Clear Sky Science · ru
Минимальный виртуальный набор данных для воспроизводимой de novo сборки триплоидного генома
Почему важны геномы с тремя копиями
Многие культуры и другие организмы имеют не две, а три или более копии каждой хромосомы, как это у людей. Сборка таких дополнительных копий из данных секвенирования оказывается неожиданно сложной задачей: копии очень похожи, но не идентичны. В этой статье представлен небольшой, но тщательно спроектированный «виртуальный» набор данных, который позволяет исследователям тестировать и сравнивать программы для сборки генома на реалистичной триплоидной задаче при полностью известных и воспроизводимых условиях.
Построение простого заменителя генома
Вместо того чтобы начинать с реального растения или животного, автор сначала создаёт случайный фрагмент ДНК длиной в миллион нуклеотидов, который служит чистым шаблоном. Этот шаблон затем дублируется в три отдельные версии, представляющие три набора хромосом у триплоида. Чтобы имитировать то, как реальные геномы постепенно меняются со временем, в каждую копию последовательно вносят фиксированное число небольших изменений — замены одиночных нуклеотидов. Повторение этого процесса в течение 100 шагов даёт триплеты геномов, которые варьируются от почти идентичных до явно, но умеренно различающихся. Этот контролируемый «градиент дивергенции» составляет основу бенчмарка.
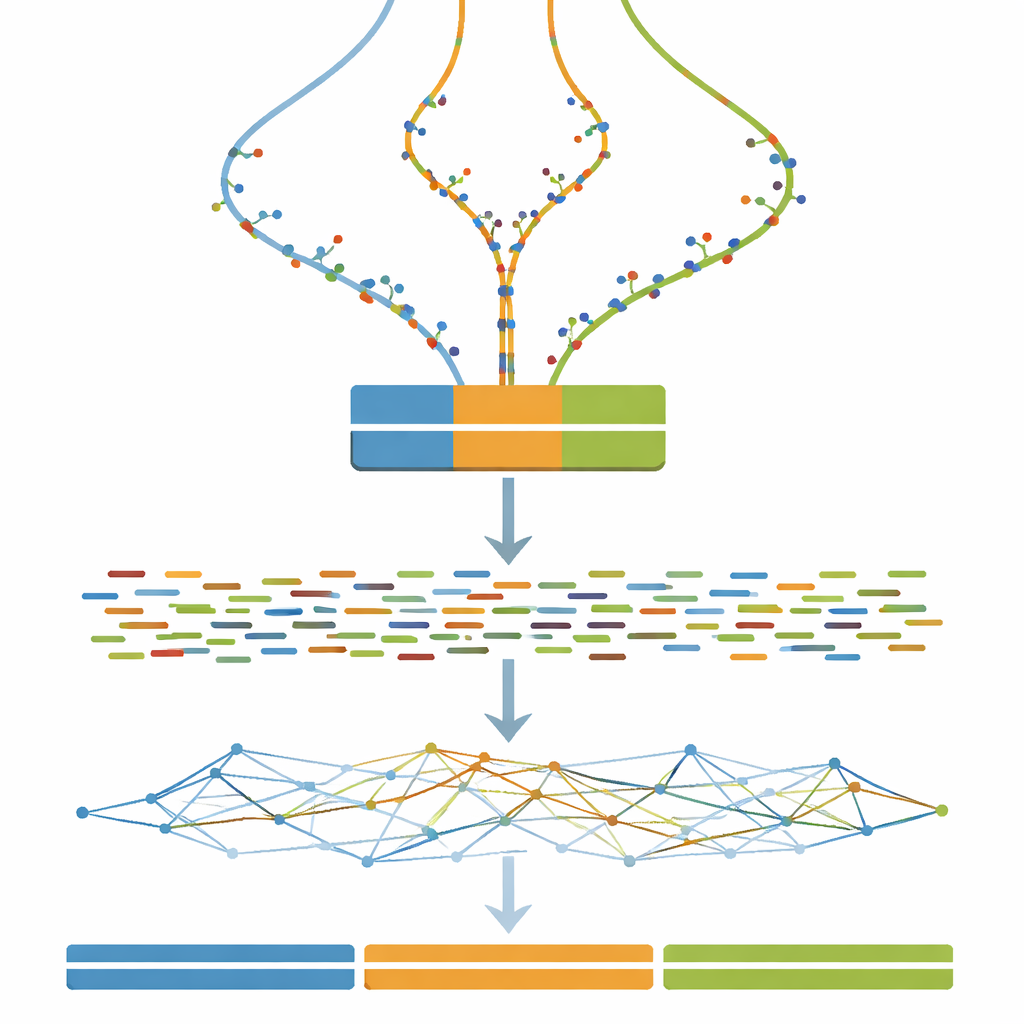
Преобразование виртуальных геномов в виртуальные эксперименты
Когда каждая троичная копия генома задана, следующий шаг — имитировать то, что видит аппарат для секвенирования ДНК. В исследовании используют широко распространённое программное обеспечение для моделирования коротких парных фрагментов ДНК, похожих на те, что даёт секвенатор Illumina, при постоянной и довольно высокой глубине покрытия. Опциональные шаги очистки имитируют типичные практики реального мира, такие как коррекция случайных ошибок секвенирования и объединение перекрывающихся пар ридов. В результате любой пользователь набора данных может тестировать не только свои алгоритмы сборки, но и то, как типичные предобрабатывающие решения влияют на финальные собранные геномы.
Стресс‑тест стратегий сборки
Сердцем работы является масштабный эксперимент, в котором все смоделированные риды подаются в одну программу сборки генома при изменении только одного ключевого параметра: размера k‑mer, который контролирует, насколько мелко программное обеспечение «нарезает» риды при реконструкции генома. Для каждой комбинации уровня дивергенции (от 0 до 100 шагов) и размера k‑mer (широкий набор нечётных значений) строится новая сборка. Сопутствующий инструмент оценки затем измеряет, насколько непрерывны собранные фрагменты, сколько их существует и насколько суммарная длина близка к известной эталонной трехмиллионной последовательности. Эти измерения сводятся в тепловые карты, выявляющие широкие зоны, где сборки сливают разные копии в одну, фрагментируются на многие маленькие куски или приближаются к идеалу трёх длинных, точных контингов.
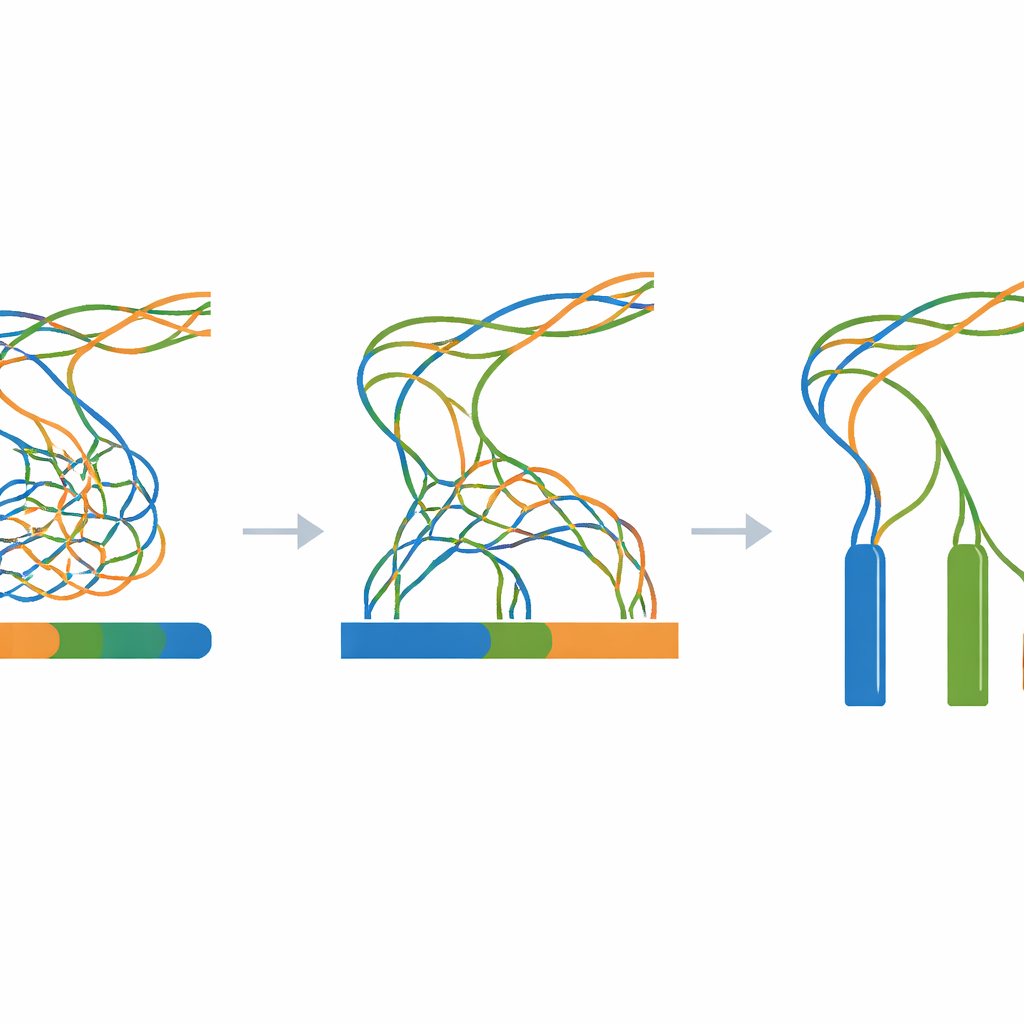
Прозрачный эталон для сложных геномов
Поскольку каждый этап синтетический и скриптован — от начального случайного шаблона до финальных сборок — исследователи могут воспроизвести весь рабочий процесс на любом стандартном компьютере с Linux, используя только открытое программное обеспечение. Архив на Zenodo, на который даёт ссылку статья, содержит шаблонный геном, все промежуточные мутировавшие последовательности, все смоделированные риды и все результаты сборок, а также логи и простые вспомогательные скрипты. Технические проверки подтверждают, что процесс мутаций ведёт себя ожидаемо, что смоделированные риды соответствуют заявленным длинам и покрытию, и что сборки демонстрируют ожидаемую картину: сильное чрезмерное схлопывание, когда три копии почти идентичны, и более ясное разделение по мере их расхождения.
Что это означает простыми словами
На бытовом языке эта статья предлагает контролируемую испытательную трассу для программ, которые пытаются восстановить три похожих «книги с инструкциями» из груды перемешанных фрагментов. Постепенно увеличивая различия между тремя книгами и систематически меняя ключевой параметр в процессе реконструкции, набор данных позволяет легко увидеть, когда и как современные методы терпят неудачу или добиваются успеха. Разработчики могут использовать его для настройки новых алгоритмов, а пользователи — лучше понимать, какие настройки работают лучше для триплоидных геномов. Хотя сама ДНК искусственная, выводы — о схлопывании, разделении и влиянии выбора параметров — напрямую применимы к реальным задачам декодирования сложных геномов многих важных видов.
Цитирование: Ootsuki, R. Minimum virtual dataset for reproducible triploid de novo genome assembly. Sci Data 13, 382 (2026). https://doi.org/10.1038/s41597-026-06779-2
Ключевые слова: сборка триплоидного генома, тестирование полиплоидов, синтетический набор ДНК, de novo сборка, оптимизация k‑mer