Clear Sky Science · ru
Вычисление оценки схожести предложений с помощью гибридного глубокого обучения с особым вниманием к предложениям с отрицанием
Почему значение слова важно для справедливого оценивания
Когда студенты отвечают своими словами, компьютеры, помогающие преподавателям оценивать эти ответы, должны понимать не только совпадающие ключевые слова. Небольшое слово вроде «не» может полностью изменить смысл предложения, и если автоматические системы не замечают этого изменения, студенты могут получить несправедливую оценку. В этой статье решается эта проблема: предложен новый способ для компьютеров сравнивать значения предложений с особым вниманием к тому, как слова отрицания меняют сказанное.
Проблема маленьких слов с большим воздействием
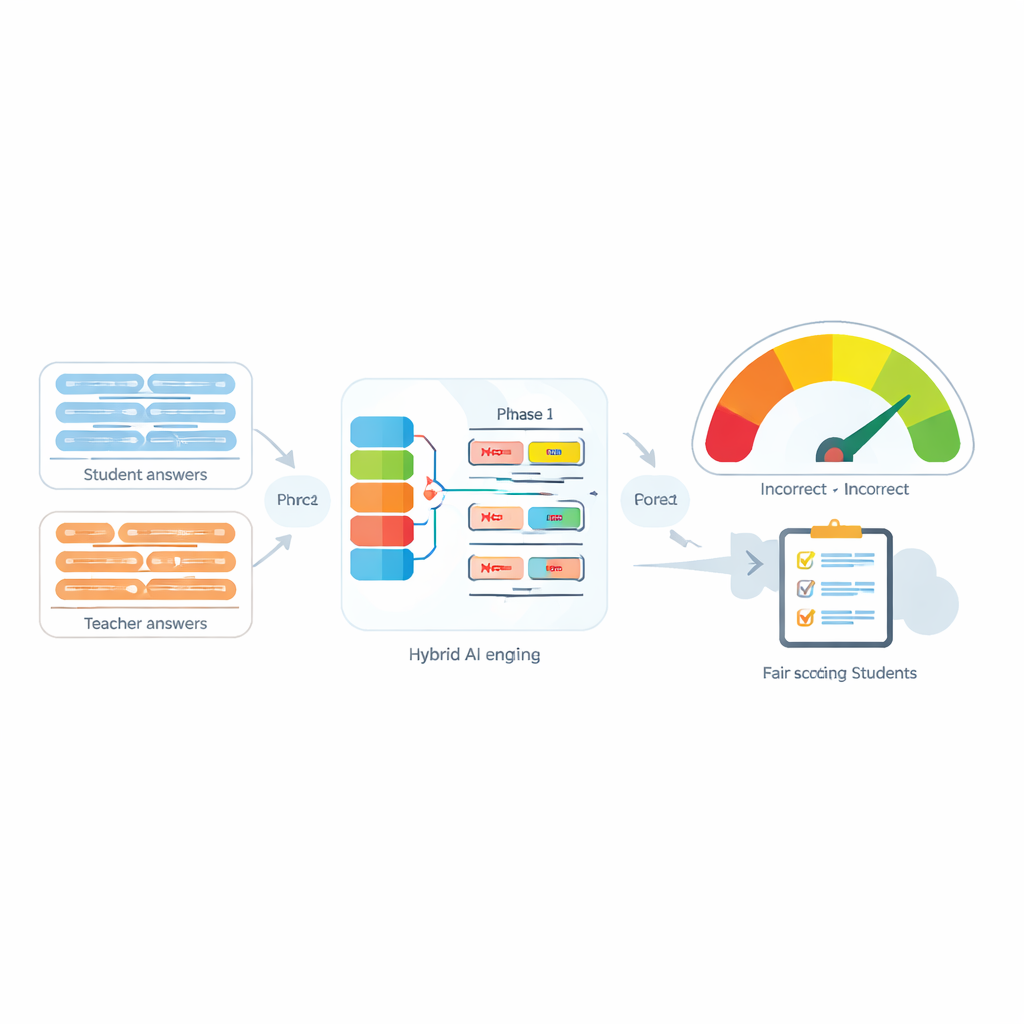
Системы автоматической оценки всё чаще применяются, чтобы снизить нагрузку на преподавателей, сравнивая ответ студента с эталонным ответом преподавателя. Многие современные инструменты преобразуют каждое предложение в числовой «отпечаток» и затем измеряют близость этих отпечатков. Эти подходы работают относительно хорошо при отсутствии отрицания, но часто дают сбой, когда встречаются слова вроде «не», «никогда» или «нет». Например, «Метод точен» и «Метод не точен» компьютеру могут показаться удивительно похожими, хотя по смыслу они противоположны. Авторы показывают, что важно не только наличие отрицания, но и количество слов отрицания и их расположение в предложении — всё это может полностью изменить предполагаемый смысл.
Создание набора данных, обучающего тонкостям
Чтобы обучить систему действительно понимать отрицание, авторам сначала потребовались данные, подчёркивающие такие сложные случаи. Они создали набор данных Negation-Sentence-Similarity, содержащий 8 575 пар предложений из четырёх областей информатики: операционные системы, базы данных, компьютерные сети и машинное обучение. Для каждой пары люди присвоили оценку схожести с учётом отрицания. Набор данных также фиксирует, сколько слов отрицания содержит каждое предложение и какой узор отрицания в нём наблюдается — например, единичное «не», чётное или нечётное количество отрицаний или более сложные случаи, когда отрицание взаимодействует со связками вроде «потому что» или «но». Такая подробная разметка даёт модели явные подсказки о том, как отрицание формирует значение.
Гибридный движок, объединяющий разные точки зрения
Ядро предложенной системы, названной Negation-Aligned Similarity Scorer, — это двухфазный движок. На первой фазе каждое предложение прогоняется через несколько разных языковых моделей, каждая из которых улавливает слегка разные аспекты смысла. Их выходы объединяются и затем подаются в двунаправленную рекуррентную сеть, которая рассматривает предложение в целом, учитывая порядок слов и локальный контекст. Это даёт компактное свёрнутое представление каждого предложения, лучше чувствительное к тонкой формулировке, включая положение слов отрицания относительно других слов.
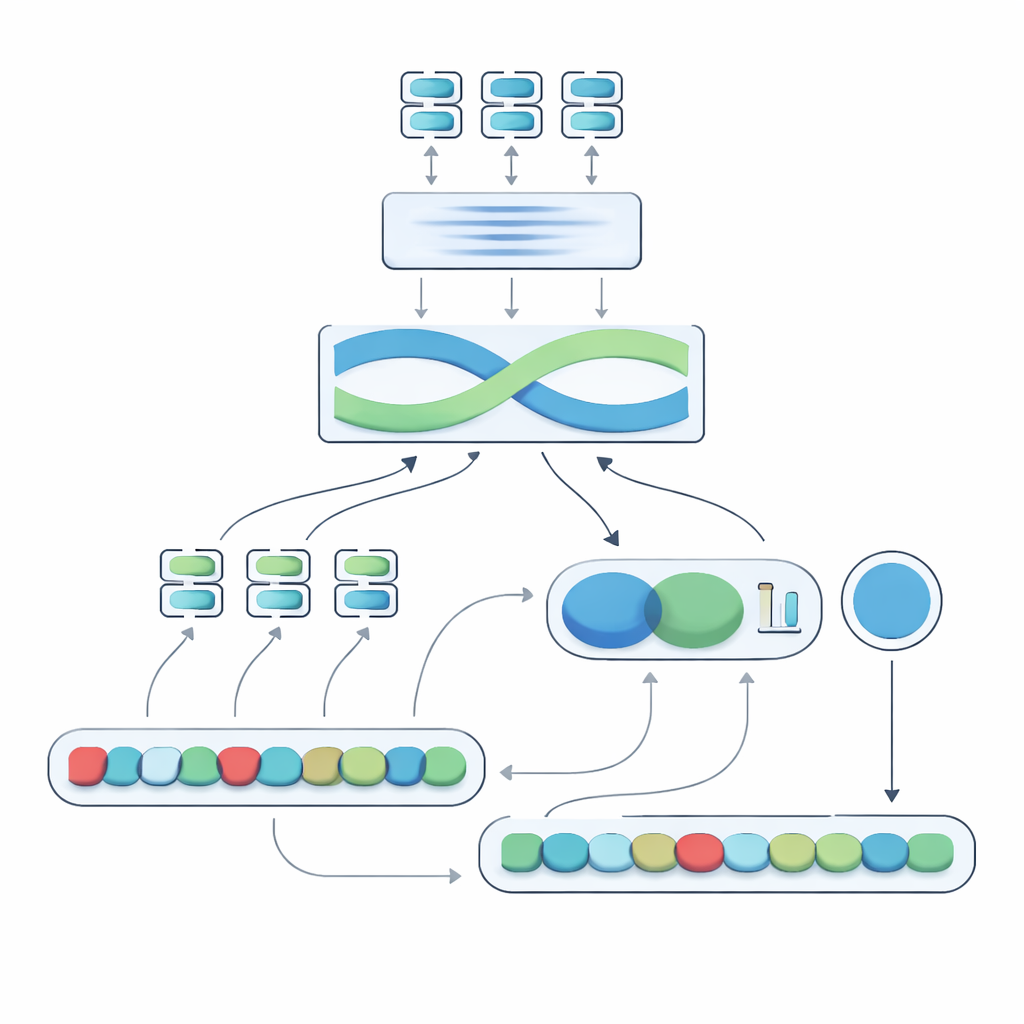
Обучение модели улавливать переворот смысла при отрицании
На второй фазе система сравнивает два свёрнутых представления предложений и добавляет явную информацию об отрицании. Она оценивает, насколько различаются представления, насколько они перекрываются, и объединяет эти сигналы с тремя простыми признаками: разницей в количестве слов отрицания, тем, имеют ли предложения нечётное или чётное число отрицаний (что может обратить или отменить отрицательный смысл), и тем, появляется ли отрицание примерно в соответствующих позициях. Все эти подсказки смешиваются в небольшой предсказательной сети, которая выдаёт оценку схожести от 0 до 100. Обученная сквозным способом на курированном наборе данных, эта оценка становится чувствительной к тому, как отрицание перекраивает смысл, а не рассматривает «не» как обычное слово.
Насколько хорошо новый скорер работает на практике
Чтобы протестировать подход, авторы оценивают его как на собственном наборе данных, так и на широко используемом бенчмарке схожести предложений. По сравнению с мощными базовыми моделями на трансформерах, использующими стандартные методы, новый скорер показывает меньшую ошибку предсказания и существенно лучшее качество классификации, с F1-мерой близкой к 0.97. В тщательно отобранных примерах он ставит низкие оценки схожести, когда отрицание явно меняет смысл, и высокие оценки, когда двойное отрицание фактически его нейтрализует, в то время как конкурирующие модели по-прежнему склонны переоценивать схожесть. Исследование абляции подтверждает, что оба ключевых компонента — последовательностно-чувствительный рекуррентный слой и явные признаки отрицания — важны для этого прироста в качестве.
Что это значит для студентов и будущих инструментов
Для широкой аудитории вывод прост: то, как мы говорим «не», имеет значение, и машин можно научить это замечать. Смешивая несколько языковых моделей, контекстную обработку и простые подсчёты и позиции слов отрицания, предложенный скорер обеспечивает более справедливый и надёжный способ оценивать, действительно ли два предложения означают одно и то же. Это может помочь системам автоматизированного оценивания избегать серьёзных ошибок, например, трактовать «не разрешено» как «разрешено». Хотя метод требует больших вычислительных ресурсов и пока ориентирован на технические домены, он указывает путь к будущим инструментам, которые лучше уловят тонкую логику повседневного языка, делая автоматические языковые технологии умнее и надёжнее.
Цитирование: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Ключевые слова: схожесть предложений, отрицание в языке, автоматизированное оценивание, обработка естественного языка, модели глубокого обучения