Clear Sky Science · ru
Обнаружение камуфлированных объектов через контекстно- и текстурно‑ориентированное иерархическое взаимодействие
Почему важно замечать скрытые формы
От насекомых цвета листьев до военной камуфляжной формы и трудноразличимых новообразований на медицинских снимках — наш мир полон объектов, созданных, чтобы сливаться с фоном. Научить компьютеры надежно находить такие замаскированные объекты может помочь в защите дикой природы, повысить безопасность при инспекциях и помочь врачам обнаруживать болезни на более ранних стадиях. В этой статье представлена новая система искусственного интеллекта под названием CTHINet, которая учится «видеть сквозь» камуфляж, обращая внимание не только на общий контекст сцены, но и на крошечные текстурные подсказки, которые часто ускользают от человеческого глаза.
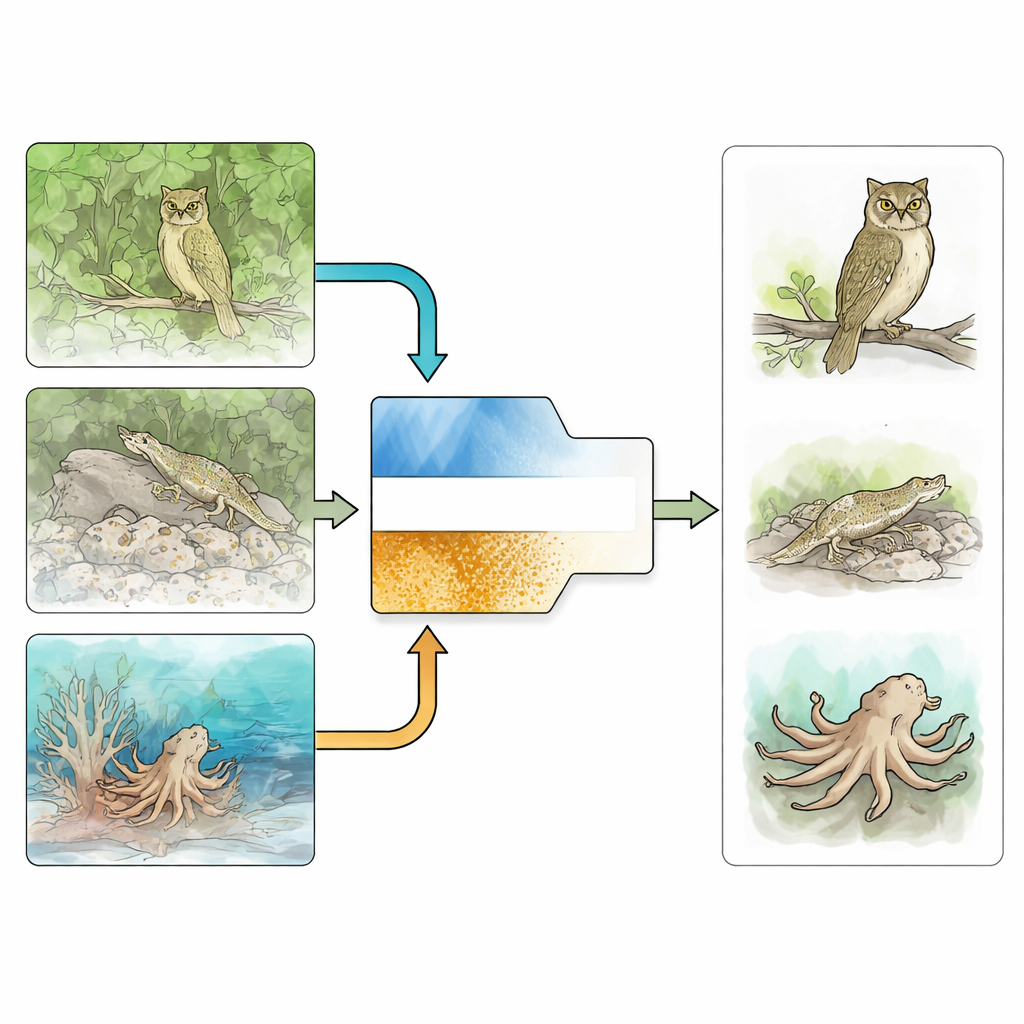
Видеть и лес, и деревья
Обнаружение камуфлированных объектов гораздо сложнее, чем обычное обнаружение объектов, потому что цель часто совпадает с окружением по цвету, яркости и форме. Ранние методы опирались на простые вручную заданные признаки, такие как движение, границы или базовая текстура, которые дают сбой в загромождённых или шумных сценах. Современные подходы на основе глубокого обучения добились прогресса, обучая большие сети на специализированных коллекциях изображений с камуфлированными животными и искусственными объектами. Многие из этих методов добавляют дополнительные подсказки — например, выделение границ объектов или оценку неопределённости, — но они легко вводятся в заблуждение, когда сами границы размыты или неоднозначны — как раз то, что характерно для хорошего камуфляжа.
Крошечные текстурные подсказки, которые выдают замысел
Авторы утверждают, что даже при отличном камуфляже остаются характерные следы в тонкой текстуре изображения — небольшие различия в зерне, узоре или гладкости, которые легко упустить, если сосредоточиться только на контурах. Исходя из этой идеи, CTHINet разделяет обучение на две координированные ветви. Одна «контекстная» ветвь, основанная на мощном бэкбоне с трансформером для зрения, захватывает широкую, многомасштабную информацию о всей сцене: как регионы соотносятся друг с другом, где лежат крупные формы и в каких областях с большей вероятностью может находиться объект. Параллельно выделенная «текстурная» ветвь узко фокусируется на тонких поверхностных паттернах и обучается по специальным текстурным меткам, которые подсказывают сети, какие виды тонких деталей принадлежат скрытому объекту, а какие — фону.
Как две ветви взаимодействуют
Просто запускать две ветви недостаточно; они должны взаимодействовать умно. CTHINet сначала уточняет контекстные признаки с помощью Модуля агрегирования признаков с несколькими головами (Multi‑head Feature Aggregation Module). Этот модуль разделяет информацию на несколько частей, каждая из которых обрабатывается с разным эффективным «уровнем увеличения», чтобы система могла реагировать как на крошечных насекомых, так и на крупных животных. Затем эти представления рекомбинируются, чтобы они дополняли друг друга без взрыва вычислительных затрат. Далее серия Иерархических модулей смешанного масштаба (Hierarchical Mixed‑scale Interaction Modules) связывает контекстный и текстурный потоки. На каждом этапе сеть группирует и смешивает каналы из обеих ветвей, позволяет им обмениваться информацией, а затем переназначает веса так, чтобы наиболее информативные комбинации усиливались, а менее полезные — подавлялись. Это чередование от грубого к тонкому постепенно уточняет очертания скрытого объекта и отделяет его от отвлекающих деталей фона.
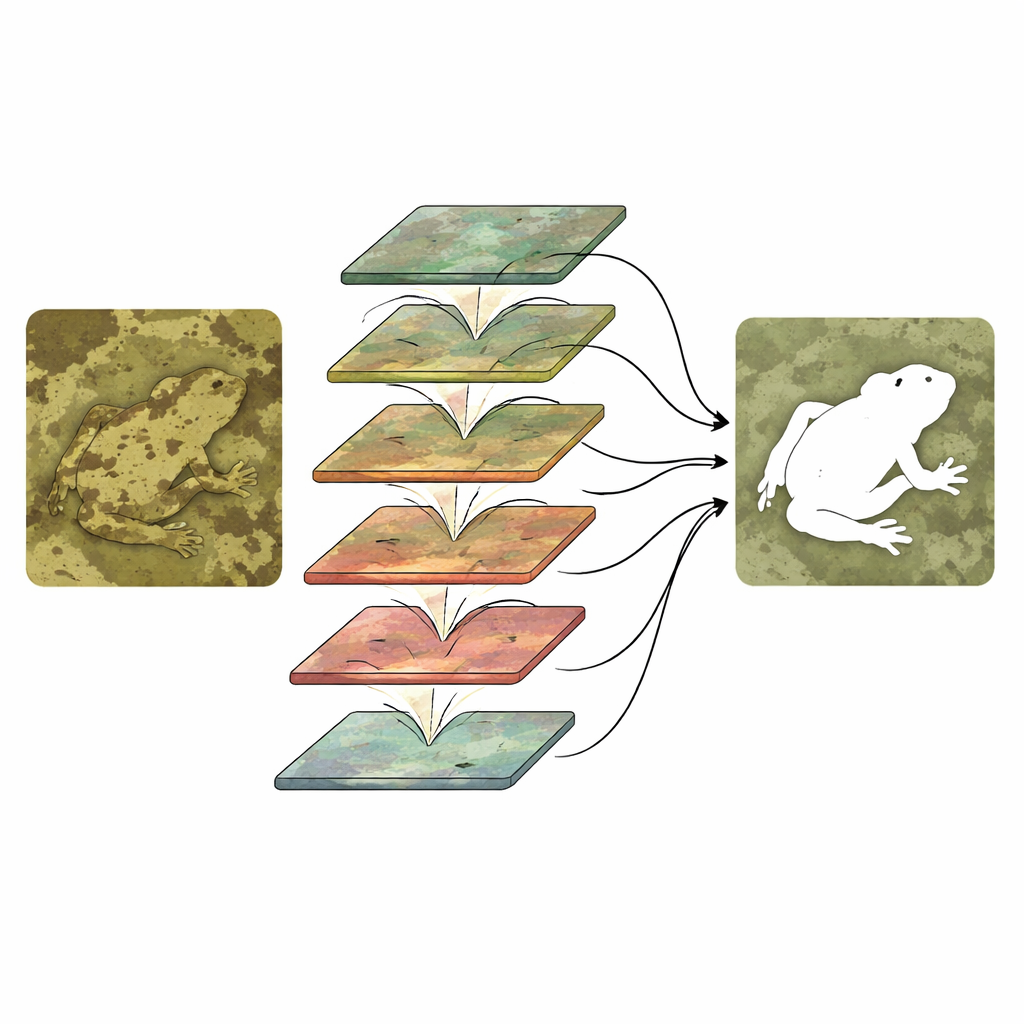
Доказательства работоспособности в природе и в клинике
Для тестирования CTHINet исследователи оценили его на трёх сложных общедоступных бенчмарках с камуфлированными животными и объектами, содержащих тысячи изображений в разнообразных природных условиях. По нескольким стандартным метрикам точности новый метод последовательно превосходил более двадцати ведущих систем, особенно на трудных сценах с малыми целями, сильным совпадением с фоном или частичной окклюзией. Команда также опробовала ту же сеть с минимальными изменениями на медицинской задаче: сегментации полипов на изображениях колоноскопии. Полипы часто сливаются со стенкой кишечника примерно так же, как животные сливаются с листвой. И здесь CTHINet показал лучшие результаты среди нескольких сильных моделей для медицинских изображений, что указывает на широкую применимость подхода сочетания контекста и текстуры.
Что это значит для поиска практически невидимого
В повседневных терминах CTHINet воплощает простую, но мощную идею: чтобы найти то, что намеренно скрыто, компьютер должен смотреть и на общую картину, и на мельчайшие поверхностные детали, позволяя этим двум представлениям шаг за шагом дополнять друг друга. Разработав сеть, которая чётко разделяет эти роли, а затем воссоединяет их через тщательно организованные взаимодействия, авторы добиваются более точного обнаружения камуфлированных целей и демонстрируют перспективность для медицинских и промышленных инспекций, где важные структуры легко упустить. По мере роста объёмов изображений такие контекстно‑ и текстурно‑чувствительные системы могут стать ключевыми инструментами для выявления того, что намеревались оставить незаметным.
Цитирование: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Ключевые слова: обнаружение камуфлированных объектов, компьютерное зрение, анализ текстуры, сегментация медицинских изображений, глубокое обучение