Clear Sky Science · ru
Модель извлечения пространственных отношений для китайского языка с интеграцией географических семантических признаков
Обучая компьютеры понимать, где находятся места
Каждый день мы описываем местоположения простыми фразами: город расположен к югу от реки, парк рядом с университетом, автомагистраль проходит через провинцию. Преобразование такого повседневного языка в точное цифровое знание важно для «умных» карт, навигационных приложений и географических исследований. В этой статье представлен новый метод, названный PURE‑CHS‑Attn, который помогает компьютерам читать тексты на китайском и автоматически точнее определять пространственные отношения между объектами.
Почему пространственный язык важен
Пространственные отношения — это слова и фразы, которые сообщают, как объекты связаны в пространстве, например «внутри», «рядом», «севернее» или «в 30 километрах от». Они создают мост между реальным миром на картах и понятиями, которые мы используем мысленно. В геоинформационных системах (ГИС) эти отношения лежат в основе организации, поиска и анализа данных. Они также важны в других областях: например, при объединении спутниковых снимков, отслеживании движения в видео, планировании промышленных площадок или исследовании того, как климат и рельеф формируют биоразнообразие. Поскольку большая часть этой информации записана на естественном языке, необходимы надежные инструменты, которые могут читать текст и автоматически извлекать пространственные отношения.
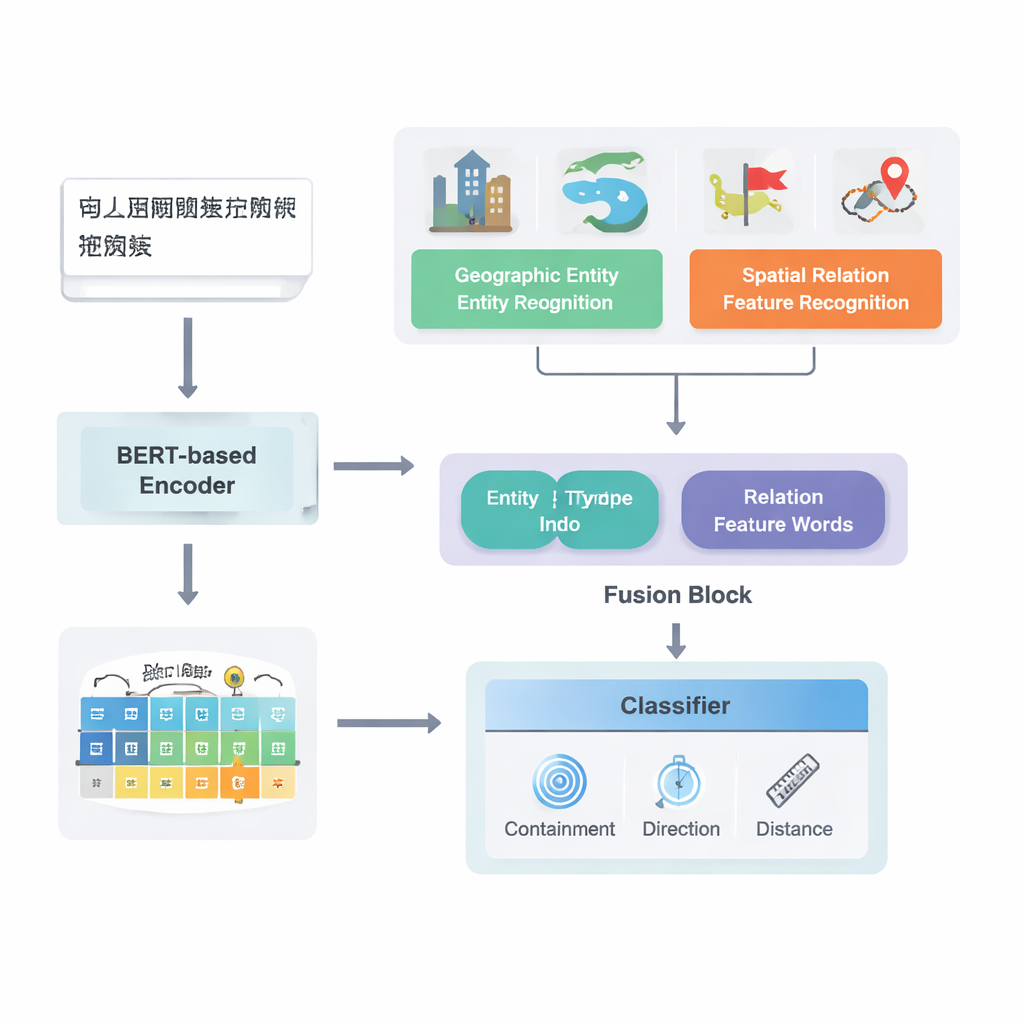
От сырого текста к картографированным отношениям
Авторы сосредоточены на китайских текстах и опираются на мощную существующую глубокую модель конвейера под названием PURE. Их улучшенная модель PURE‑CHS‑Attn работает в несколько этапов. Сначала она просматривает предложения, чтобы найти географические сущности, такие как горы, реки, города и административные районы, и маркирует каждую по типу (например, суша, водный объект, общественное учреждение, исторический объект или административная единица). Затем модель обнаруживает «ключевые слова» пространственных отношений — такие как «граничит», «протекает через», «к югу от» или «рядом» — которые сигнализируют о связи между двумя объектами. Мощная языковая модель BERT‑wwm‑ext преобразует символы в предложении в числовые векторы, отражающие их значение и контекст. Эти векторы подаются в отдельные компоненты, которые распознают сущности и слова‑сигналы отношений, а затем передают свои результаты в модуль слияния.
Сочетание человеческих знаний и машинного обучения
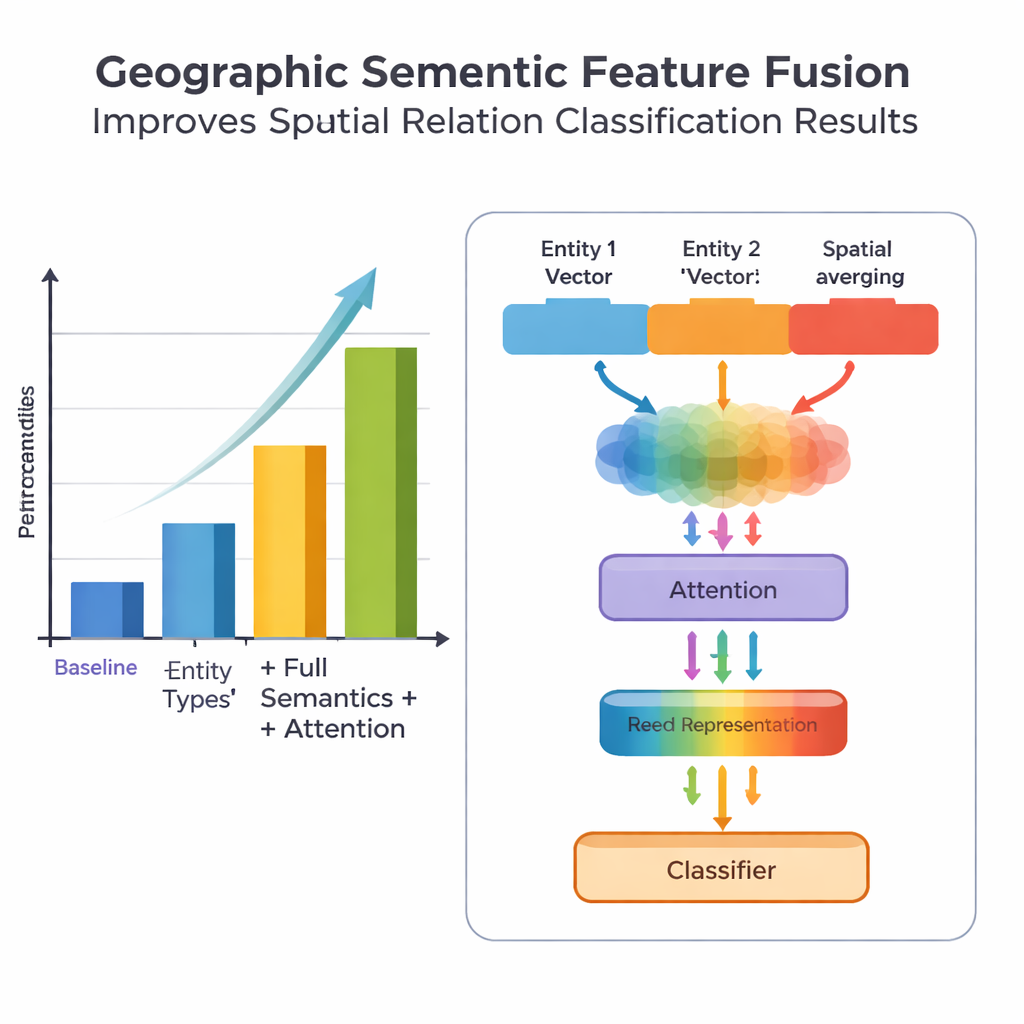
Ключевая новизна работы заключается в том, как она объединяет географические знания с выученными текстовыми шаблонами. Вместо того чтобы рассматривать каждое слово одинаково, модель использует два вида семантической информации, которые люди естественно применяют: тип каждой географической сущности и конкретные пространственные слова, соединяющие их. Модуль слияния сначала комбинирует векторы для двух сущностей с весами, зависящими от того, насколько часто разные типы объектов (например, две административные единицы против реки и уезда) участвуют в определённых типах отношений. Затем он добавляет векторы пространственных ключевых слов. Поверх этой «базовой» агрегации авторы вводят механизм внимания, который позволяет модели динамически фокусироваться на наиболее информативных частях комбинации «сущность–слово». Итоговое слитое представление передаётся классификатору, который может назначать один или несколько типов отношений — топологические (например, вложение или смежность), направленные (север, юг и т. п.) или основанные на дистанции — для каждой пары объектов в предложении.
Проверка модели
Для оценки своего подхода команда собрала и тщательно аннотировала набор данных из Энциклопедии Китая: Китайская география, содержащий 1381 предложение и 368 пар пространственных отношений. Они сравнили несколько вариантов модели: базовую, использующую только грубую информацию о местоположении; вариант с более точными типами сущностей; вариант, в который добавлены пространственные ключевые слова; и их полный PURE‑CHS‑Attn с новой схемой слияния и вниманием. По стандартным метрикам точности, полноты и F1‑меры PURE‑CHS‑Attn улучшил результаты примерно на 7% по точности, на 6.5% по полноте и на 6.7% по F1 по сравнению с базовой моделью. Модель особенно успешно распознавала топологические и направленные отношения и лучше справлялась с редкими «few‑shot» типами отношений, чем более простые модели. В сравнении с тремя недавними передовыми системами, включая одну на основе крупных языковых моделей, PURE‑CHS‑Attn заняла близкое второе место, оставаясь при этом значительно легче и проще в развертывании.
Проблемы и направления дальнейшей работы
Несмотря на эти улучшения, модель по‑прежнему испытывает трудности с отношениями по расстоянию, особенно когда имеется лишь небольшое количество тренировочных примеров. Авторы показывают, что в их наборе данных таких случаев очень мало, что ограничивает возможности любого метода, требующего больших объёмов данных. Они также отмечают, что слепое усреднение множества пространственных ключевых слов в предложении может вносить шум, который их механизм внимания частично, но не полностью устраняет. Взгляд в будущее предлагает два перспективных направления: расширение и балансировка тренировочных данных с помощью аугментации, а также сочетание их географического семантического слияния с методиками крупных языковых моделей и обучением с подсказками, чтобы дополнительно повысить производительность в условиях дефицита данных, сохранив при этом эффективность системы.
Что это значит для повседневного картографирования
Проще говоря, это исследование учит компьютеры читать пространственные описания на китайском более по‑человечески — обращая внимание на то, какие типы мест упомянуты и как именно сформулированы их отношения. Модель PURE‑CHS‑Attn показывает, что сочетание структурированных географических знаний с современным глубоким обучением ведёт к более точному и устойчивому извлечению «кто где относительно чего» из текста. Это прокладывает путь к более интеллектуальным, автоматизированным ГИС‑системам, более богатым географическим графам знаний и лучшим инструментам для исследования того, как пространство описывается в науке, политике и повседневном общении.
Цитирование: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Ключевые слова: извлечение пространственных отношений, геопространственный ИИ, географическая семантика, майнинг текстов на китайском, автоматизация ГИС