Clear Sky Science · ru
Крупномасштабный набор изображений клеток периферической крови для автоматизированного гематологического анализа
Почему важны снимки кровяных клеток
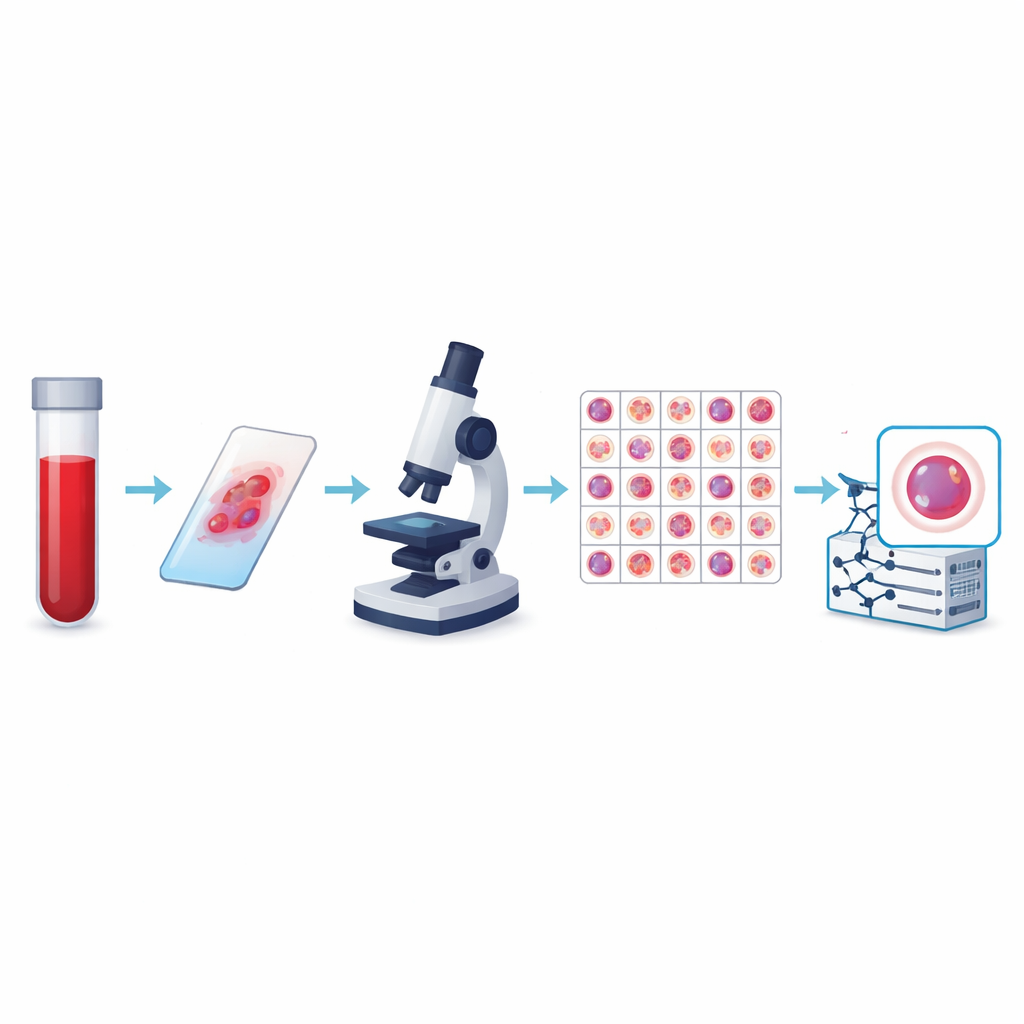
Каждый рутинный анализ крови скрывает микроскопический мир клеток, который может выявить инфекции, анемию или даже злокачественные заболевания крови задолго до появления явных симптомов. Традиционно врачи исследуют эти клетки невооружённым глазом под микроскопом — это тщательное, но трудоёмкое ремесло. В этом исследовании представлен очень большой, тщательно размеченный набор изображений кровяных клеток, предназначенный для обучения компьютеров автоматическому распознаванию этих клеток. Цель — сделать будущие анализы крови быстрее, более согласованными и доступными широкой аудитории, дав искусственному интеллекту визуальный опыт, необходимый для помощи врачам в точном чтении мазков крови.
От простого подсчёта к интеллектуальной визуализации
Белые кровяные клетки — ключевые защитники нашей иммунной системы, и их состав и внешний вид дают важные подсказки о состоянии здоровья. Увеличение числа определённых типов клеток может сигнализировать об инфекции или аллергии, тогда как внезапное появление незрелых «бластных» клеток может предупреждать о лейкемии. В лабораториях уже используются автоматические приборы для подсчёта клеток, но тонкие изменения формы по-прежнему часто требуют взгляда эксперта. Мнения людей-рецензентов могут расходиться, а поочерёдное обследование препаратов занимает время. По мере того как медицина всё больше опирается на цифровую визуализацию и искусственный интеллект, растёт потребность в больших, надёжных коллекциях изображений, которые смогут обучить компьютеры замечать эти характерные клеточные признаки с той же надёжностью, что и опытный гематолог.
Создание огромной библиотеки клеток крови
Авторы создали в настоящее время крупнейшую публичную коллекцию изображений клеток периферической крови, названную набором данных KU-Optofil PBC. Она содержит 31 489 высококачественных изображений отдельных клеток, распределённых по 13 группам, включая распространённых «защитников», таких как лимфоциты и сегментоядерные нейтрофилы, а также более редкие, но клинически важные типы — бласты, миелоциты и реактивные лимфоциты. Все изображения получены со стандартно окрашенных мазков крови, приготовленных в одной больнице с использованием одной и той же системы съёмки. Такая согласованность означает, что компьютеры, обучающиеся на этих данных, видят стабильное, хорошо контролируемое представление каждого типа клеток, а не набор несовместимых изображений.
Взгляд экспертов и тщательная отборка
Чтобы сделать набор данных надёжным, каждое изображение было промаркировано независимо двумя опытными лабораторными техниками, а при расхождениях решающее слово давал третий эксперт. Статистические проверки показали очень сильное согласие между рецензентами для каждого основного типа клеток, включая идеальное совпадение для некоторых категорий. Команда также применила строгие правила отбора изображений, отклоняя размытые, перекрывающиеся или плохо окрашенные клетки. Финальные изображения имеют одинаковый размер и цветовой формат, они организованы по папкам для обучения, валидации и тестирования, чтобы другие исследователи могли справедливо сравнивать алгоритмы. Дополнительные файлы связывают каждое изображение с анонимным пациентом, что позволяет проводить исследования, проверяющие, действительно ли модель обобщает знания от одного человека к другому.
Испытание моделей ИИ
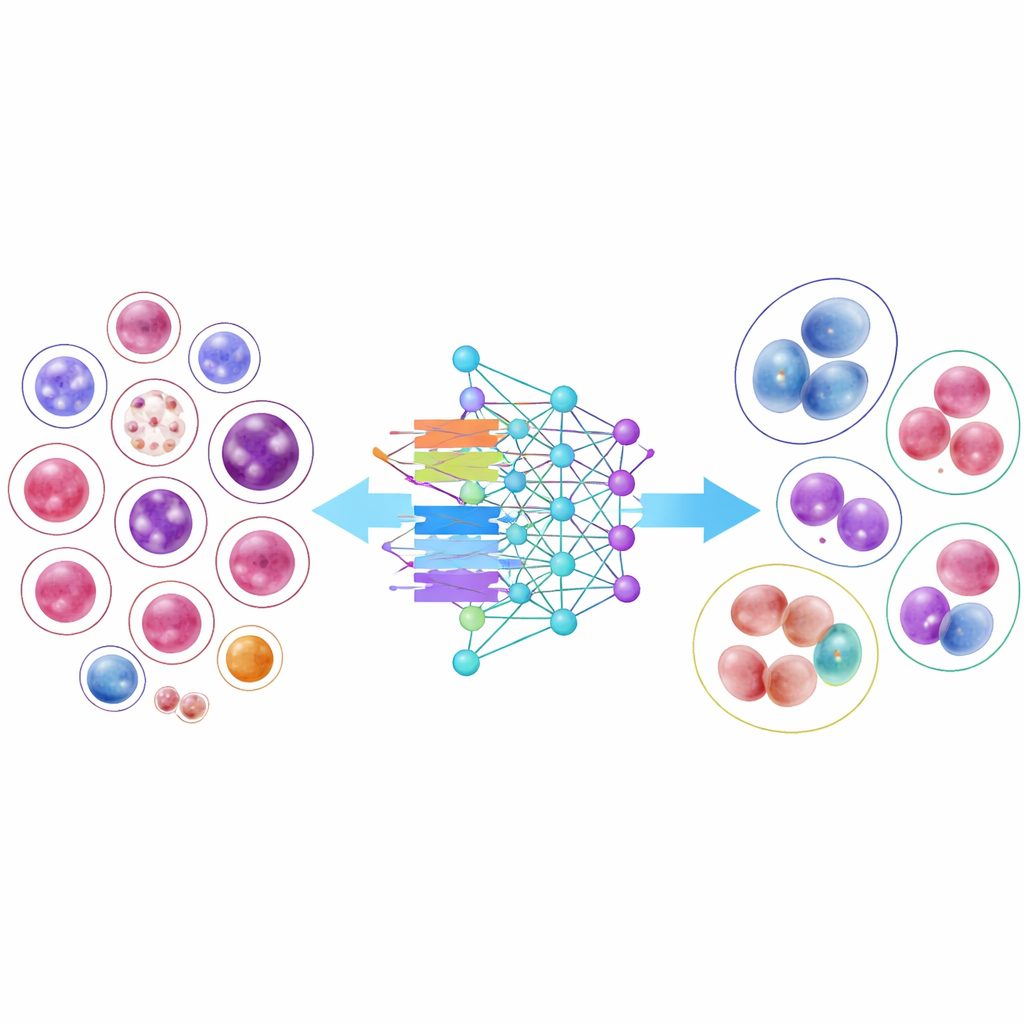
Чтобы продемонстрировать полезность этой библиотеки, исследователи обучили 14 современных моделей распознавания изображений, от классических сверточных нейронных сетей до более новых архитектур на основе трансформеров. Несколько компактных и эффективных моделей показали удивительно хорошие результаты, и одна архитектура, DenseNet-121, в среднем правильно классифицировала клетки более чем в 95 процентов случаев. Однако результаты также выявили важную реальную проблему: распространённые типы клеток с тысячами примеров распознавались почти идеально, тогда как очень редкие клетки, имеющие лишь несколько десятков изображений, оставались значительно труднее для классификации. Даже когда исследователи корректировали обучение, чтобы «обратить больше внимания» на эти дефицитные классы, общая точность падала, а прирост для редких типов был скромным, что подчёркивает сложность обучения на ограниченных примерах.
Что это означает для будущих анализов крови
Для неспециалистов ключевая мысль в том, что эта работа предоставляет тот самый визуальный материал, который нужен компьютерным системам, чтобы стать надёжными партнёрами в чтении мазков крови. Собрав большую, разнообразную и тщательно проверенную библиотеку изображений клеток крови и показав, что многие разные модели ИИ могут учиться на ней, авторы закладывают основу для инструментов, которые могли бы ускорить диагностику, снизить число ошибок человека и распространить уровень экспертного анализа в клиниках с меньшим количеством специалистов. В то же время смешанные результаты по редким типам клеток напоминают нам, что даже большие наборы данных имеют слепые зоны, и что улучшение ухода за пациентами с редкими или ранними стадиями заболеваний потребует дальнейшего расширения и уточнения этих коллекций изображений.
Цитирование: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Ключевые слова: изображения кровяных клеток, медицинский ИИ, гематология, глубокое обучение, медицинские наборы данных