Clear Sky Science · ru
Набор данных для распознавания именованных сущностей на китайском языке для нематериального культурного наследия
Почему защите живых традиций нужна «умная» обработка текстов
По всему миру живые традиции — такие как народная музыка, ремёсла и местные фестивали — рискуют постепенно исчезнуть из повседневной жизни. В Китае уже накоплено большое количество текстов, описывающих эти практики, но большинство из них находится на длинных веб‑страницах, которые людям и компьютерам трудно эффективно просматривать или анализировать. В этом исследовании представлен тщательно подготовленный набор данных на китайском языке и продвинутая модель искусственного интеллекта, способная автоматически выявлять ключевые сведения в таких текстах — например, названия ремёсел, имена мастеров, материалы и места. Вместе они предлагают новые инструменты для цифрового масштабного сохранения и изучения нематериального культурного наследия.
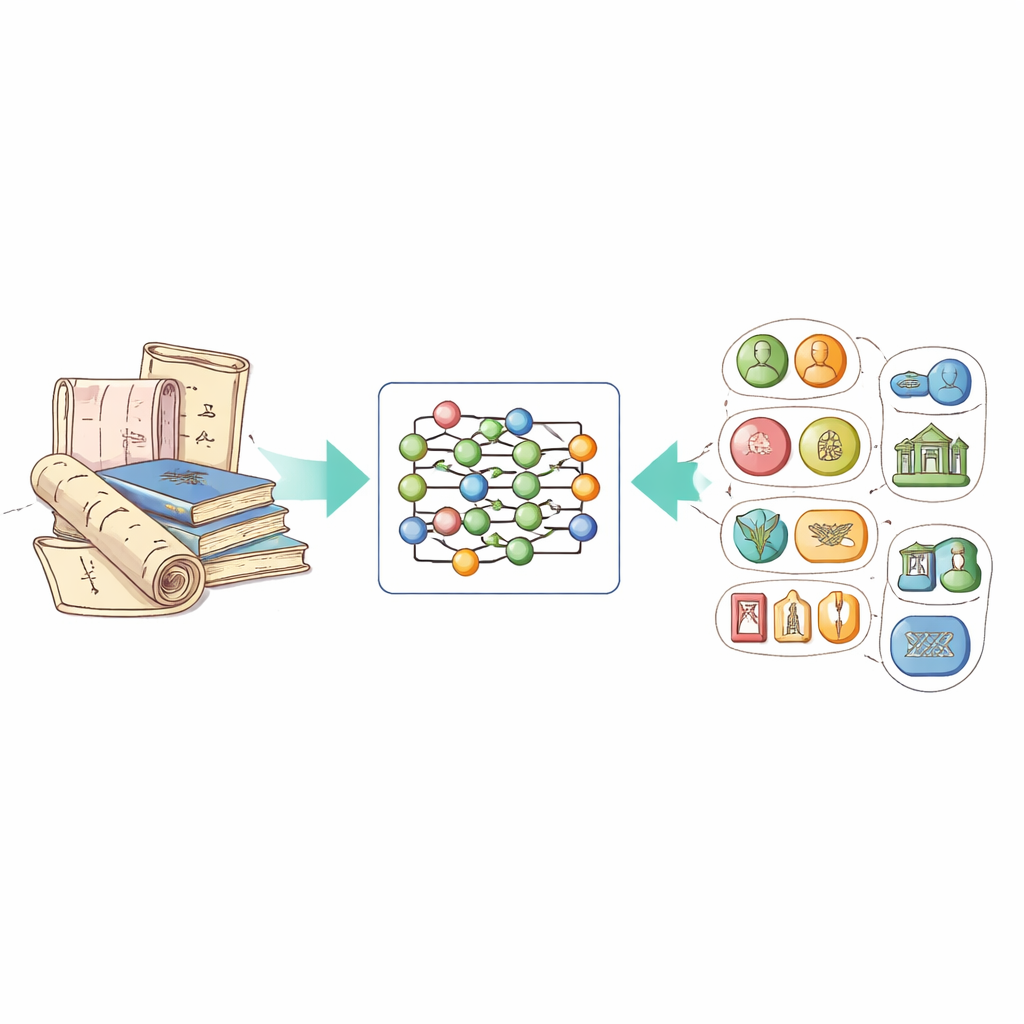
Преобразование неструктурированного текста в организованные знания
Ключевая идея работы — технология распознавания именованных сущностей, которая учит компьютеры выделять важные элементы в тексте: людей, места, время, организации и т.д. Для нематериального культурного наследия это также означает распознавание специальных типов сущностей, таких как названия проектов наследия, конкретные ремесленные приёмы и используемые материалы. Проблема в том, что до сих пор не существовало публичного набора данных, ориентированного на эту область на китайском языке, и универсальные системы испытывали трудности с яркими описаниями, поэтичной лексикой и региональными выражениями, встречающимися в описаниях наследия.
Создание специализированной коллекции текстов о наследии
Чтобы заполнить этот пробел, авторы собрали новый набор данных под названием ICH-NER с официального китайского портала нематериального культурного наследия. Они сосредоточились на записях, связанных с ремёслами — таких как традиционные ткани, керамика, металлообработка и резьба — потому что эти описания богаты деталями о процессах и материалах. После удаления уведомлений и дубликатов они выделили восемь ключевых категорий сущностей: названия объектов наследия, места, люди, организации, временные периоды, этнические группы, материалы и ремёсла. Каждый китайский иероглиф в текстах был помечен простым кодом, указывающим, относится ли он к сущности и если да — к какому типу. В целом набор данных содержит 7 779 образцов и более 21 000 размеченных сущностей, что делает его солидным эталоном для дальнейших исследований.
Тщательные правила для согласованной разметки
Поскольку для такого рода текстов не существовало стандартной классификации, исследователи сначала разработали подробные руководства на основе национальных списков наследия и официальных описаний. Они провели пилотную фазу для обработки сложных случаев, таких как топонимы, одновременно являющиеся частью названий проектов, или вложенные фразы, где одна сущность содержится внутри другой. Один обученный аннотаторм затем разметил весь набор данных с использованием ПО с открытым исходным кодом, многократно возвращаясь к ранее помеченным фрагментам для исправления несоответствий. Финальные данные разделены на обучающую и валидационную выборки, с учётом сохранения пропорций каждой категории сущностей и разнообразия региональных терминов и стилей письма в обеих частях.
Проектирование модели ИИ, настроенной на язык наследия
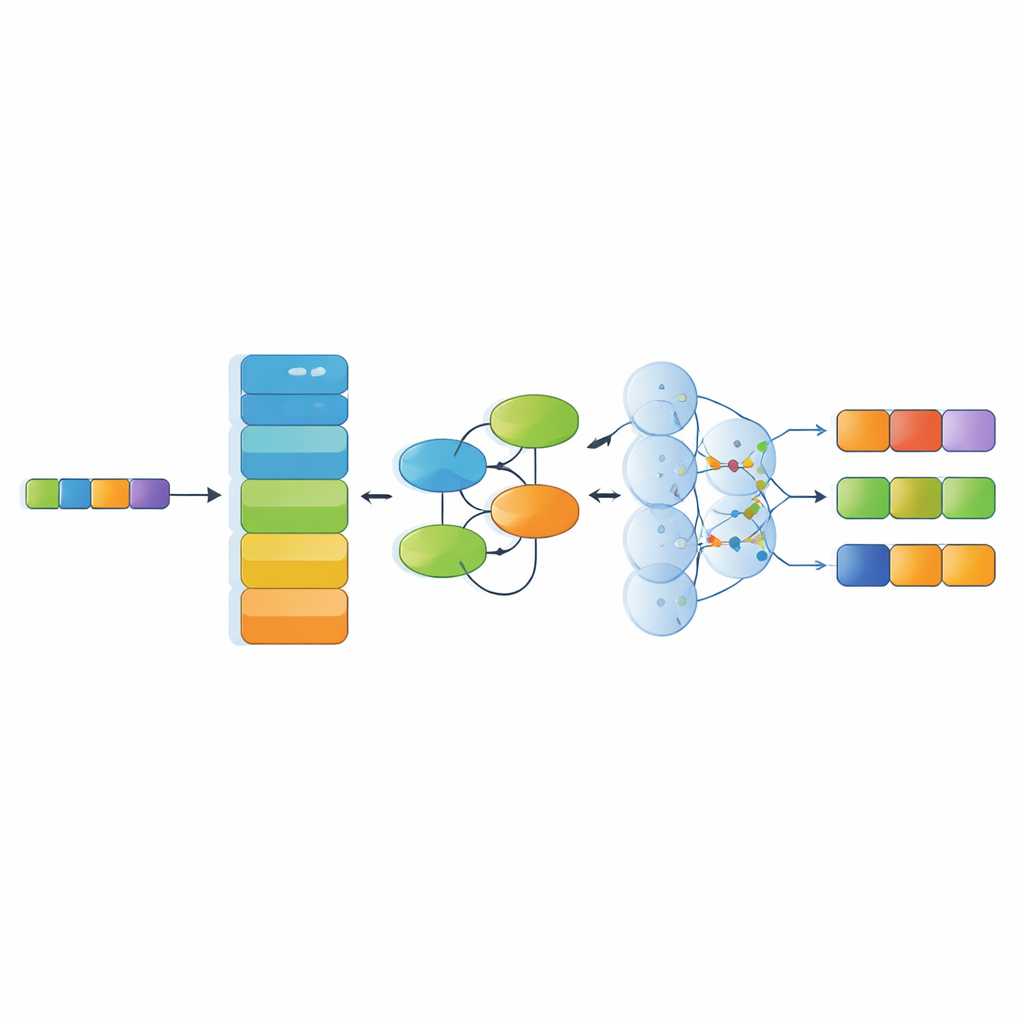
Параллельно с набором данных в исследовании предлагается специализированная модель распознавания, объединяющая несколько современных компонентов ИИ. Сначала мощный языковой энкодер (RoBERTa) преобразует китайские иероглифы в контекстно‑зависимые числовые представления, отражающие употребление слов в окружении. Далее модуль сети Колмогорова–Арнольда (KAN) обучается выявлять тонкие нелинейные паттерны — например, какие материалы склонны сочетаться с определёнными приёмами или регионами. Слой многоголового внимания затем анализирует отношения в пределах всего предложения с разных точек зрения, и, наконец, декодер выбирает наиболее вероятную последовательность меток сущностей. Эта архитектура рассчитана на обработку длинных, сложных предложений, насыщенных метафорами и слоистыми культурными отсылками.
Насколько хорошо система понимает тексты о наследии
Авторы сравнили свою модель с несколькими сильными базовыми методами, часто используемыми в лингвистических исследованиях, включая системы на основе рекуррентных сетей, решётчатые структуры для китайского текста и недавний подход, который рассматривает сущности как сегменты, уточняемые поэтапно. На наборе ICH-NER методы, опирающиеся на современные предобученные языковые модели, явно превзошли старые подходы. Их комбинированная система RoBERTa–KAN–attention–decoder показала наилучший общий баланс точности и полноты, особенно в сложных категориях, таких как материалы, организации и ремёсла, где данных относительно мало, а описания часто содержат сложные или неоднозначные формулировки.
Что это значит для живой культуры в цифровую эпоху
На практике новый набор данных и модель упрощают извлечение того, кто, что, где и когда из богатых описаний традиционных ремёсел. Эта структурированная информация может быть использована в графах знаний, интерактивных картах или поисковых инструментах, помогающих исследователям, хранителям и широкой публике проследить, как распространялись техники, какие семьи или регионы формировали ремесло и как практики менялись со временем. Несмотря на техническую направленность работы, её влияние — человеческое: она предлагает способ превратить разбросанные, текстово‑связанные описания живых традиций в организованные знания, которые лучше поддерживают сохранение и понимание нематериального культурного наследия.
Цитирование: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Ключевые слова: нематериальное культурное наследие, распознавание именованных сущностей, обработка китайского языка, культурные наборы данных, цифровое сохранение