Clear Sky Science · ru
Стохастический LASSO для исключительно высокоразмерных геномных данных
Поиск иголок в геномных стогах сена
Современная биология может одновременно измерять десятки тысяч генов, тогда как в исследованиях пациентов часто участвует лишь несколько сотен человек. В этом дисбалансе скрываются небольшие наборы генов, которые действительно важны для прогнозирования риска заболевания или выживания. В статье представлен «Стохастический LASSO» — статистический метод, разработанный для надежного выявления этих ключевых генов среди океанов шумных геномных данных, даже когда генов существенно больше, чем пациентов.
Почему выбор правильных генов так сложен
Исследователи часто используют инструменты вроде LASSO, которые сжимают коэффициенты несущественных генов к нулю, сохраняя наиболее информативные. Классические версии LASSO, однако, испытывают трудности, когда число генов значительно превышает число образцов, как это часто бывает в онкогеномике. Стандартный LASSO может выбрать не более генов, чем пациентов, и имеет склонность «пропускать» гены с похожим поведением. Ранние улучшения, вводящие дополнительные штрафы, частично решают проблему корреляции, но могут размывать биологический смысл, заставляя связанные гены выглядеть так, будто они все влияют на исход в одном направлении.
Построение более чистых случайных выборок
Одно перспективное решение — многократно подгонять LASSO на многих меньших случайных поднаборах генов и затем объединять результаты. Тем не менее такие «bootstrap»‑подходы по‑прежнему сталкиваются с тремя проблемами: скоррелированные гены могут взаимно компенсировать эффект, многие гены редко или никогда не попадают в выборки, а чистая случайность делает финальный отбор нестабильным. Стохастический LASSO решает эти задачи с помощью новой схемы выборки, называемой бутстрэппингом на основе корреляции. Вместо случайного выбора генов он преднамеренно отдает предпочтение генам, менее скоррелированным с уже выбранными, что даёт меньшие наборы генов с большей независимостью. Кроме того, метод гарантирует, что каждый ген используется одинаковое число раз во всех бутстрэп‑прогонах, чтобы ни один ген несправедливо не игнорировался. 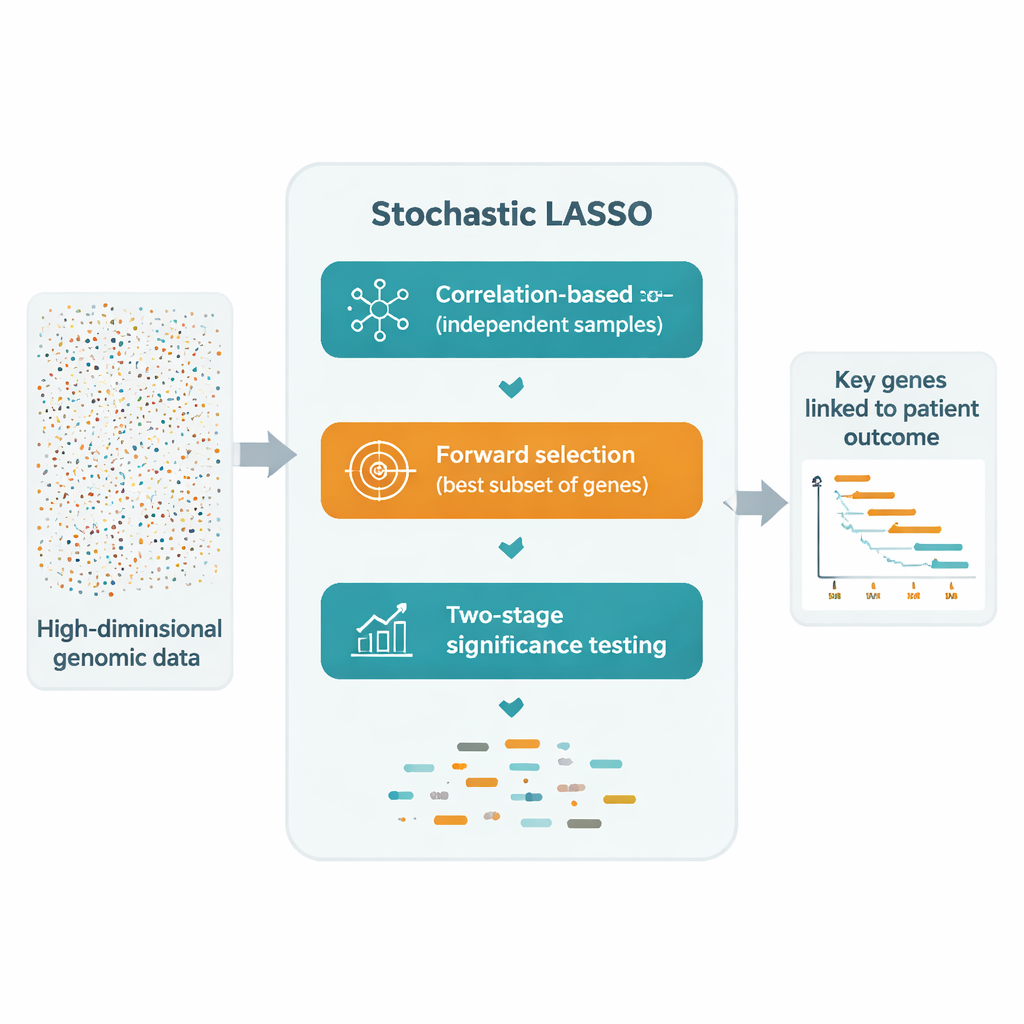
От локальных подсказок к глобальному набору генов
После построения таких более чистых поднаборов Стохастический LASSO фиксирует величину коэффициента каждого гена во всех бутстрэп‑подгонках. Это среднее абсолютное значение эффекта становится «локальным баллом», отражающим, насколько последовательно важен ген. Вместо исчерпывающего перебора всех возможных комбинаций метод строит кандидатские модели, добавляя гены в порядке убывания локальных баллов, и оценивает, насколько хорошо каждая модель предсказывает исходы на отдельной валидационной выборке. Таким образом он останавливается на компактном наборе генов, чьи совместные сигналы лучше всего объясняют данные, затрачивая при этом гораздо меньше попыток, чем традиционные пошаговые методы.
Тестирование, какие гены действительно важны
Чтобы перейти от «часто выбираемых» к «статистически убедительным», авторы вводят двухэтапный t‑тест. Сначала проверяется, отличается ли средний коэффициент каждого гена по бутстрэпам ясно от нуля — такие гены помечаются как потенциально значимые. Затем среди этих кандидатов оценивают, превышает ли эффект конкретного гена типичный размер эффекта всех кандидатов. Только гены, прошедшие оба теста, объявляются значимыми. Поскольку тесты опираются на многочисленные бутстрэп‑оценки, Стохастический LASSO может уверенно выявлять больше значимых генов, чем число пациентов — то, чего не способен сделать обычный LASSO. 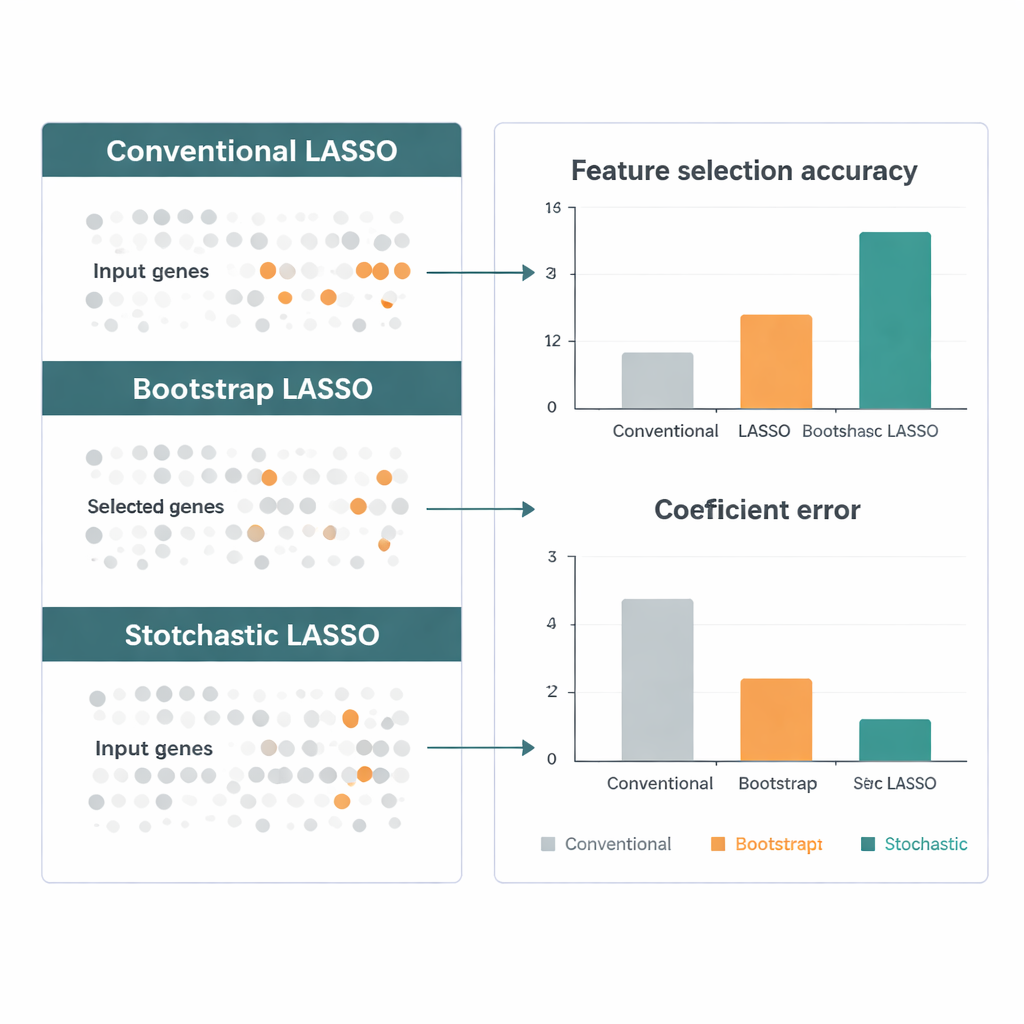
Доказательства эффективности в симуляциях и данных по раку
Авторы сравнили Стохастический LASSO с несколькими ведущими вариантами LASSO на симулированных данных, моделирующих реальные геномные исследования: очень много генов, сильные корреляции и известные «истинные» сигналы. В разных сценариях новый метод чаще находил правильные гены, точнее оценивал их эффекты и оставался стабильным от прогона к прогону. Затем они применили метод к данным экспрессии генов из The Cancer Genome Atlas для опухолей мозга, включая агрессивную глиобластому. Стохастический LASSO выделил сотни генов, чья активность связана с выживаемостью пациентов, и отметил биологические пути — например, сигнальные и метаболические пути лекарственных средств — которые имеют независимую поддержку в литературе, что говорит о том, что метод не только статистически точнее, но и биологически обоснован.
Что это значит для пациентов и исследователей
Для неспециалистов ключевая мысль такова: Стохастический LASSO — более умный фильтр для больших геномных данных. Он помогает отделять истинные связанные с заболеванием гены от статистического шума, даже когда данные ограничены и гены сильно взаимосвязаны. Предоставляя более точные и более стабильные списки генов и оценки эффектов, метод может сузить поиск биомаркеров, мишеней для лекарств и прогностических сигнатур в онкологии и других сложных заболеваниях. Хотя демонстрация выполнена на линейной регрессии, та же схема может быть встроена в модели выживаемости и задачи классификации, расширяя потенциальное влияние в биомедицинских исследованиях.
Цитирование: Baek, B., Jo, J., Kang, M. et al. Stochastic LASSO for extremely high-dimensional genomic data. Sci Rep 16, 5250 (2026). https://doi.org/10.1038/s41598-026-35273-3
Ключевые слова: отбор геномных признаков, высокоразмерные данные, методы LASSO, экспрессия генов при раке, поиск биомаркеров