Clear Sky Science · ru
Превосходство инженерии признаков над архитектурной сложностью при прогнозировании прерывистого спроса
Почему важно предсказывать редкие продажи
За каждым автосервисом или складом запчастей скрывается тихая задача: сколько медленно продающихся запасных частей держать на полке? Эти позиции продаются редко и непредсказуемо, но должны быть доступными, когда ломается автомобиль. Перезаказ ведёт к замораживанию денег в пылящихся запасах; недозаказ — к ожиданию клиентов и срочным поставкам. Эта статья рассматривает эту повседневную, но дорогостоящую проблему и задаёт простой вопрос: лучше ли использовать всё более сложные модели предсказания или давать существующим моделям более умные, специально сконструированные сигналы из данных?
От долгих периодов без спроса до внезапных всплесков
Во многих цепочках поставок, особенно для автомобильных запасных частей, спрос не равномерен, как на молоко или хлеб. Вместо этого бывают долгие периоды по несколько месяцев с нулевыми продажами, прерываемые внезапными заказами на несколько единиц. Авторы проанализировали более 56 000 комбинаций дилер–деталь, охватывающих около 1,4 миллиона ежемесячных записей, и обнаружили, что большинство рядов крайне разрежены: в среднем на каждый месяц с продажей приходится много нулевых месяцев, а объёмы заказов сильно колеблются. Традиционные статистические методы, такие как подход Кростона и его доработки, создавались для такого «вкл-выкл» спроса и дают стабильные, интерпретируемые прогнозы, но они рассматривают каждую деталь отдельно и не могут легко использовать дополнительную информацию, например цены или характеристики продукта. Современные системы машинного обучения по идее способны использовать все эти данные, но им часто трудно работать, когда данные преимущественно заполнены нулями и только изредка содержат информативные события.
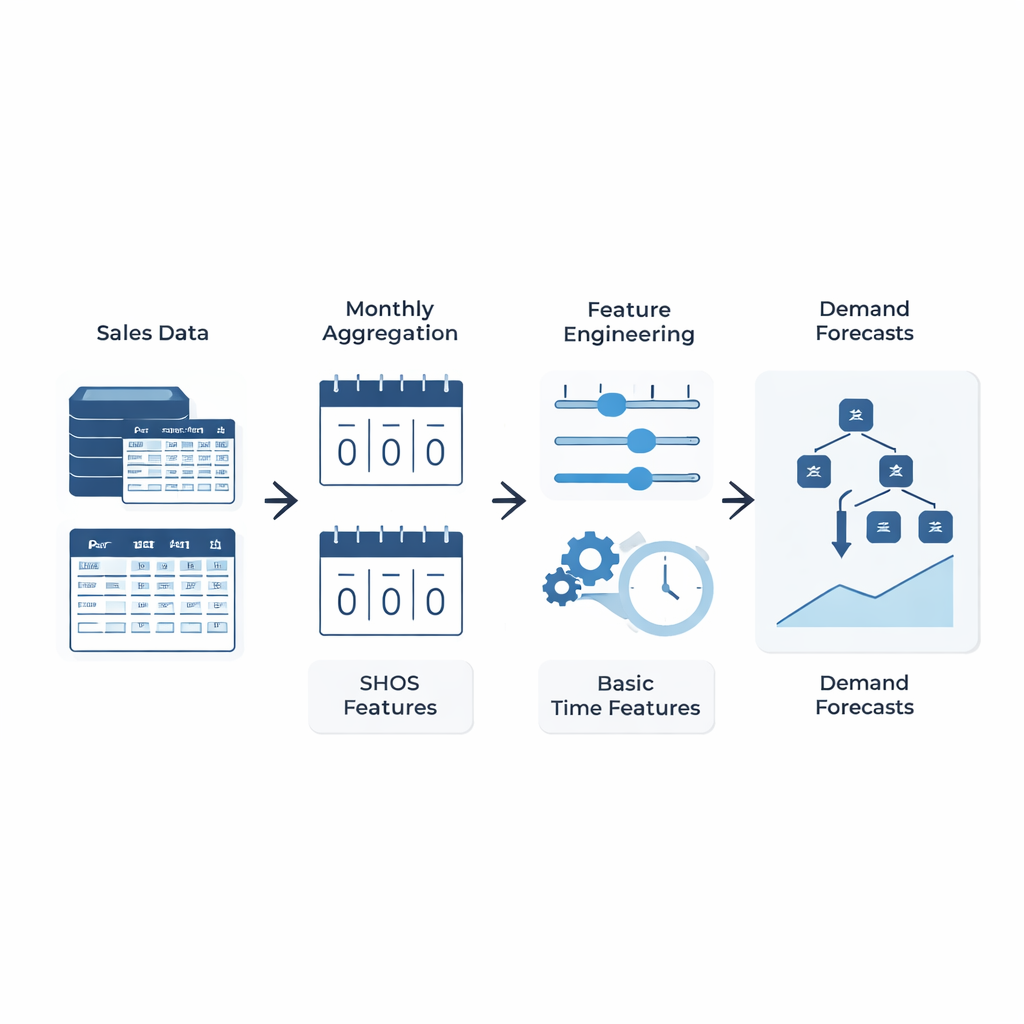
Простая идея: научить модель тому, что действительно важно
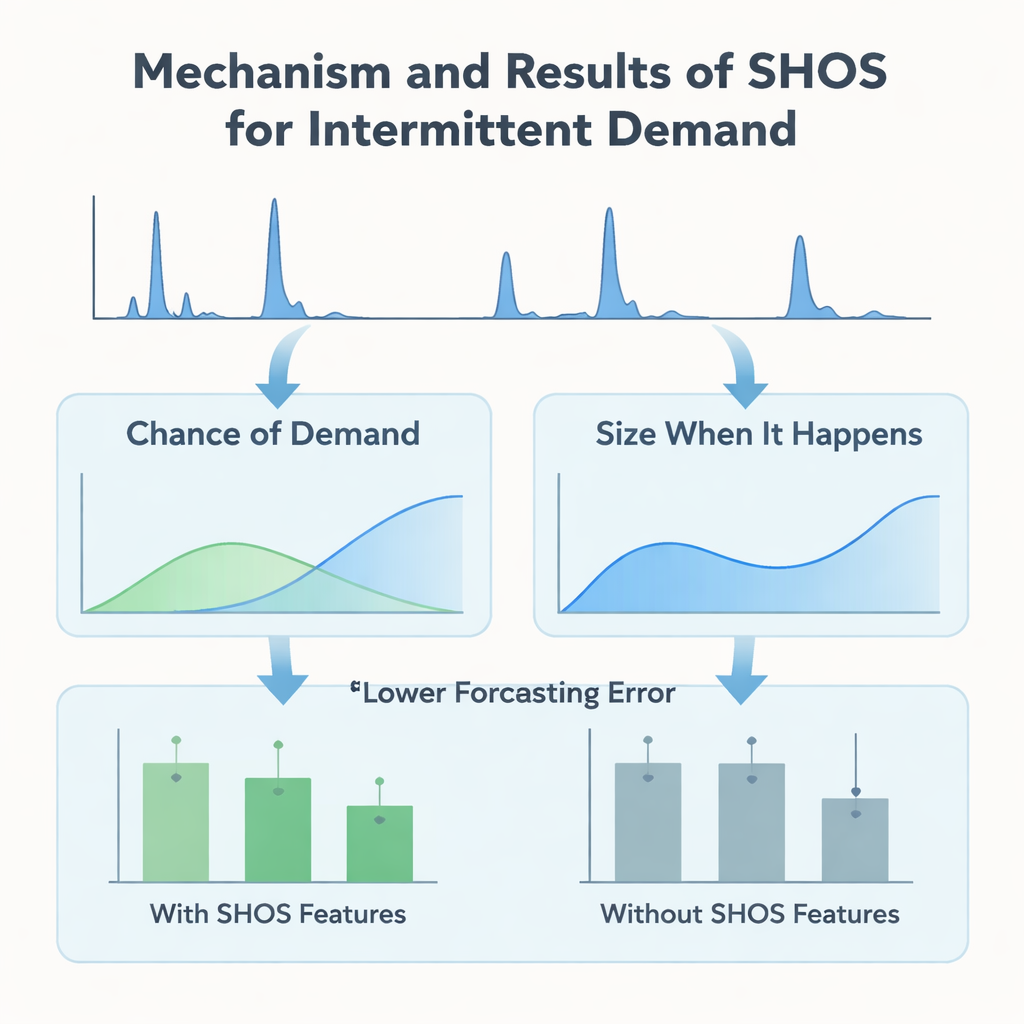
Вместо разработки всё более сложных архитектур машинного обучения авторы сосредотачиваются на том, что подаётся на вход модели. Они предлагают структуру Smoothed Hybrid Occurrence–Size (SHOS) — лёгкую статистическую процедуру, которая выполняется для каждой истории спроса. На каждом шаге (месяце) SHOS выдаёт два числа: оценённую вероятность того, что в следующем месяце будет какой‑то спрос, и типичный размер этого спроса, если он произойдёт. Это достигается аккуратным сглаживанием прошлых нулей и ненулей, адаптацией поведения для очень разреженных рядов и более быстрой реакцией, когда спрос внезапно возвращается после долгого затишья. Важно, что SHOS не является финальной моделью прогнозирования. Его выходы становятся дополнительными входными признаками для стандартных алгоритмов машинного обучения, наряду с простыми показателями, такими как недавние продажи, скользящие средние и статические характеристики продукта.
Поставить качество признаков выше сложности модели
Чтобы проверить, действительно ли такое статистическое «предобрабатывание» помогает, исследователи провели контролируемый эксперимент. Они сравнили ряд популярных моделей — градиентный бустинг деревьев, случайные леса и линейные методы — с SHOS‑признаками и без них, все обучались на одной и той же месячной панели с заполнением нулями и оценивались с помощью строгой скользящей схемы, имитирующей реальное развёртывание. Они также проверили более сложные двухэтапные «hurdle»‑модели, отдельно предсказывающие, появится ли спрос, и каким он будет по величине. По результатам 11 валидационных окон добавление SHOS‑признаков почти вдвое уменьшает среднюю ошибку прогнозирования для сильно прерывистых товаров и снижает ключевую бизнес‑метрику — взвешенную среднюю абсолютную процентную ошибку — более чем на 40%. Удивительно, но двухэтапные архитектуры, несмотря на большую сложность и адаптацию под такой тип данных, не превосходят простой одномодельный регрессор, который просто принимает на вход сигналы SHOS.
Как модель принимает свои решения
Команда пошла дальше общей точности и изучила, как модели фактически используют предоставленную информацию. С помощью SHAP, стандартного инструмента для интерпретации предсказаний машинного обучения, они показали, что SHOS‑признаки — «вероятность спроса» и «размер при появлении» — постоянно входят в число наиболее влиятельных входов. В длительные периоды нулевого спроса низкая вероятность по SHOS сдвигает прогнозы к нулю, предотвращая ложное накопление запасов. Когда после засухи появляется всплеск спроса, коррекция по недавним событиям в SHOS быстро повышает оценки вероятности и размера, позволяя модели реагировать, не перегибая из‑за единичного пика. Такое поведение наблюдается как в простой одномодульной модели, так и в более сложных hurdle‑вариантах, подчёркивая, что основной выигрыш даёт качество сигналов, а не архитектурные хитрости.
Что это значит для повседневных решений по запасам
Для практиков, стремящихся держать нужные запчасти на полке, посыл одновременно практичен и обнадёживает. Исследование показывает, что тщательно спроектированные, статистически обоснованные признаки могут дать значительные улучшения в прогнозировании редких, нерегулярных продаж без обращения к хрупким и трудным в обслуживании схемам моделей. Скромное, хорошо настроенное дерево градиентного бустинга с SHOS‑признаками обгоняет или не уступает более сложным конвейерам и при этом остаётся проще в развёртывании и мониторинге на десятках тысяч позиций. Проще говоря, подача вашей системе прогнозирования лучших сводок о том, как часто и в каком объёме клиенты, вероятно, будут заказывать, может быть важнее, чем переход на самый новый и сложный алгоритм. Такое внимание к простым интерпретируемым строительным блокам делает подход привлекательным для крупных реальных цепочек поставок и указывает на то, что аналогичные стратегии, ориентированные на признаки, могут окупиться в других отраслях с прерывистым спросом.
Цитирование: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Ключевые слова: прерывистый спрос, прогнозирование запасных частей, инженерия признаков, аналитика цепочки поставок, машинное обучение