гармонические колебания массы на пружине и затухающая электромагнитная волна. Для каждой системы они смоделировали тысячи зашумленных измерений в различных условиях, а затем попросили три популярных программы для символической регрессии восстановить исходные уравнения — либо с помощью LLM, либо без неё. Они использовали три компактные открытые языковые модели — Mistral, Llama 2 и Falcon — и исследовали, как разные варианты подсказок, от минимального контекста до полного описания и даже с указанием истинной формулы, изменяли руководство LLM. В большинстве настроек добавление оценки от LLM улучшало соответствие восстановленных уравнений известным законам и делало их более устойчивыми к шуму, при этом сочетание PySR (библиотека символической регрессии) и Mistral в целом показывало лучшие результаты.
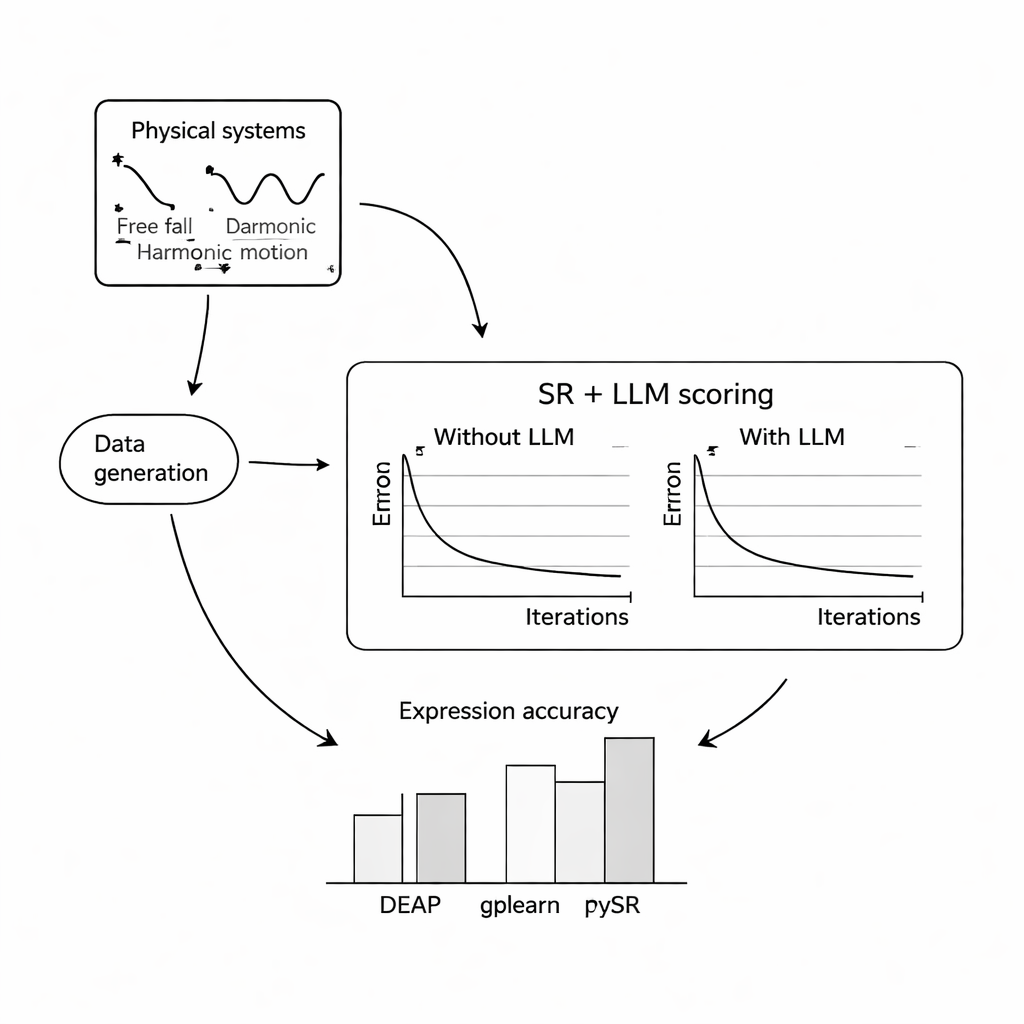
Когда слова направляют математику
Ключевой вывод состоит в том, что формулировка подсказки сильно влияет на результаты. Когда подсказки включали чёткие описания переменных, характер эксперимента и иногда точную целевую формулу, поиск с помощью LLM более надёжно сходился к правильной структуре. В таких насыщенных случаях обнаруженные уравнения часто были структурно идентичны истинным законам, а не просто численно близки. Авторы также протестировали, как подход выдерживает возрастание уровня случайного шума измерений. Хотя все методы ухудшались по мере увеличения шума и сложности исходных уравнений, версии с дополнением от LLM, как правило, теряли точность медленнее, чем стандартные аналоги, что указывает на то, что чувство правдоподобия у языковой модели может действовать стабилизирующе.
Что это значит для будущих открытий
Для широкой аудитории главный вывод таков: текстовый ИИ может делать гораздо больше, чем писать эссе или отвечать на вопросы — он также способен направлять другие алгоритмы к научным уравнениям, которые «чувствуются правильными» с точки зрения наших существующих знаний о природе. Представленный метод не гарантирует, что каждое обнаруженное уравнение верно, и по-прежнему требует человеческого контроля и тщательно подобранных подсказок. Но он показывает, что большие языковые модели, обученные на океанах научных текстов, могут служить повторно используемым источником предметных знаний, помогая автоматизированным инструментам перейти от слепого подгона данных к выдвижению законов, которые учёные могут интерпретировать, проверять и развивать дальше.
Цитирование: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Ключевые слова: символическая регрессия, физически-информированный ИИ, большие языковые модели, научное открытие, обучение уравнениям