Clear Sky Science · ru
Крупномасштабный набор данных о выборе и времени реакции в межвременном выборе
Почему важно ждать или выбирать сейчас
Повседневная жизнь полна выборов между меньшей наградой сейчас и большей наградой позже: потратить деньги сегодня или отложить на пенсию, съесть десерт или придерживаться диеты. То, как мы принимаем эти «сейчас против позже» решения — известные как межвременные выборы — определяет наше здоровье, финансы и отношения. Тем не менее учёные всё ещё спорят о том, что происходит в нашем сознании во время таких решений. В этой статье представлен огромный новый открытый набор данных, объединяющий подробные записи о том, как почти двенадцать тысяч человек принимали такие решения, включая не только сделанный выбор, но и то, сколько времени они затратили на принятие решения.
Объединение разрозненных исследований
Десятилетиями экономисты и психологи проводили эксперименты, в которых люди выбирали, например, между меньшей суммой денег вскоре и большей суммой позже. Многие из этих исследований сосредотачивались только на конечном выборе, игнорируя сам процесс принятия решения. Авторы утверждают, что это упускает важный источник информации: времена реакции — сколько секунд люди тратят на выбор. Времена реакции могут показывать, насколько легко или тяжело даётся выбор, и помогают проверять теории о том, как мозг взвешивает немедленные и отложенные вознаграждения. Чтобы выйти за рамки разрозненных результатов, авторы собрали сырые данные по каждому испытанию из 100 отдельных исследований, в совокупности охватывающих 11 852 участника и 1 172 644 отдельных решения.
Поиск и унификация данных
Команда сначала провела большой систематический поиск научной литературы в двух крупных базах данных, чтобы найти любые опубликованные эксперименты, использующие стандартную компьютерную задачу межвременного выбора с чётко определёнными суммами денег и временами ожидания. Из более чем четырёх тысяч первоначальных найденных работ они применили строгие критерии, чтобы исключить исследования, которые не соответствовали задаче, не проходили рецензирование, использовали нечеловеческих субъектов, были не на английском языке или не содержали первичных данных. В результате отсева осталось 1 709 потенциально подходящих статей. Для каждой из них исследователи либо находили уже открытые файлы данных, либо напрямую связывались с авторами, в итоге отправив более 1 600 официальных запросов на данные, чтобы получить информацию по отдельным испытаниям.
Как выглядит объединённый набор данных
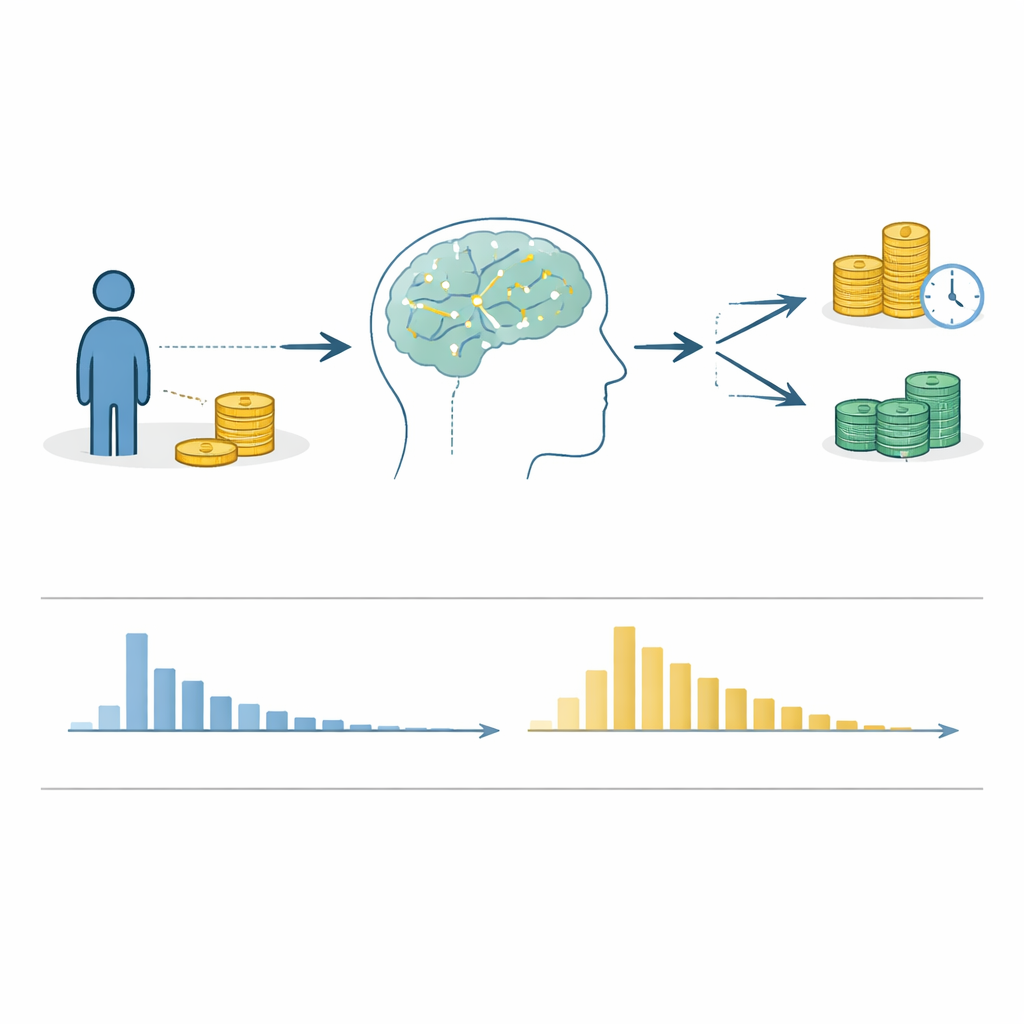
В результате этой работы авторы получили 112 наборов данных из 98 публикаций и, после получения окончательных разрешений и проверок качества, выпустили 100 наборов данных из 87 статей. Каждая строка объединённого файла соответствует одному испытанию выбора и включает то, что предлагалось (меньшая—скорее и большая—позже суммы), какой вариант был выбран и сколько времени человек потратил на ответ. Дополнительные поля описывают участника (например, возраст и страна), условия проведения задачи (онлайн или в лаборатории, были ли выборы оплачены реально, присутствовало ли временное давление) и правила фильтрации данных (например, испытания с пропущенными значениями). Все данные предоставлены в общепринятых форматах и имеют одинаковую структуру переменных, что облегчает их анализ исследователями с помощью разных программных инструментов.
Проверка данных «за кулисами»
Поскольку набор данных объединяет множество независимых исследований, авторы провели обширные технические проверки, чтобы убедиться, что цифры имеют смысл. Они сравнили заявленные размеры выборок и количество испытаний в каждой статье с тем, что фактически присутствует в файлах, задокументировали любые несоответствия и проанализировали паттерны пропущенных ответов. Они проверили, действительно ли вариант «меньше—скорее» был меньше и раньше по сравнению с вариантом «больше—позже», и связывались с авторами оригинальных работ, если что‑то выглядело подозрительно. Также они тестировали, адекватно ли ведут себя выборы людей — например, увеличивает ли более высокая награда и более короткое ожидание вероятность выбора варианта. Для времён реакции они отсеивали невозможные значения, такие как отрицательные времена или решения с невероятно быстрой или медленной реакцией, и проверяли, демонстрируют ли большинство участников типичную картину многих быстрых ответов и меньшинства медленных.
Живой ресурс для будущих открытий
Авторы выпустили статический снимок этого крупномасштабного набора данных, связанный со статьёй, а также поддерживаемую онлайн‑базу данных, которая будет расти по мере того, как другие исследователи будут вносить свои данные. Наряду с объединённым мастер‑файлом, все отдельные наборы данных также доступны для загрузки там, где позволяют разрешения. Хотя исходные скрипты обработки сырых данных не всегда предоставлены, итоговые данные задокументированы и лицензированы для широкого повторного использования в некоммерческих работах. Этот ресурс открывает путь для учёных тестировать новые модели того, как люди соотносят настоящее и будущее вознаграждение, исследовать, почему результаты иногда различаются в разных условиях и группах, и выстраивать более надёжные теории принятия решений. Для непрофессионального читателя ключевая мысль такова: у исследователей теперь есть мощная, совместная база для понимания того, почему ждать лучшего завтра бывает так трудно — и как эта трудность варьируется от человека к человеку и от ситуации к ситуации.
Цитирование: Pongratz, H., Schoemann, M. A large-scale dataset of choice and response-time data in intertemporal choice. Sci Data 13, 323 (2026). https://doi.org/10.1038/s41597-026-06947-4
Ключевые слова: межвременный выбор, дисконтирование задержки, времена реакции, принятие решений, открытый набор данных