Clear Sky Science · ru
Гибридный отбор признаков с новой моделью глубокого обучения для прогнозирования риска COVID-19
Почему прогнозирование риска COVID-19 по-прежнему важно
Даже по мере того как мир учится жить с COVID-19, вирус не исчез. Появляются новые варианты, больницы все еще могут испытывать нагрузку, а у уязвимых людей сохраняется более высокий риск тяжелого течения болезни или смерти. Врачам поэтому нужны быстрые и надежные способы оценить, насколько вероятно, что инфицированный пациент серьезно заболеет. В этой работе представлена новая компьютерная модель, которая использует данные больницы и современные методы искусственного интеллекта для более точного прогнозирования риска COVID-19, что потенциально помогает клиницистам решать, кому нужно более пристальное наблюдение, раннее лечение или интенсивная терапия.
От необработанных медицинских записей к пригодным сигналам
Исследование начинается с очень большого клинического набора данных: более миллиона анонимных пациентов, каждый из которых описан 21 простым, в основном да/нет признаком, такими как возрастная группа, сопутствующие заболевания и другие факторы риска. Данные из реальной клиники бывают шумными, поэтому первым шагом является их «очистка». Авторы применяют математический прием — логарифмическое масштабирование, которое сжимает экстремальные значения и растягивает скопления очень маленьких чисел. Это преобразование делает данные более устойчивыми и удобными для алгоритмов, снижая риск того, что необычные числа или разреженные индикаторы введут модель в заблуждение.
Выбор наиболее показательных признаков
Не каждая зарегистрированная переменная одинаково полезна для прогнозирования, и слишком большое количество слабых сигналов может запутать систему ИИ. Поэтому исследователи выполняют отбор признаков — процесс, отфильтровывающий менее полезную информацию и сохраняющий наиболее информативные факторы. Их гибридный подход сочетает две идеи: одна метрика оценивает, насколько хорошо признак разделяет пациентов с высоким и низким риском, другая проверяет, насколько сильно признаки перекрываются между собой. Согласуя эти две точки зрения на общей шкале, метод отдает приоритет признакам, которые одновременно мощны и не избыточны. Такая оптимизация ускоряет обучение, уменьшает переобучение и сосредотачивает модель на наиболее клинически релевантных закономерностях.
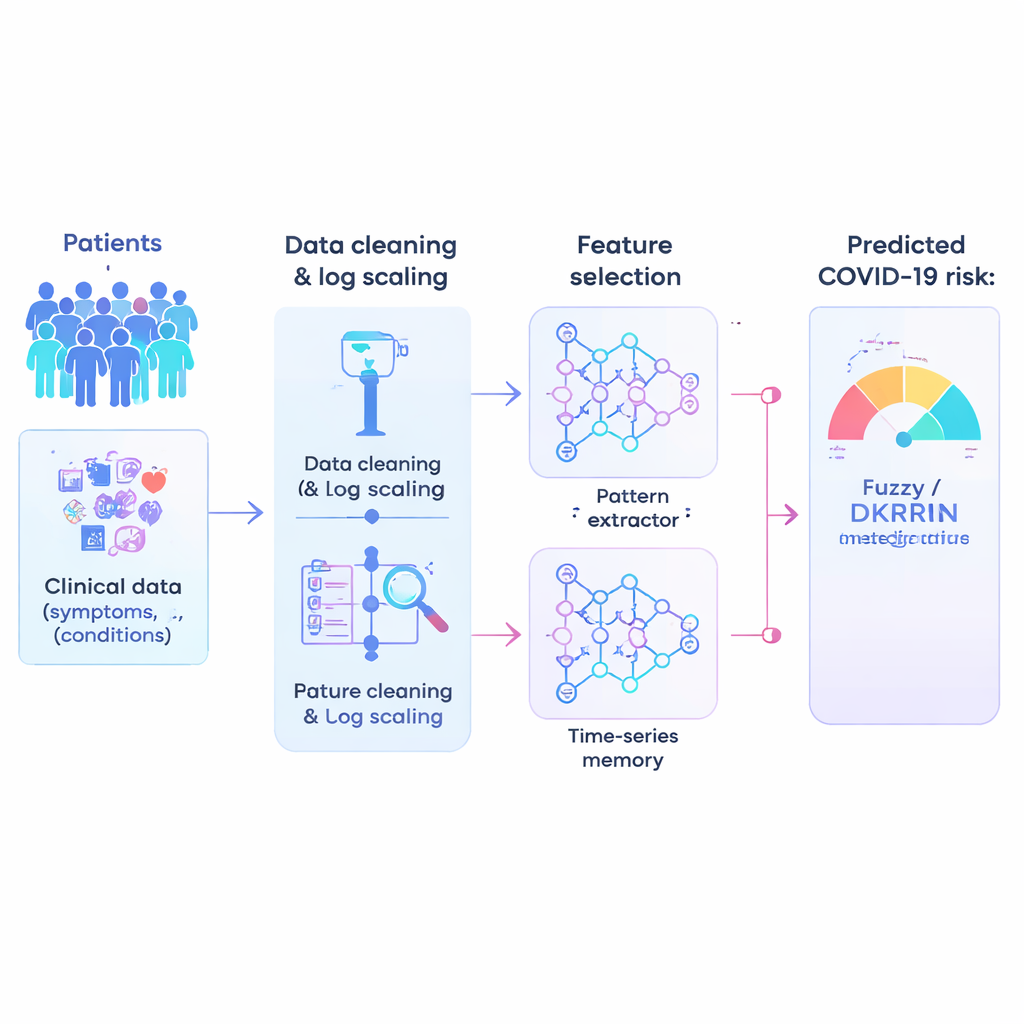
Сочетание распознавания шаблонов и нечеткого рассуждения
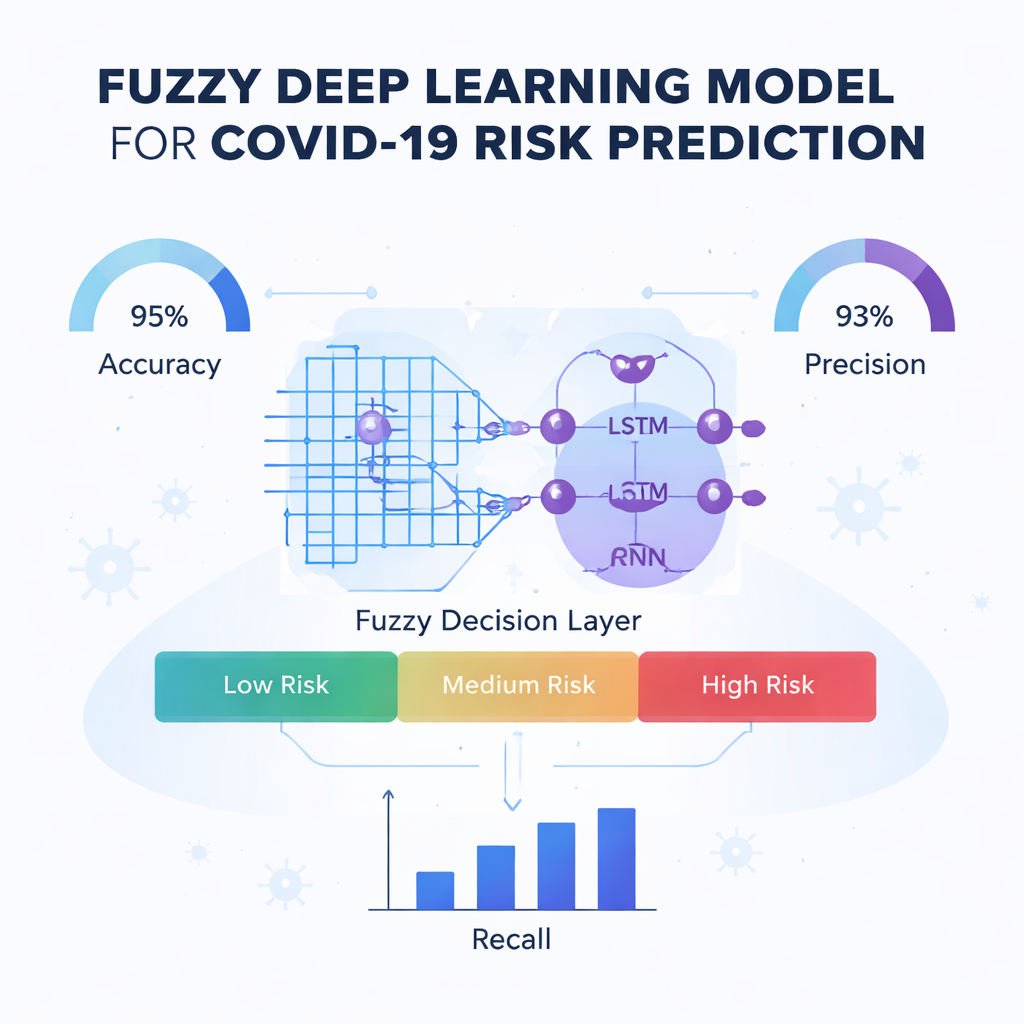
Ядром работы является новый предсказательный движок под названием Fuzzy-Deep Kronecker Recurrent Neural Network, или Fuzzy-DKRNN. Он объединяет несколько дополняющих друг друга техник. Один компонент, Deep Kronecker Network, создан для выявления компактных, структурированных шаблонов, скрытых в клинических данных. Другой компонент, глубокая рекуррентная сеть, хорошо подходит для захвата зависимостей и трендов, например когда комбинация факторов во времени влияет на риск. Поверх этого авторы накладывают систему нечеткой логики. Вместо жестких да/нет решений нечеткие правила выражают утверждения типа «если несколько индикаторов риска умеренно высоки, пациент, вероятно, относится к группе высокого риска». Каждое правило несет степень уверенности, что позволяет модели работать с неопределенностью и серыми зонами, характерными для медицины.
Насколько хорошо работает модель?
Авторы тщательно тестируют свою модель Fuzzy-DKRNN в сравнении с несколькими современными альтернативами, включая системы на основе рентгеновских снимков грудной клетки, традиционные методы машинного обучения и другие подходы глубокого обучения. Используя стандартные метрики, такие как точность, точность положительных прогнозов (precision), полнота (recall) и F1‑меру, их метод стабильно показывает лучшие результаты. В своей наилучшей конфигурации модель правильно классифицирует примерно 91% случаев в целом, демонстрируя высокую способность как выявлять пациентов, которые станут тяжело больными, так и избегать лишних тревог у тех, кто этого не сделает. Эти преимущества сохраняются при изменении объема тренировочных данных и внутренних настроек проверки, что говорит о том, что подход устойчив, а не тонко подогнан под одну конкретную ситуацию.
Что это означает для пациентов и больниц
Проще говоря, эта работа показывает, что сочетание тщательной предобработки данных, грамотного выбора ключевых факторов риска и гибрида глубокого обучения с нечеткой логикой может дать более надежные прогнозы риска COVID-19 на основе рутинной клинической информации. Такой инструмент не заменит врачей, но может служить системой раннего предупреждения — выделяя пациентов, требующих более пристального наблюдения, помогая распределять дефицитные ресурсы, такие как места в реанимации, и в конечном счете способствуя снижению предотвратимой смертности. Та же стратегия может быть адаптирована и к другим заболеваниям, где раннее выявление риска на основе сложных клинических данных имеет решающее значение.
Цитирование: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Ключевые слова: прогнозирование риска COVID-19, глубокое обучение, нечеткая логика, система поддержки клинических решений, медицинские ИИ-модели