Clear Sky Science · ru
Подход глубокого обучения с подкреплением к анализу танцевальных движений
Обучение компьютеров «смотреть» танец так же, как мы
От балета до хип‑хопа — в танце полно тонких изменений ритма и поз, которые человеческий взгляд улавливает мгновенно, тогда как компьютеры с этим испытывают трудности. В этом исследовании предложен новый способ, чтобы искусственный интеллект «смотрел» танцевальные видео ближе к тому, как это делает эксперт‑человек: пропускать рутинные эпизоды и сосредотачиваться на кратких, показательны моментах, которые определяют стиль. В результате получилась система, которая точнее распознаёт жанры танца, просматривая при этом намного меньше видео — потенциальный выигрыш для цифровых архивов, спортивных и развлекательных технологий.
Почему танцевальные видео сложны для машин
На первый взгляд обучение компьютера распознавать стили танца звучит просто: подай видео и пусть глубокие сети найдут паттерны. На самом деле большинство существующих систем тратят ресурсы впустую. Стандартные модели видео либо обрабатывают каждый кадр, либо отбирают клипы через равные интервалы, подразумевая, что все моменты одинаково важны. Но стили танца часто различаются в мелких деталях — в повороте стопы, в том, когда партнёр делает разворот, или в точной фазировке вращения — а не в постоянном движении. Это значит, что многие кадры повторяются или дают мало информации, а ключевые позы могут оказаться между фиксированными точками выборки, что приводит к путанице, например, между вальсом и фокстротом.
Более умный способ пролистывать видео
Исследователи предлагают фреймворк под названием Reinforcement‑based Attentive Temporal Sampling, или RATS, который рассматривает анализ видео как активный поиск, а не пассивный просмотр. Вместо того чтобы идти кадр за кадром, система разбивает танцевальное видео на короткие клипы и сначала переводит каждый клип в компактное описание движения с помощью специализированной 3D‑свёрточной сети. Эти сводки движений сохраняются в памяти. Сверху действует агент принятия решений, который перемещается по последовательности клипов, выбирая: продвинуться небольшим шагом, сделать больший прыжок или остановиться и выдать предсказание стиля. По сути, система учится просматривать время, задерживаясь на показательных паттернах и пропуская менее полезные отрезки.
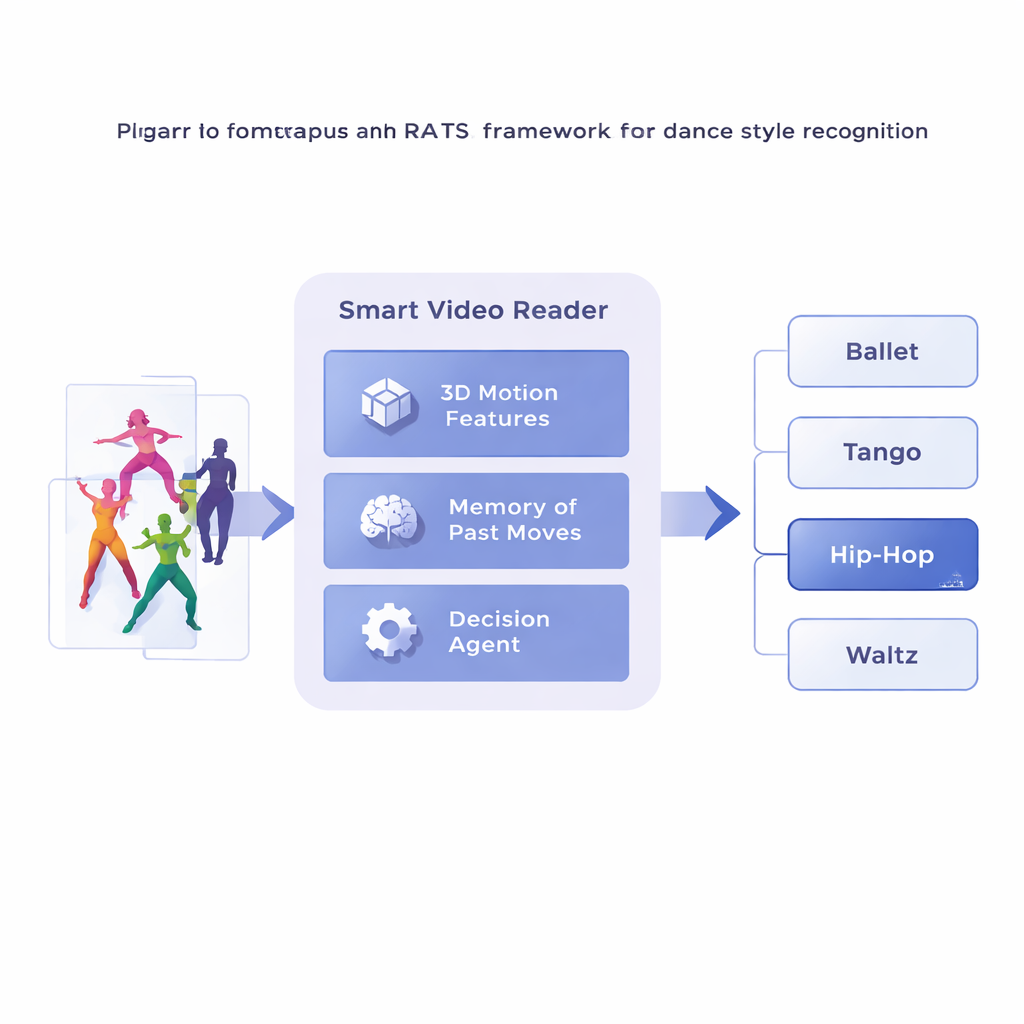
Научиться, когда смотреть и когда решать
Чтобы принимать взвешенные решения, агент опирается на форму памяти, вдохновлённую тем, как мы вспоминаем прошедшее и отслеживаем зарождающееся движение. Двунаправленная рекуррентная сеть отслеживает, что система уже «видела» и как текущие клипы соотносятся с этой историей. На каждом шаге агент взвешивает три варианта: сделать короткий скачок, чтобы рассмотреть мелкие детали вроде работы стоп, совершить более длинный прыжок через повторяющееся движение или остановиться и классифицировать танец. Систему обучают с помощью вознаграждений и штрафов: она получает большое положительное вознаграждение за правильное решение, большое отрицательное — за ошибку, и небольшой штраф при каждом прыжке вперёд. Такой баланс поощряет агента быть одновременно точным и эффективным — ждать достаточных доказательств, но не просматривать всё видео целиком.
Превосходство над обычными классификаторами танцев
Команда протестировала RATS на наборе данных Let’s Dance — сложной коллекции из 1000 видео, охватывающей десять стилей, от фламенко и танго до свинга и квадрата. По сравнению с несколькими существующими методами, включая стандартные глубокие сети и другие модели, ориентированные на танец, RATS показал наивысшую точность — около 92% — и лучшее общее соотношение точности и полноты. Он также оказался статистически лучше сильных конкурентов, а не просто немного отличался случайно. Важно, что система достигла этих результатов, анализируя в среднем только около 38% кадров видео. Равномерная выборка через несколько кадров была быстрее, но пропускала ключевые моменты и снижала качество; обработка каждого кадра была медленнее и всё же менее точна по сравнению с целенаправленным подходом.
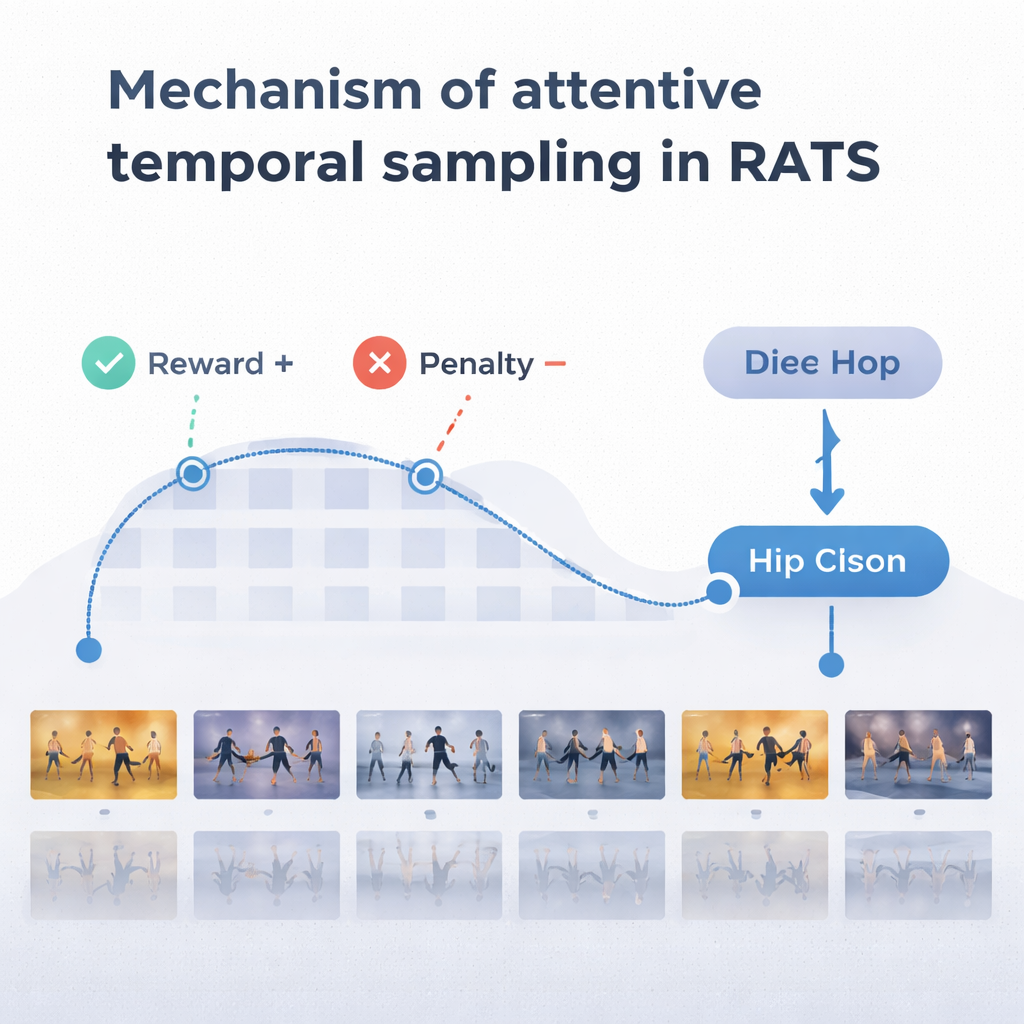
Что это значит за пределами танцпола
Для неспециалиста основная мысль проста: компьютеры работают лучше, когда их учат быть избирательными зрителями. Научив ИИ концентрироваться на «золотых моментах» во времени, эта работа показывает, что машины могут точнее распознавать сложные человеческие движения, используя при этом меньше ресурсов. Хотя исследование сосредоточено на танце, та же идея может помочь системам выделять ключевые элементы в спортивных выступлениях, кадровых записях безопасности или в любом длинном видео, где важные события кратки и разбросаны. Иными словами, умный просмотр — а не больше просмотра — может стать будущим понимания видео.
Цитирование: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Ключевые слова: распознавание танца, анализ видео, глубокое обучение, обучение с подкреплением, человеческое движение