Clear Sky Science · ru
Эффективное обнаружение научных аннотаций, сгенерированных ИИ, с помощью лёгкого трансформера
Почему важно распознавать тексты, написанные ИИ
По мере того как искусственный интеллект становится всё более искусным в письме, он теперь способен создавать научные резюме, которые почти неотличимы от текстов, написанных людьми. Это порождает серьёзные вопросы: как журналы, университеты и читатели могут быть уверены, что аннотация действительно отражает работу учёного, а не вымысел машины? В этой статье решается эта проблема путём создания быстрого компактного инструмента, способного с высокой надёжностью отмечать аннотации, созданные ИИ, предлагая практическую защиту академической честности.
Создание тестовой базы реальных и синтетических аннотаций
Чтобы измерить и улучшить обнаружение текста ИИ, авторам сначала нужны были надёжные данные. Они собрали 5000 научных аннотаций с сервера препринтов arXiv, охватив пять областей: компьютерное зрение, обработка сигналов, количественная биология, физика и другие темы в информатике. Для каждой аннотации, написанной человеком, они сгенерировали вариант при помощи крупной языковой модели, тщательно проверяя наличие почти идентичных текстов и удаляя очевидные подсказки, такие как веб-адреса или фрагменты кода. Также они обеспечили сопоставимую длину текстов ИИ и людей, чтобы детектор не мог полагаться только на грубые статистики вроде числа слов.
Компактная модель, настроенная для реального мира
Вместо использования огромной и дорогой модели исследователи выбрали более лёгкую систему, известную как DistilBERT, упрощённую версию популярной языковой модели. Они дообучили её принимать решение для каждой аннотации: написана ли она человеком или сгенерирована ИИ. Модель анализирует до 256 токенов — примерно несколько абзацев — и выдаёт оценку от нуля до единицы, интерпретируемую как вероятность машинной генерации. Обучение и оценка следовали строгому протоколу: данные были разделены на обучающую, валидационную и тестовую выборки без пересечений, и команда сообщала не только точность, но и поведение модели в условиях очень низкого допустимого уровня ложных срабатываний — режим, важный при обвинениях реальных авторов в использовании ИИ.
Как детектор показывает себя на практике
На аннотациях по компьютерному зрению, основной тестовой базе, детектор оказался исключительно точным. Он правильно пометил 499 из 500 текстов, сгенерированных ИИ, и 495 из 500 человеческих текстов, достигнув примерно 99,4% точности и почти идеального результата на стандартной кривой производительности. Когда авторы потребовали, чтобы система допускала не более одного ложного обвинения в ста случаях, она всё равно обнаруживала около 90% текстов ИИ; при чуть большей допустимости — пяти ложных срабатываний на сто — выявлялось около 97%. В сравнении с различными альтернативами — включая простые статистические инструменты и другие трансформеры — компактный детектор стабильно показывал лучшие результаты, особенно в более жёстких сценариях.
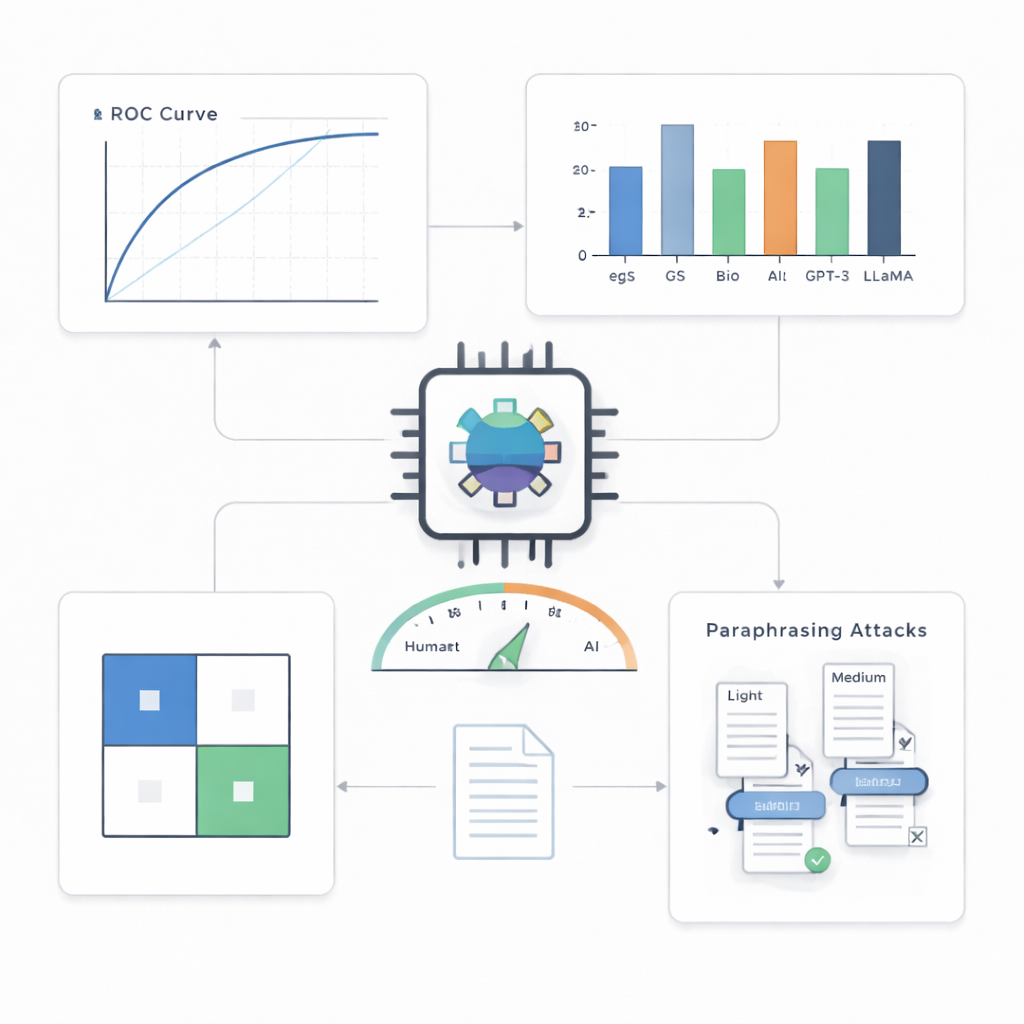
За пределами одной области, одной модели и простых приёмов
Ключевой вопрос — справится ли такой детектор со стилями письма и ИИ-системами, которых он раньше не видел. Авторы протестировали его на аннотациях из других научных областей и на текстах, созданных несколькими различными современными языковыми моделями. По всем доменам производительность оставалась высокой, с лишь умеренным спадом, что предполагает: система захватывает общие шаблоны письменных текстов ИИ, а не только особенности одной предметной области. Против невидимых моделей ИИ детектор также работал хорошо, хотя и не так идеально, как в своей «домашней» среде. Самым сложным испытанием стали атаки с перефразированием: когда другой ИИ переписывал машинно сгенерированные аннотации, чтобы они звучали иначе при сохранении смысла, обнаружение становилось заметно труднее. При средней силе переписывания доля проскальзывающих ИИ-текстов выросла почти до 30%, показывая, что даже совершенные детекторы можно обмануть при целенаправленном запутывании.
Что это значит для науки и её механизмов защиты
Исследование показывает, что на данный момент в научных аннотациях, созданных ИИ, всё ещё остаются тонкие следы, которые может уловить грамотно спроектированная модель, даже если она достаточно мала, чтобы работать на скромном оборудовании. Это делает возможным для издателей, конференций и университетов проверять большие объёмы подаваемых материалов без огромных вычислительных затрат. В то же время уязвимость к перефразированию подчёркивает, что такие инструменты не являются панацеей. Авторы утверждают, что обнаружение текста ИИ следует сочетать с другими мерами — такими как редакционная экспертиза, проверки на плагиат и требования прозрачности — чтобы защищать надёжность научной коммуникации по мере совершенствования ИИ-систем.
Цитирование: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Ключевые слова: обнаружение текста ИИ, научные аннотации, академическая честность, крупные языковые модели, машинно-сгенерированный текст