Clear Sky Science · ru
Единый набор данных для проектирования антител и нанотелец, включающий последовательности, структуры и данные об аффинности связывания
Почему маленькие иммунные инструменты и большие данные важны
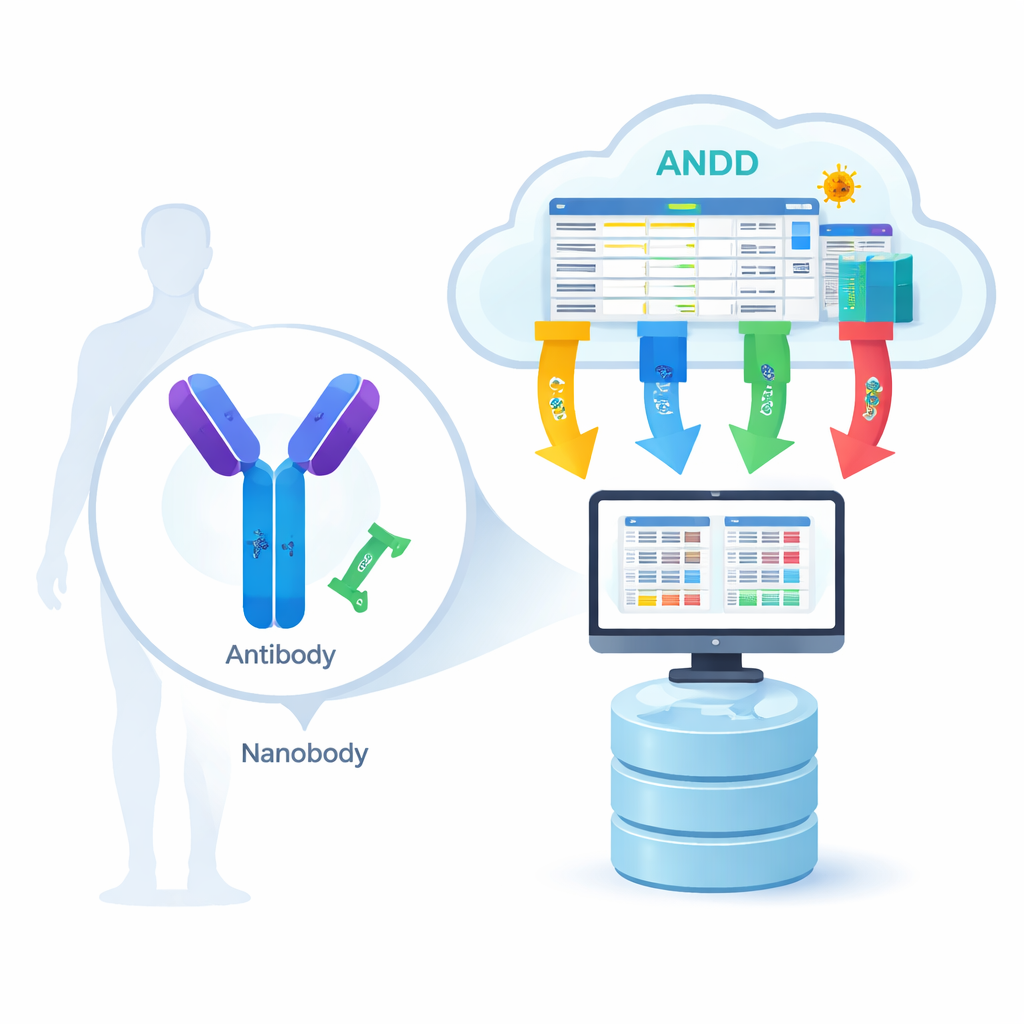
Антитела и их меньшие родственники — нанотела — действуют как прицельно‑наводимые «ракеты» организма против инфекций и рака. Сейчас разработчики лекарств пытаются проектировать эти молекулы на компьютере, так же как инженеры проектируют самолёты. Но до недавнего времени исходный материал для такого проектирования с помощью искусственного интеллекта — надёжные данные о компонентах антител, их формах и силе связывания с мишенями — был разбросан по множеству несовместимых баз данных. В этой статье представлен набор данных Antibody and Nanobody Design Dataset (ANDD) — единый, публичный ресурс, созданный для предоставления исследователям чистых, всесторонних данных, необходимых для разработки следующего поколения прицельных терапий.
От биологического «замка и ключа» к цифровому чертежу
Антитела — крупные белки в форме буквы Y, тогда как нанотела представляют собой гораздо меньшие одноцепочечные варианты, встречающиеся у животных, таких как ламы и альпаки. Оба распознают специфические «замки» на вирусах, раковых клетках или других белках, связанных с болезнью. Чтобы компьютерные модели научились этому распознаванию, им нужны четыре вида информации для множества примеров: аминокислотная последовательность (список составляющих), трёхмерная структура (форма), антиген (мишень) и сила связывания (насколько прочно они взаимодействуют). До сих пор большинство ресурсов содержали только одну‑две такие составляющие, заставляя учёных переключаться между базами данных и вручную сводить данные воедино, что замедляло прогресс и вводило ошибки.
Объединение разбросанных фрагментов в одну организованную библиотеку
Команда ANDD собрала данные из 15 основных источников, включая специализированные базы антител и нанотел, общие репозитории белков и даже патентные документы. Затем эти исходные данные прошли через тщательно прописанный конвейер: загрузка, приведение к общей схеме, сопоставление идентификаторов, удаление дубликатов и унификация правил именования. Когда базы данных расходились, приоритет отдавался курированным источникам и прямым экспериментам. В результате получилась единая таблица и набор файлов структур, которые последовательно связывают последовательность, структуру, мишень и информацию об аффинности; каждая запись помечена так, чтобы пользователи могли проследить её происхождение и порядок обработки.
Многоуровневая детализация для разных задач исследований
Не все записи в ANDD одинаково полны, поэтому авторы организовали коллекцию в слои с нарастающей степенью детализации. На самом широком уровне содержится 48 683 записи об антителах и нанотелах с информацией о последовательности. Большая подсекция добавляет 3D‑структуры, а меньшая — ещё и последовательности мишеней. Самый подробный слой — несколько тысяч записей — включает измеренную или предсказанную силу связывания. Например, для антител 18 464 записи имеют последовательности, столько же объединяют последовательность и структуру, более 8 000 также содержат последовательности антигенов, а 7 737 записей имеют полный набор: последовательность, структуру, антиген и данные об аффинности. Параллельная иерархия существует для нанотел, что даёт экспериментаторам и разработчикам моделей гибкость: они могут выбирать большие простые наборы данных или меньшие, но более информационно насыщенные подмножества.
Заполнение пробелов в данных об аффинности
Сила связывания критична для разработки препаратов, но экспериментальные значения редки и сообщаются неравномерно. Чтобы устранить этот пробел, не размывая границу между данными и предсказанием, авторы использовали специализированный инструмент глубокого обучения ANTIPASTI для оценки силы связывания только для записей, у которых были структуры, но не было измерений. Эти 2 271 предсказанных значения явно помечены и хранятся отдельно от примерно 7 000 экспериментально измеренных. Команда затем проверила общую согласованность с помощью другой модели, AlphaBind, и путём сравнения математически связанных показателей связывания. Сильные корреляции и низкие ошибки свидетельствуют о том, что отобранные экспериментальные значения надёжны, а предсказанные следуют разумным трендам и не рассматриваются как истина в последней инстанции.
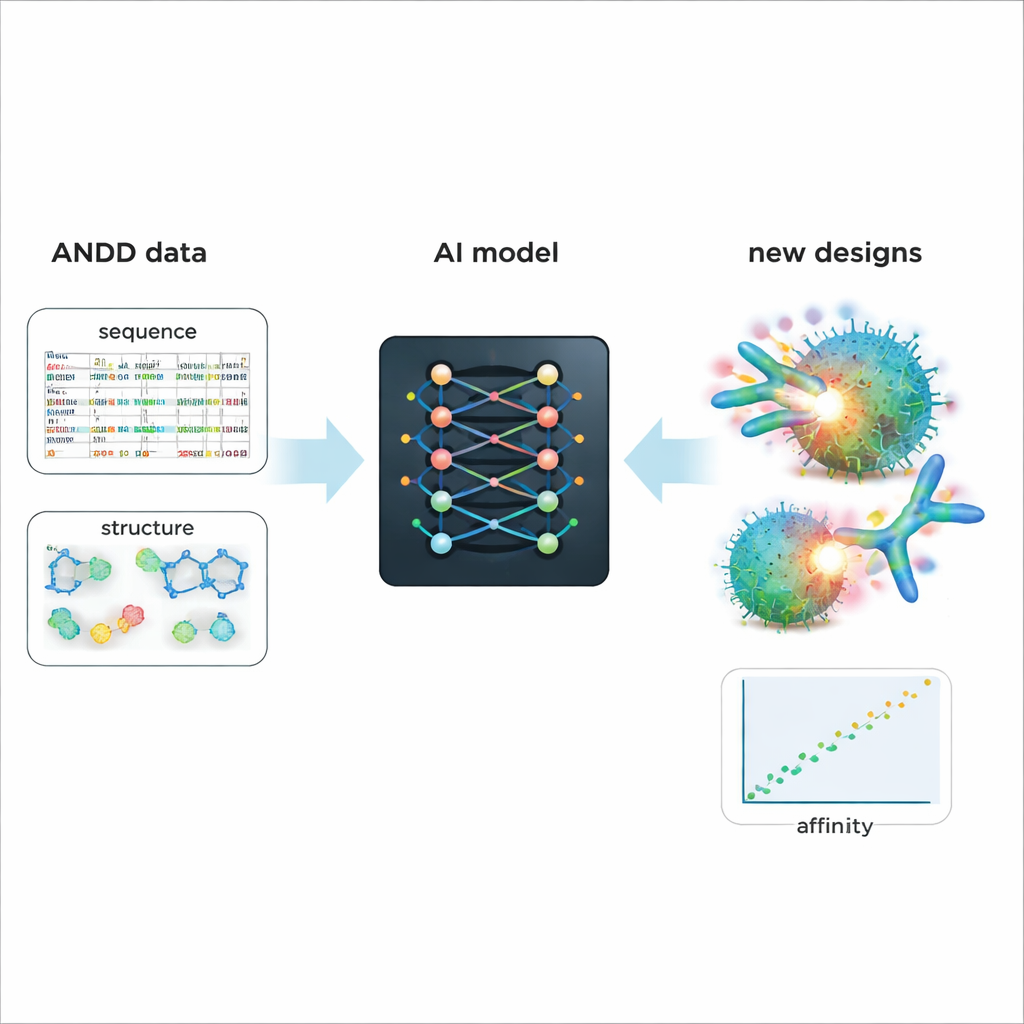
Питая более умное проектирование будущих лекарств
Чтобы продемонстрировать практическую ценность ANDD, авторы дообучили существующую генеративную модель ИИ, проектирующую антитела и нанотела. Обучение на объединённых данных ANDD — последовательности, структуре, мишени и аффинности — привело к генерации молекул с лучшей предсказанной силой связывания и более реалистичными формами по сравнению с базовой моделью, обученной на старых, упрощённых данных. Кроме этого примера, ANDD открыт под либеральной лицензией, поставляется с полной документацией и воспроизводимым конвейером сборки и задуман как регулярно обновляемый ресурс. Для неспециалистов ключевое сообщение таково: ANDD превращает шумной лоскутный набор данных об антителах в последовательную, заслуживающую доверия библиотеку — давая инструментам ИИ значительно лучшую отправную точку для разработки точных и более эффективных биологических лекарств.
Цитирование: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Ключевые слова: проектирование антител, нанотела, аффинность связывания, биологические терапевтические препараты, ИИ в разработке лекарств