Clear Sky Science · ru
Оценка точности ядерных данных, полученных машинным обучением, в полном модельном расчёте нейтронной физики реактора методом Монте-Карло и анализе вычислительной эффективности
Почему важны более быстрые расчёты реакторов
Атомные электростанции опираются на детальные компьютерные модели, которые предсказывают поведение топлива в течение месяцев и лет эксплуатации. Эти модели критичны для безопасности, эффективности и проектирования новых реакторов, но они печально известны своей медлительностью и высоким потреблением памяти. В этой статье исследуется, может ли машинное обучение сократить огромные таблицы ядерных данных, которые управляют этими расчётами — существенно снизив вычислительные затраты — без потери физической точности, от которой зависят инженеры.
Уменьшение данных, лежащих в основе физики
Каждый раз, когда смоделированный нейтрон проходит через виртуальное ядро реактора, код обращается к крупным таблицам, описывающим вероятности рассеяния, поглощения или деления атома. Эти таблицы, называемые библиотеками ядерных данных, кодируют вероятности на тысячах энергетических точек для многих изотопов в топливе и его продуктах распада. Авторы опираются на ранее предложенный метод машинного обучения, который «уплотняет» эти таблицы: он удаляет избыточные энергетические точки, сохраняя при этом острые особенности, такие как пороги реакций и резонансные пики, где вероятности быстро меняются. Вместо регенерации данных через долгую традиционную цепочку обработки метод редактирует родные файлы OpenMC в формате HDF5 напрямую, оставляя лишь около 10–50% исходных узлов сетки для 23 особенно важных нуклидов.
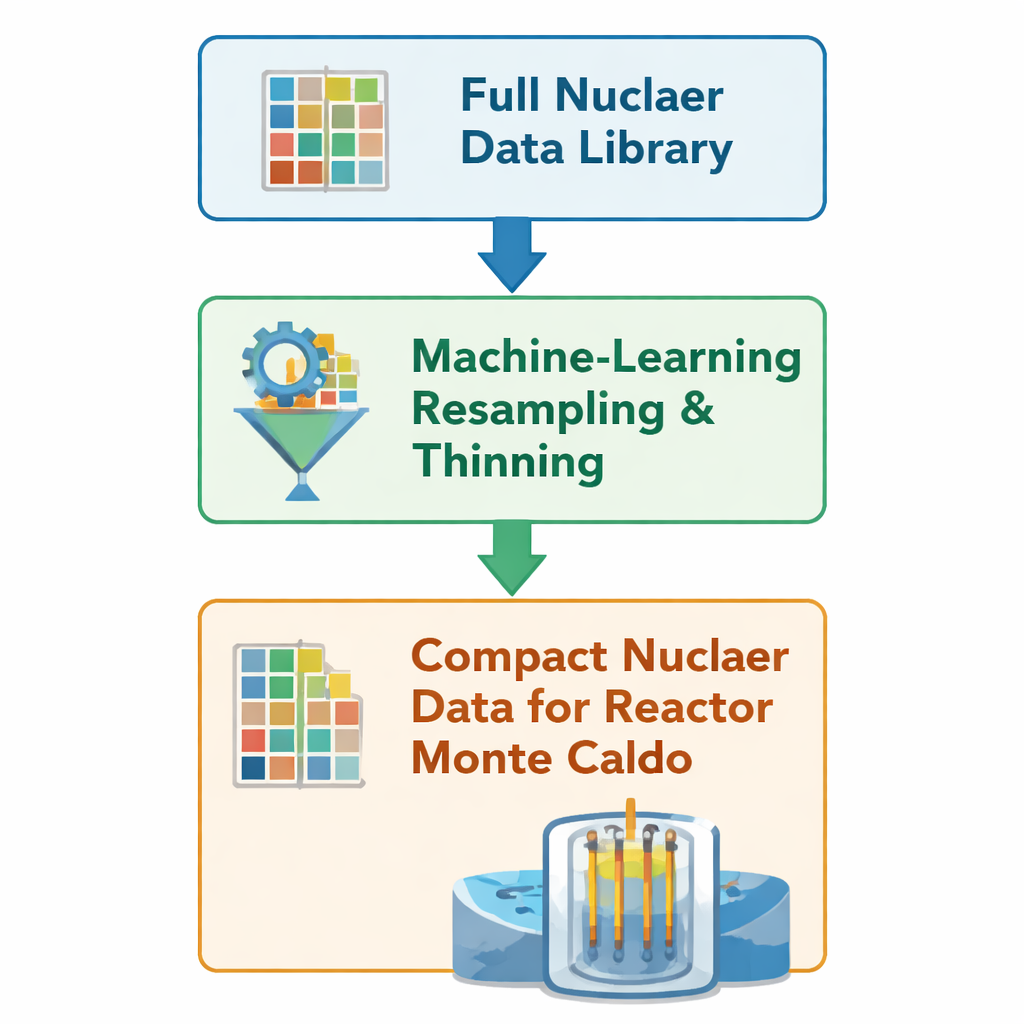
Проверка идеи на полноразмерных сердечниках
Чтобы выяснить, сохраняют ли такие сокращённые данные достоверность в реалистичных условиях, команда запускает годовые симуляции двух больших реакторов с герметичным водоохлаждением: European Pressurized Reactor (EPR) и VVER‑1000, используя открытый Монте‑Карло код OpenMC. Для каждого сердечника они проводят две в остальном идентичные кампании: одну с полной библиотекой ядерных данных и одну с версией, уменьшенной машинным методом. Вся геометрия, режимы работы и численные настройки остаются фиксированными; различаются только таблицы данных, лежащие в основе физики. Они отключают другие ускоряющие функции внутри OpenMC, чтобы любое изменение скорости или использования памяти можно было однозначно связать с уменьшением данных, а не с изменением алгоритмов или настроек.
Ускорение с жёсткими границами погрешности
Результат значителен. В случае EPR общее реальное время выполнения сокращается примерно на 18%, а для VVER‑1000 время выполнения уменьшается примерно на 43%. Изменения в использовании памяти более скромны: пик использования падает примерно на 4% в EPR и увеличивается примерно на 5% в VVER‑1000, что отражает различия в том, сколько времени каждая модель тратит на обращения к ядерным данным по сравнению с трассировкой частиц через геометрию. Существенно то, что ключевые показатели на уровне реактора остаются очень близки к исходным. В течение полного года в VVER‑1000 эффективный множитель размножения — по сути, среднее число нейтронов, производимых одним делением — не отклоняется более чем примерно на 100 частей на миллион, и обычно лишь на несколько десятков частей на миллион. Для ключевых каналов реакций, таких как деление в уране‑235 и уране‑238 и захват нейтронов в ксеноне‑135 и самарии‑149, средние различия остаются значительно ниже одной десятой процента.
Эволюция топлива и отравляющих примесей остаются под контролем
Поскольку поведение реактора в долгосрочной перспективе зависит не только от мгновенных реакций, но и от того, как накапливаются и выгорают топливо и продукты деления, авторы также отслеживают изменяющиеся запасы важных изотопов. Они рассматривают основные изотопы урана, семейство плутониевых изотопов, выращенных из урана‑238, и сильные «отравляющие» нуклиды, поглощающие нейтроны, особенно ксенон‑135 и самарий‑149. Даже после полного года различия в этих запасах между случаями с полной и сокращённой базой данных остаются крошечными: порядка нескольких сотых процента для ксенона и самария и обычно ниже одной десятой процента для видов плутония. Уран‑235 и уран‑238, которые доминируют в производстве энергии и нейтронном балансе сердечника, воспроизводятся с точностью значительно лучше одной сотой процента. Там, где относительные ошибки кратко превышают один процент для некоторых изотопов плутония, это происходит в начале цикла, когда их абсолютные количества ещё крайне малы, поэтому практический эффект на поведение реактора незначителен.
Что это значит для будущего моделирования реакторов
Для неспециалистов основное послание таково: тщательно обученная процедура машинного обучения может сделать ядерные «таблицы поиска» внутри продвинутых симуляций реакторов значительно меньшими и быстрыми в использовании, при этом поведение моделируемого реактора остаётся практически неотличимым от традиционного подхода. Исследование демонстрирует это для двух промышленных сердечников в течение полного года эксплуатации, с погрешностями, малыми по сравнению с другими типичными неопределённостями в анализе реакторов. Авторы подчёркивают, что их выводы в настоящее время применимы к стационарным водо‑водяным реакторам с давлением при использовании конкретной библиотеки данных и настроек кода, и что необходимы дополнительные исследования для проверки других типов реакторов и нестационарных условий. Тем не менее результаты указывают на многообещающий путь к более быстрым и эффективным высокоточным ядерным симуляциям, позволяя проводить больше проектных и оценочных анализов с ограниченными вычислительными ресурсами.
Цитирование: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Ключевые слова: моделирование ядерного реактора, машинное обучение, нейтронная физика методом Монте-Карло, библиотеки ядерных данных, водо-водяные реакторы с давлением