Clear Sky Science · ru
Высокопроизводительный поиск IP-адресов с помощью ускорения на GPU для поддержки масштабируемой и эффективной маршрутизации в данных-управляемых сетях связи
Почему важны более быстрые «интернет‑дороги»
Каждая фотография, которую вы делитесь, каждое видео, которое вы смотрите, и каждое сообщение, которое вы отправляете, проходят через сеть цифровых перекрёстков — маршрутизаторов. Каждый маршрутизатор должен быстро решить, куда переслать каждый пакет данных дальше. По мере взрывного роста глобального использования Интернета эти решения принимаются миллиардами раз в секунду, и даже крошечные задержки могут приводить к замедлению просмотра или перегрузке сетей. В этой статье рассматривается новый подход к ускорению одного из самых затратных по времени шагов в этом процессе принятия решений — за счёт использования огромной параллельной мощности графических процессоров, тех же чипов, что приводят в действие видеоигры и ИИ, чтобы будущие сети оставались быстрыми и масштабируемыми.
Скрытая адресная книга Интернета
В основе каждого маршрутизатора лежит гигантская адресная книга, называемая таблицей переадресации, которая сопоставляет диапазоны IP‑адресов с следующим этапом пути. Когда пакет поступает, маршрутизатор должен найти запись, которая наилучшим образом соответствует адресу назначения пакета, применяя правило «наибольшего совпадающего префикса»: из всех частичных совпадений выбирается самое конкретное. Традиционные программные методы хранят эти префиксы в древовидных структурах и проходят их шаг за шагом. Это работает, но по мере того как таблицы вырастают до десятков или сотен тысяч записей, процесс становится медленнее и требует больше памяти, особенно на обычных центральных процессорах, которые способны одновременно обрабатывать лишь ограниченное число задач.
Превращение графического чипа в регулировщика трафика
Авторы предлагают переложить эту тяжёлую задачу поиска на графический процессор (GPU) — чип, спроектированный для выполнения тысяч мелких задач параллельно. Их схема рассматривает GPU как помощника основного процессора. Центральный процессор подготавливает и организует таблицу маршрутизации, затем отправляет компактные версии данных на GPU. Когда пакеты поступают, их адреса назначения разбиваются и отправляются на GPU, где множество потоков одновременно ищут наилучшее совпадение. Позволяя сотням или тысячам поисков выполняться параллельно, маршрутизатор способен выдерживать темп современных данных‑ориентированных коммуникаций.
Уменьшение адресов для ускорения решений
Ключевая идея работы заключается в том, что более короткие адреса быстрее просматриваются. Вместо использования необработанных IP‑адресов авторы сжимают их без потерь с помощью метода, похожего на кодирование Хаффмана, который присваивает более короткие коды наиболее частым шаблонам адресов. Это уменьшает среднее число бит, необходимых для представления каждой записи, сокращая и объём памяти, и высоту основной поисковой структуры. Затем префиксы хранят в «мультибитовом» дереве, которое рассматривает несколько бит за шаг, а не по одному, что дополнительно снижает число требуемых шагов. Чтобы подстроиться под сильные стороны GPU, они транслируют это дерево в простые одномерные массивы, заменяя сложные переходы по указателям регулярными вычислениями индексов, которые тысячи потоков могут эффективно выполнять.
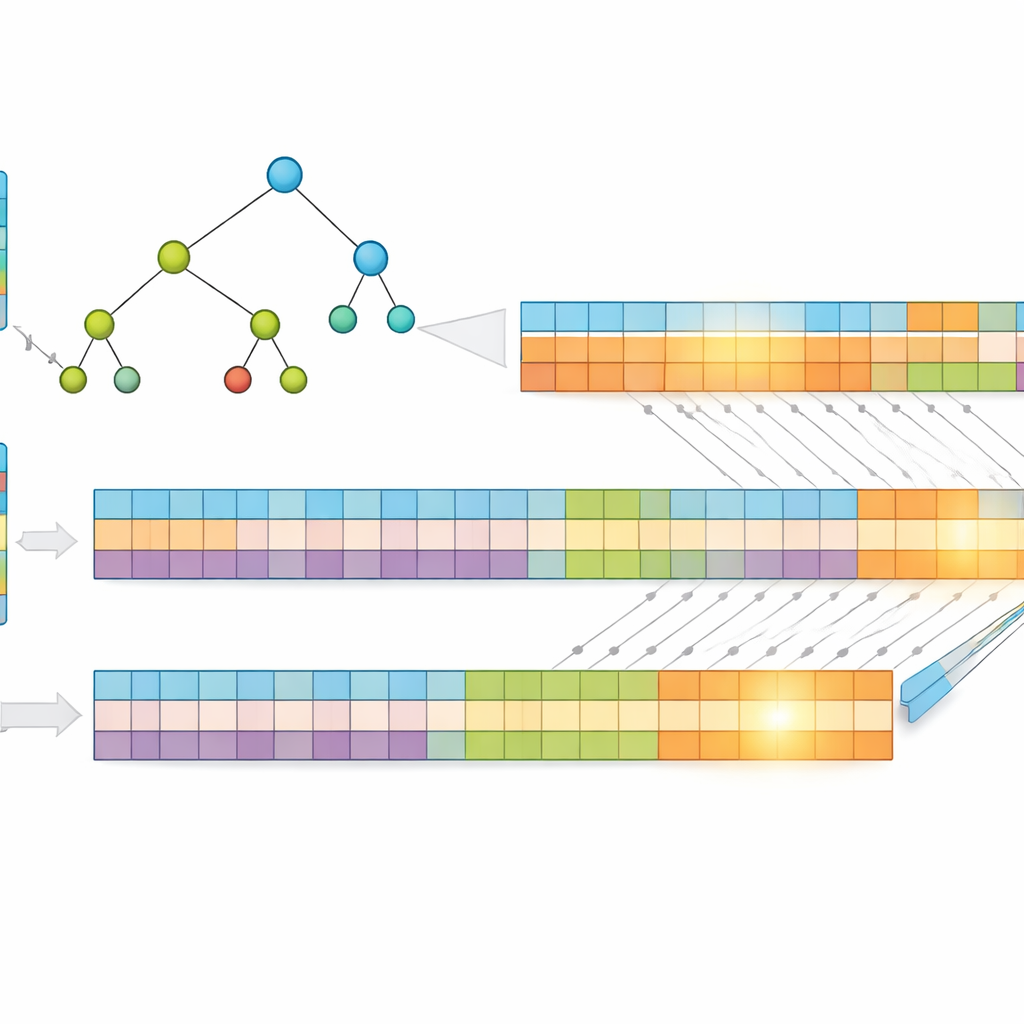
Разделение задачи для массового параллелизма
Чтобы ещё больше повысить производительность, исследователи делят каждый сжатый адрес на две равные части и строят два отдельных дерева — одно для первой половины, другое для второй. Когда поступает пакет, GPU одновременно ищет в обоих деревьях. Каждый поиск возвращает небольшой набор возможных совпадений, а окончательный ответ получается пересечением этих наборов для нахождения общего, самого конкретного префикса. Поскольку работа разделена и обрабатывается одновременно, время выполнения зависит в основном от максимальной длины префикса и числа бит, рассматриваемых за шаг, а не от того, сколько записей содержит таблица. Тесты на реальных данных маршрутизации показывают, что эта схема сохраняет почти постоянное время поиска даже по мере роста таблицы.
Что показывают эксперименты
Команда сравнила свой метод на базе GPU с различными известными подходами, включая классические двоичные деревья, сжатые деревья и другие схемы ускорения на GPU, такие как хеширование и двоичные поисковые деревья. На реальных наборах данных маршрутизации их система продемонстрировала впечатляющие улучшения: примерно на 83–91 % быстрее по сравнению с популярными методами на центральных процессорах на основе деревьев и на 89–97 % быстрее по сравнению с предыдущими методами на GPU. Сжатие также сократило использование памяти примерно на одну треть в среднем, снижая нагрузку на ограниченную память на чипе и помогая удерживать поисковые структуры GPU неглубокими и эффективными. Важно, что производительность метода оставалась стабильной при разных размерах таблиц маршрутизации, что подчёркивает его пригодность для растущих сетей.
Что это означает для обычных пользователей
Для неспециалиста итог таков: авторы показывают, как превратить графический чип в высокоэффективного «регулировщика» интернет‑трафика, используя умные приёмы сжатия и разделения адресной информации. Комбинируя сжатие, более продуманные структуры дерева и массовый параллельный поиск, их подход находит наилучший маршрут для каждого пакета значительно быстрее многих существующих техник, не замедляясь по мере расширения «адресных книг» Интернета. Хотя работа демонстрируется в основном для нынешней адресной системы, те же идеи могут быть расширены на более крупное адресное пространство будущего, помогая сохранять отзывчивость онлайн‑сервисов по мере роста нашего спроса на данные.
Цитирование: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Ключевые слова: маршрутизация на GPU, поиск IP, масштабируемость сети, переадресация пакетов, параллельные вычисления