Clear Sky Science · ru
Набор данных PreprintToPaper: связывание препринтов bioRxiv с журнальными публикациями
Почему ранние исследования важны для всех нас
Задолго до того, как научное открытие появится в глянцевом журнале, оно часто публикуется как «препринт» — ранняя, свободно распространяемая версия работы. Во время пандемии COVID‑19 такие препринты формировали заголовки новостей, общественные дискуссии и даже политику в области здравоохранения. Тем не менее отслеживать, какие ранние исследования затем стали формальными журнальными статьями, а какие — нет, оказалось неожиданно сложно. В этой статье представлен набор данных PreprintToPaper — большой, тщательно проверенный справочник, который связывает препринты в области биологических наук на сервере bioRxiv с их последующими журнальными публикациями, давая общественности, журналистам и исследователям более ясное представление о том, как ранние результаты продвигаются по научной системе.
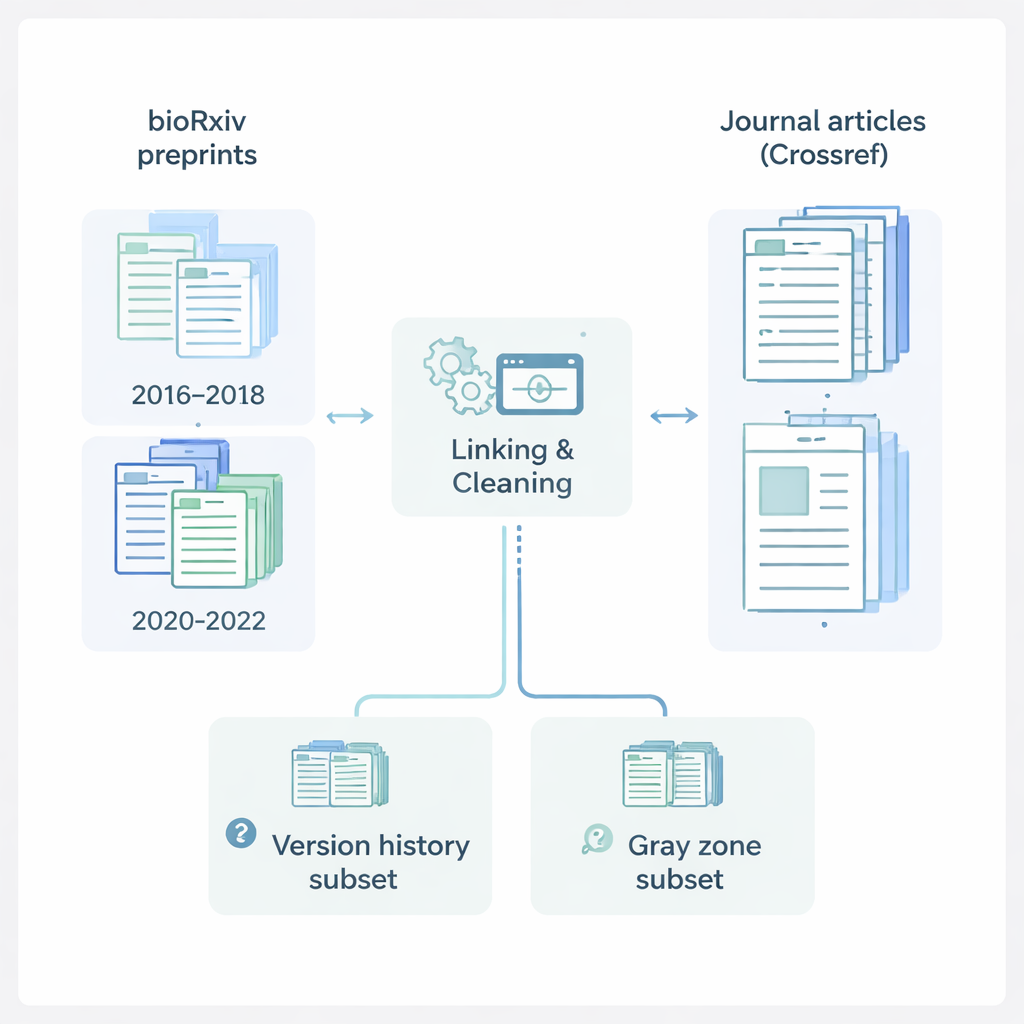
Прослеживая путь от черновика до статьи
Авторы сосредоточились на bioRxiv — крупном онлайн‑сервере, где исследователи в области биологических наук размещают препринты. Они собрали сведения о 145 517 препринтах из двух ключевых временных окон: 2016–2018 годов, до пандемии COVID‑19, и 2020–2022 годов, в разгар интенсивной публикационной активности, вызванной пандемией. Для каждого препринта они зафиксировали такие данные, как заголовок, аннотация, авторы, учреждения, предметная область, лицензия и даты подачи. Затем они использовали Crossref, центральный реестр журнальных статей, чтобы получить сопоставимую информацию о опубликованных статьях: названия журналов, даты публикации и полные списки авторов. Объединив эти источники, исследователи построили богатую, унифицированную запись, которая прослеживает исследование от его первого публичного появления в виде препринта до окончательной формы в научном журнале.
Разделение препринтов на понятные группы
Чтобы разобраться в этой большой коллекции, команда распределила каждый препринт в одну из трёх групп. «Опубликованные» препринты имели явную цифровую ссылку с bioRxiv на журнальную статью. Элементы «Только препринт» были размещены на сервере, но не показывали признаков публикации в другом месте. Самая любопытная группа, называемая «Серой зоной», содержит случаи, которые выглядят так, будто могли быть опубликованы в журнале, но не имеют официальной ссылки на bioRxiv. Чтобы отразить, как препринты изменяются со временем, исследователи также составили отдельный файл истории версий, перечисляющий все доступные версии для препринтов, у которых была исходная версия и по крайней мере одно последующее обновление. Это даёт возможность изучать, как меняются заголовки, списки авторов и другие детали между первым черновиком и последней версией препринта.
Обнаружение скрытых совпадений и ручная проверка
Многие препринты, которые на самом деле были опубликованы, так и не получают правильной обратной ссылки на bioRxiv, создавая «слепые» места для тех, кто пытается отслеживать научный выход. Чтобы обнаружить эти пропущенные связи, авторы сравнили заголовки препринтов и списки авторов с журнальными записями Crossref. Они использовали коэффициент сходства от 0 до 1 для измерения того, насколько близко совпадают два заголовка; потенциальные совпадения из Серой зоны требовали оценки не менее 0,75. Затем они уточняли эти кандидаты с помощью показателей, основанных на авторах: насколько сильно различалось число авторов и насколько похожи были имена. Чтобы проверить надёжность этих автоматических правил, двое аннотаторов вручную рассмотрели 299 пограничных случаев. Их суждения сильно совпали, и статистическая модель показала, что когда списки авторов хорошо совпадают, предполагаемая связь с высокой вероятностью является подлинной.
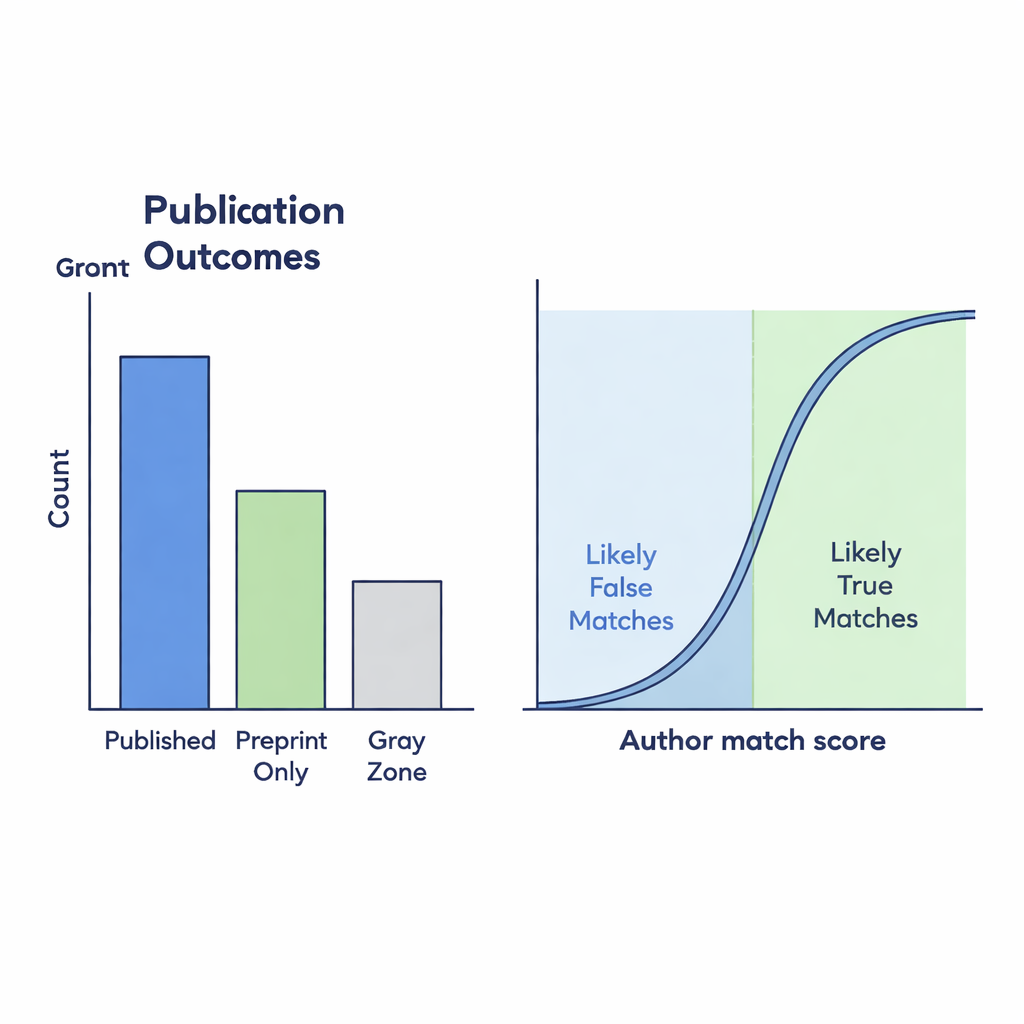
Что числа говорят о научной активности
Готовый набор данных показывает, как модели препринтинга и публикации изменились до и во время пандемии. В целом он содержит более 90 000 явно опубликованных препринтов, более 35 000, которые, по-видимому, остаются только на сервере, и около 19 000 случаев из Серой зоны, где связь с журнальной статьёй потребовала детективной работы. Если учитывать только официально связанные «Опубликованные» препринты, создаётся впечатление, что доля препринтов, превращающихся в журнальные статьи, со временем значительно снижается. Но если включить вероятные совпадения из Серой зоны — те, у которых сильное сходство авторов — снижение коэффициента публикации оказывается гораздо менее драматичным. Это указывает на то, что отсутствующие ссылки в инфраструктуре могут вводить в заблуждение относительно того, как меняется научный ландшафт.
Зачем этот ресурс полезен не только специалистам
Для неспециалистов главный вывод в том, что ранние научные результаты не просто исчезают в чёрном ящике. С набором данных PreprintToPaper становится возможным увидеть, какие быстрые результаты впоследствии проходят рецензирование и выживают, сколько времени занимает этот путь и какие типы исследований так и не покидают стадию препринта. Политики могут использовать эту информацию, чтобы оценить эффективность практик открытой науки; журналисты — лучше судить, насколько надёжен тот или иной результат; а исследователи — создавать инструменты для отсеивания и суммирования огромного потока статей. Короче говоря, этот набор данных превращает хаотичный поток ранних исследований в более прослеживаемую и подотчётную запись о том, как идеи переходят от первой публикации к отполированной журнальной статье.
Цитирование: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Ключевые слова: препринты, научные публикации, открытая наука, исследования COVID-19, библиометрика