Clear Sky Science · ru
Мультимодальный подход к обучению и моделированию для восприятия в системах автономного вождения
Более умные автомобили без водителя
Автомобили без водителя обещают более безопасные дороги и меньшие пробки, но только если они действительно смогут понимать окружающий мир. В этой работе исследуется новый способ помочь автономным транспортным средствам «видеть», «ощущать» и «предвидеть» окружающую обстановку ближе к тому, как это делает внимательный человек — за счёт комбинирования разных датчиков, безопасного тестирования в виртуальной копии реального мира и повышения прозрачности решений машины для людей.
Видеть дорогу многими «чувствами»
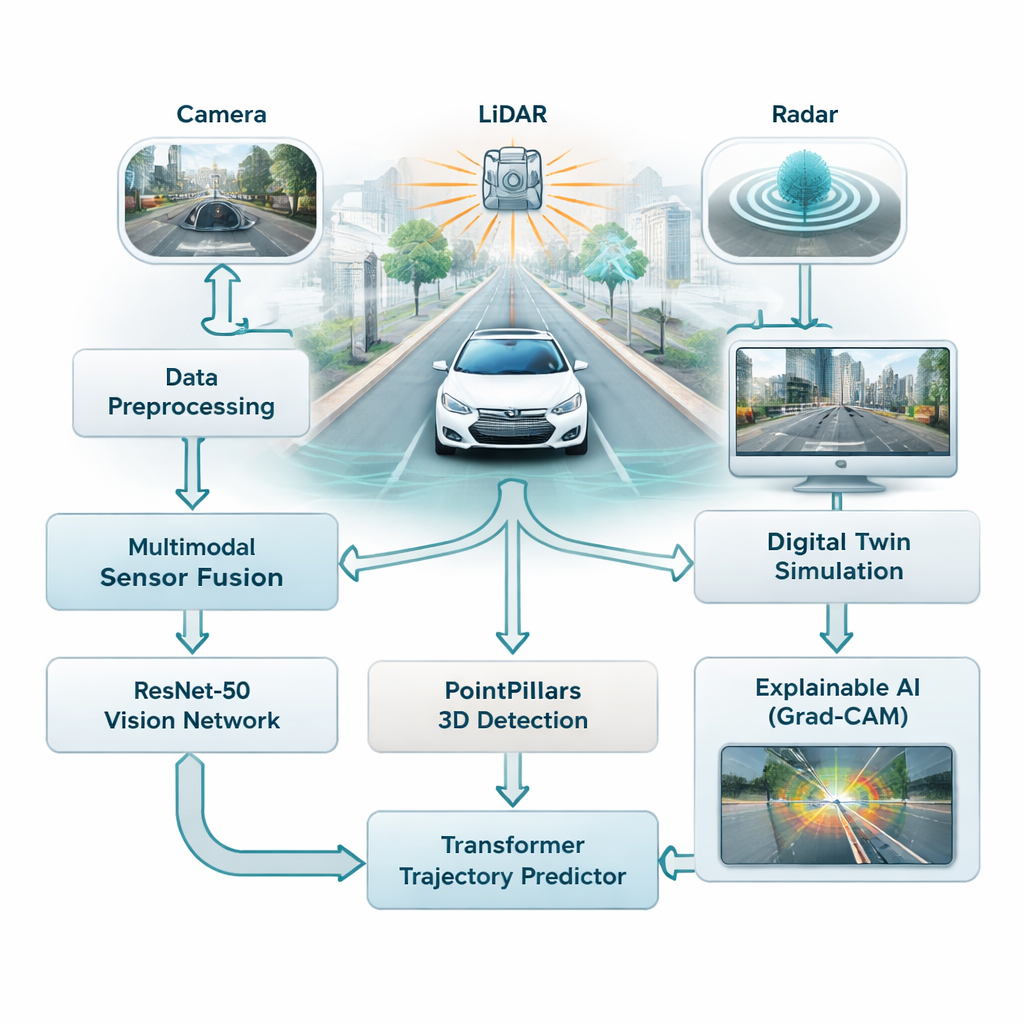
Большая часть современных систем помощи водителю опирается преимущественно на камеры, которые хорошо работают при хорошем освещении, но испытывают трудности в тумане, дожде или ночью. В исследовании объединяются три типа датчиков — камеры, лазерные сканеры (LiDAR) и радар — чтобы автомобиль не зависел от одного хрупкого источника информации. Камеры фиксируют богатую цветовую и детальную информацию, LiDAR строит точную 3D-картину сцены, а радар остаётся надёжным в плохую погоду. Авторы объединяют все три потока в единое представление дорожной обстановки, давая транспортному средству более полное и надёжное понимание дорог, пешеходов и других автомобилей.
Обучение автомобиля распознавать и предвидеть
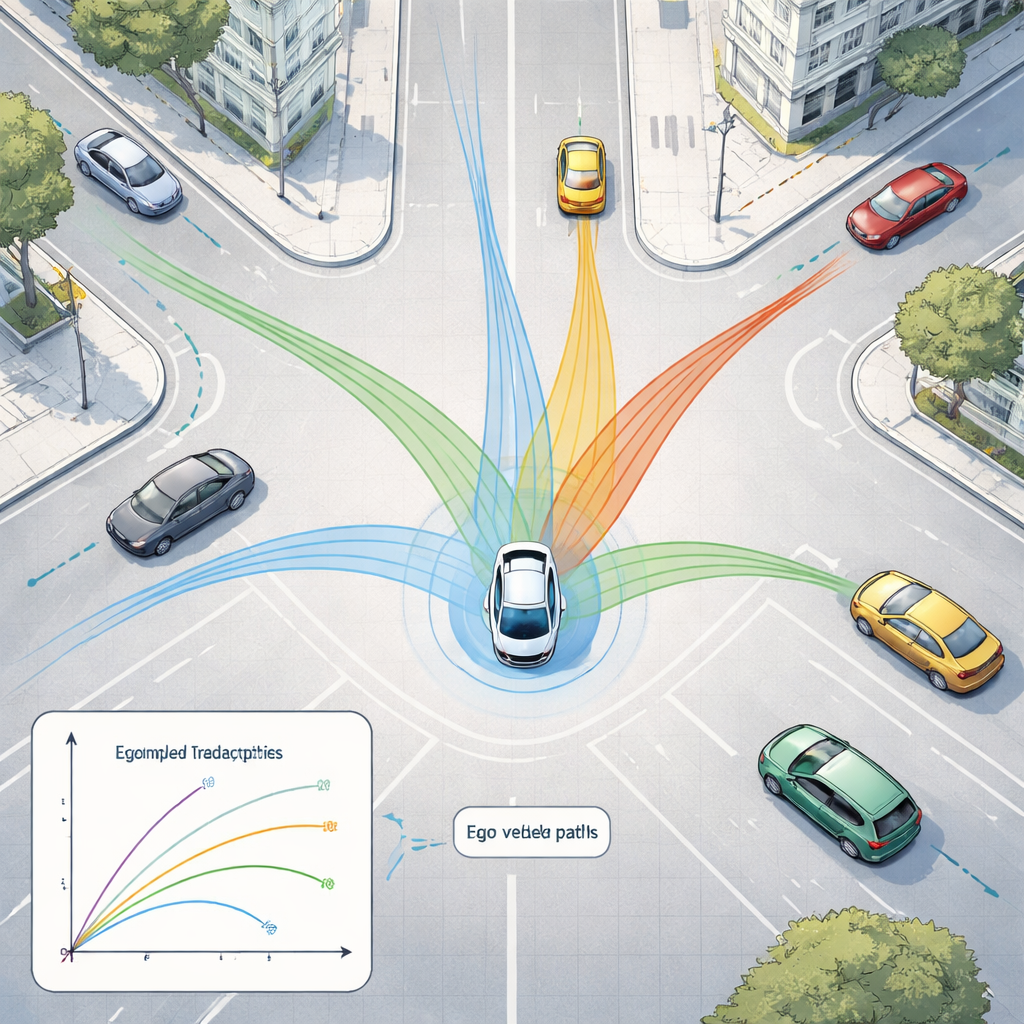
Чтобы осмыслить этот поток данных, в рамках используется два семейства современных моделей ИИ. Во‑первых, глубокая сверточная сеть ResNet-50 анализирует изображения с камер, чтобы уловить общую ситуацию — насколько загружена дорога, где видны полосы и как устроена сцена. Одновременно 3D-модель PointPillars обрабатывает облака точек LiDAR, определяя автомобили и другие объекты в трёх измерениях. Эти сигналы затем подаются в Transformer — тип модели, изначально разработанный для языка, который хорошо понимает, как вещи меняются во времени. Здесь он обучается предсказывать, как близлежащие автомобили и другие движущиеся объекты, вероятно, будут перемещаться в ближайшие несколько секунд, учитывая их прошлую динамику и структуру дороги.
Построение безопасного виртуального полигона
Вместо тестирования опасных сценариев прямо на публичных дорогах исследователи подключают систему к цифровому двойнику — виртуальной копии реальных городских улиц на основе крупного публичного набора данных из Бостона и Сингапура. В этом смоделированном мире датчики автомобиля, его движение и окружение воспроизводятся и могут изменяться по желанию, пока ИИ пытается отслеживать объекты и прогнозировать их будущие траектории. Система может прогонять такие сценарии «что если?» в реальном времени с времем отклика меньше 50 миллисекунд, что позволяет инженерам исследовать крайние случаи — внезапное торможение, резкие манёвры или переполненные перекрёстки — без риска для людей.
Взгляд внутрь «чёрного ящика» ИИ
Один из частых упрёков к глубокому обучению — трудность понять, почему модель приняла то или иное решение. Для решения этой проблемы авторы используют метод Grad-CAM, который подчёркивает части изображения, наиболее повлиявшие на вывод модели. Эти тепловые карты показывают, например, фокусируется ли сеть на другом автомобиле, пешеходе или дорожной разметке при оценке траекторий. Хотя этот этап объяснения выполняется офлайн, а не в реальном временном цикле автомобиля, он помогает инженерам и специалистам по безопасности проверить, что система обращает внимание на правильные подсказки, что важно для формирования общественного доверия.
Насколько лучше она водит?
При тестировании на сотнях городских сцен предложенная архитектура точно обнаруживает 3D-объекты и более точно предсказывает движение по сравнению с простыми физическими моделями, предполагающими постоянную скорость или равномерное ускорение. Ошибки прогноза — насколько предсказанные позиции отклоняются от реальных — существенно меньше, чем у таких базовых моделей, и близки к сильной рекуррентной модели ИИ, при этом система работает достаточно быстро для использования в реальном времени. Тщательные эксперименты с разными архитектурами сетей показывают, что более глубокая модель изображений и среднеглубокий 3D-детектор обеспечивают наилучший баланс между точностью и скоростью, а после сжатия модели систему можно развернуть и на меньших бортовых вычислителях.
Что это значит для обычных водителей
Для неспециалистов суть в том, что более безопасные и надёжные автомобили без водителя скорее всего появятся благодаря подходу, который сочетает несколько датчиков, прогнозирует развитие сцены и тщательно тестируется в реалистичных виртуальных мирах. Объединяя восприятие, прогнозирование, моделирование и понятные человеку объяснения в одном решении, эта работа приближает автономные транспортные средства к поведению осторожных, прозрачных партнёров на дороге, а не к таинственным машинам.
Цитирование: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Ключевые слова: автономное вождение, слияние датчиков, прогнозирование траекторий, 3D-обнаружение объектов, моделирование цифрового двойника