Clear Sky Science · ru
StatLLM: набор данных для оценки работы больших языковых моделей в статистическом анализе
Почему это важно для повседневных пользователей данных
По мере того как инструменты искусственного интеллекта, такие как чат‑ассистенты, становятся частью повседневной работы, всё больше людей просят их считать данные, проводить эксперименты и анализировать результаты. Но когда ИИ пишет код для статистического исследования — например, проверяет эффективность нового медицинского лечения или исследует данные об успеваемости школ — как понять, что работа выполнена корректно? В этой статье представлен StatLLM, открытый набор данных, предназначенный для проверки того, насколько хорошо большие языковые модели справляются с реальными задачами статистического анализа, дающий исследователям и практикам более ясное представление о том, когда коду, написанному ИИ, можно доверять, а когда следует проявлять осторожность.
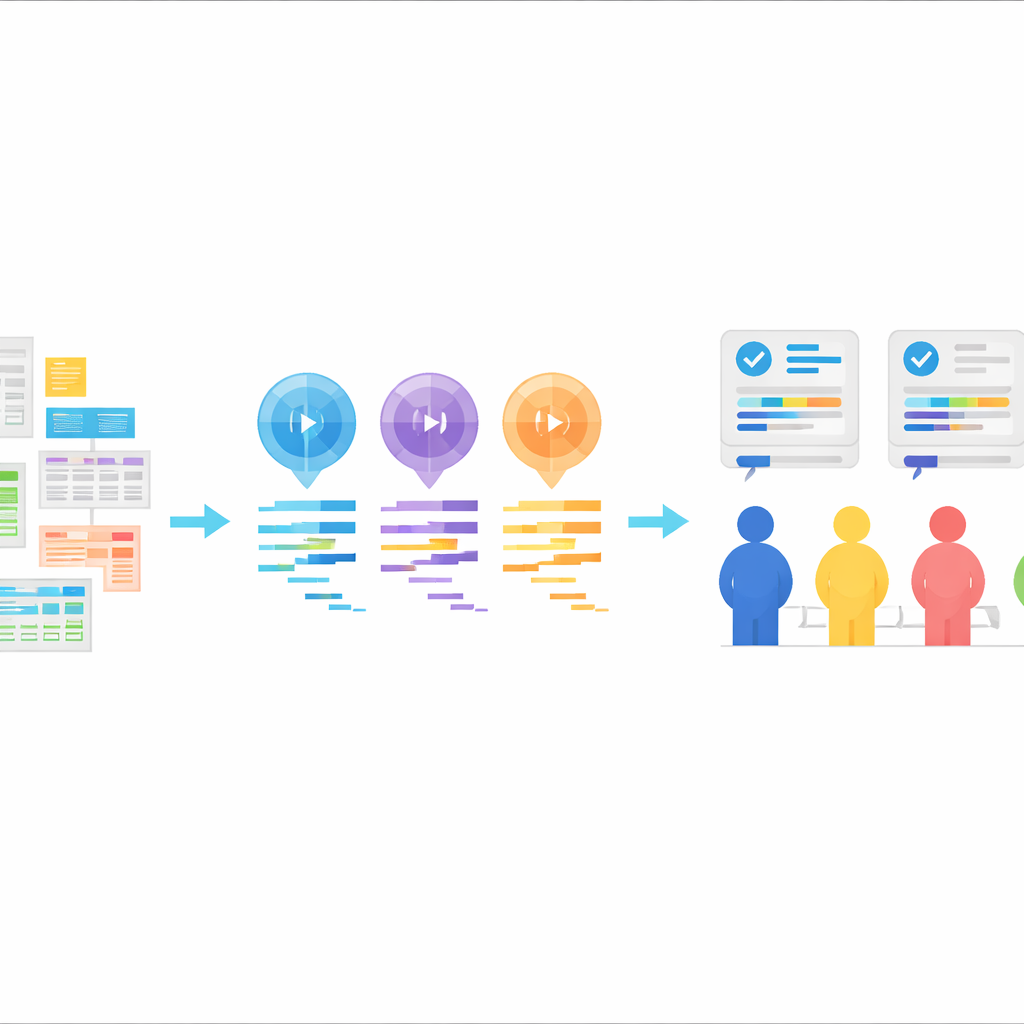
Новая испытательная площадка для кода статистики, сгенерированного ИИ
Сердце StatLLM — это тщательно собранная коллекция из 207 задач по статистическому анализу, составленная на основе 65 реальных наборов данных из таких областей, как образование, медицина, бизнес, финансы, инженерия и спорт. Каждая задача включает описание на простом языке, подробное пояснение набора данных и его переменных, а также короткий фрагмент кода SAS, написанный и проверенный людьми‑экспертами. Задачи охватывают то, чему мог бы научиться хороший студент бакалавриата или магистратуры по статистике: от простых сводок и графиков до регрессии, анализа выживаемости и более продвинутых методов. Это даёт реалистичную проверку в стиле учебной и прикладной практики, позволяя оценить, понимают ли ИИ‑инструменты практические вопросы и переводят ли их в корректные шаги анализа.
Даем ИИ написать код, затем оцениваем его работу
Используя эти задачи, авторы попросили три большие языковые модели — GPT‑3.5, GPT‑4 и Llama‑3.1 70B — сгенерировать код на SAS. Каждая модель получила одинаковые входные данные: описание задачи, описание набора данных, сам файл с данными и явную инструкцию сгенерировать код SAS. Модели использовались в «zero‑shot» режиме, то есть им не показывали примеры корректного кода SAS заранее. Ответы были очищены так, чтобы остался только код, без пояснений. Такая настройка имитирует типичную реальную ситуацию: пользователь описывает, что хочет, ИИ возвращает код, и этот код затем запускают в статистическом пакете.
Человеческие эксперты как золотой стандарт
Чтобы оценить, насколько хорош был код, написанный ИИ, команда организовала строгую человеческую экспертизу. Девять опытных пользователей SAS сформировали три группы, каждая из которых сосредоточилась на одной части оценки: логическая корректность и читаемость кода, способность кода выполняться без ошибок и то, отвечает ли полученный вывод на исходный вопрос ясно и точно. Для каждой задачи программы SAS от трёх моделей были перемешаны, чтобы рецензенты не знали, какая модель сгенерировала тот или иной код. Оценки выставлялись по пятибалльной шкале и комбинировались в общий итоговый балл, давая нюансированное представление о сильных и слабых сторонах на сотнях сочетаний модель–задача. Эти экспертные оценки теперь доступны вместе со всем кодом и задачами в наборе данных StatLLM.
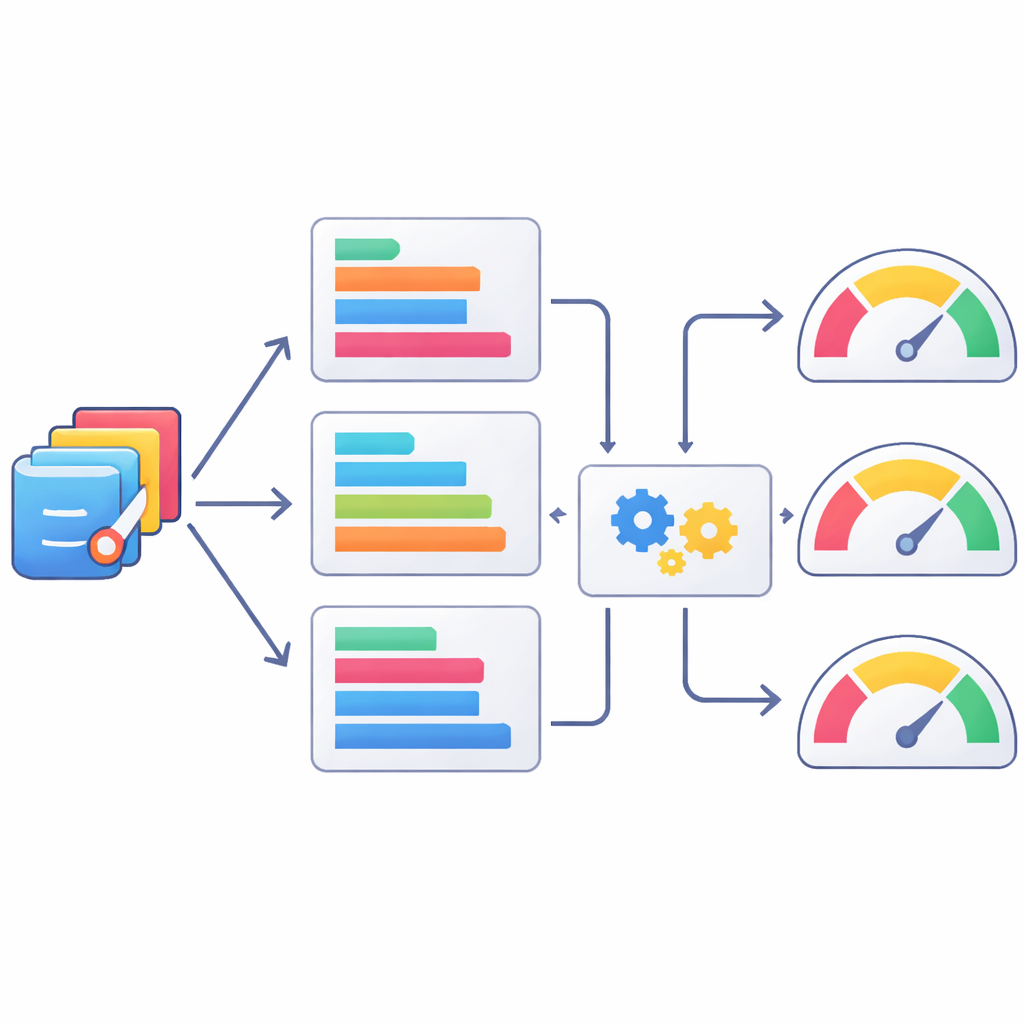
Обучение машин оценивать код как люди
Поскольку человеческая проверка медленна и дорога, авторы также исследовали, насколько автоматические текстовые метрики могут служить грубыми судьями качества статистического кода. Они сравнивали сгенерированные ИИ программы SAS с человечески верифицированными версиями, используя набор известных метрик обработки естественного языка, и проверяли, как эти метрики соотносятся с оценками экспертов. Некоторые метрики, например варианты ROUGE, отслеживающие совпадения в коротких последовательностях токенов, коррелировали с человеческими оценками лучше других, но все они были лишь умеренно согласованы с экспертным мнением. Команда пошла дальше и обучила модели машинного обучения предсказывать человеческие оценки на основе комбинаций этих метрик. Методы, такие как XGBoost, улучшали соответствие человеческим оценкам, но по‑прежнему далеко не идеально отражали суждения экспертов, что подчёркивает: автоматические метрики в лучшем случае являются частичными прокси.
Движение в сторону будущих инструментов статистики на базе ИИ
Помимо бенчмаркинга, авторы показывают, как StatLLM может поддерживать новые инструменты и направления исследований. Поскольку каждая задача описана в общих терминах, те же проблемы можно использовать для проверки генерации кода на других языках, таких как R или Python, или даже для комбинирования кода из разных языков. В статье подчёркиваются ансамблевые подходы, которые могут объединять разные ИИ‑решения для повышения надёжности, и демонстрируется прототип R Shiny‑приложения, где пользователи загружают набор данных и описание задачи, а система ИИ автоматически формирует и выполняет R‑код. StatLLM также предоставляет платформу для проектирования и тестирования следующего поколения статистического программного обеспечения, которое понимает инструкции на естественном языке при соблюдении чётких и измеримых стандартов.
Что это означает для использования ИИ в анализе данных
Для неспециалистов главный вывод таков: ИИ уже способен писать короткие фрагменты статистического кода — но надёжность далека от гарантированной, особенно для задач, выходящих за рамки простых примеров. StatLLM предлагает прозрачный и повторно используемый способ увидеть, насколько хорошо различные модели справляются с задачами, улучшить автоматические проверки их работы и разрабатывать более безопасные и устойчивые инструменты анализа данных. По мере появления более совершенных языковых моделей их можно подключать к этому живому бенчмарку, что поможет сохранять честность в оценке того, на что ИИ способен и что он пока делать не умеет в серьёзной статистической работе.
Цитирование: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Ключевые слова: большие языковые модели, статистический анализ, оценка кода, эталонный набор данных, программирование на SAS