Clear Sky Science · ru
Аннотированный набор данных микроскопии по Gram-окраске положительных гемокультур
Почему важно быстро получать ответы при инфекции
Когда бактерии или грибы попадают в кровоток, каждый час без адекватного лечения может решить вопрос жизни и смерти. Врачи опираются на быстрый лабораторный тест — Gram-окраску — чтобы понять, какой тип возбудителя присутствует, и выбрать раннюю антибактериальную терапию. Однако чтение этих окрашенных микроскопических препаратов — это квалифицированная ручная работа, которая занимает время и может отличаться у разных специалистов. В этом исследовании представлен новый тщательно аннотированный набор изображений реальных клинических препаратов из гемокультур, созданный для того, чтобы помочь компьютерам научиться автоматически распознавать Gram-окраску и поддерживать более быструю и надежную помощь.
Преобразование реальных больничных препаратов в данные
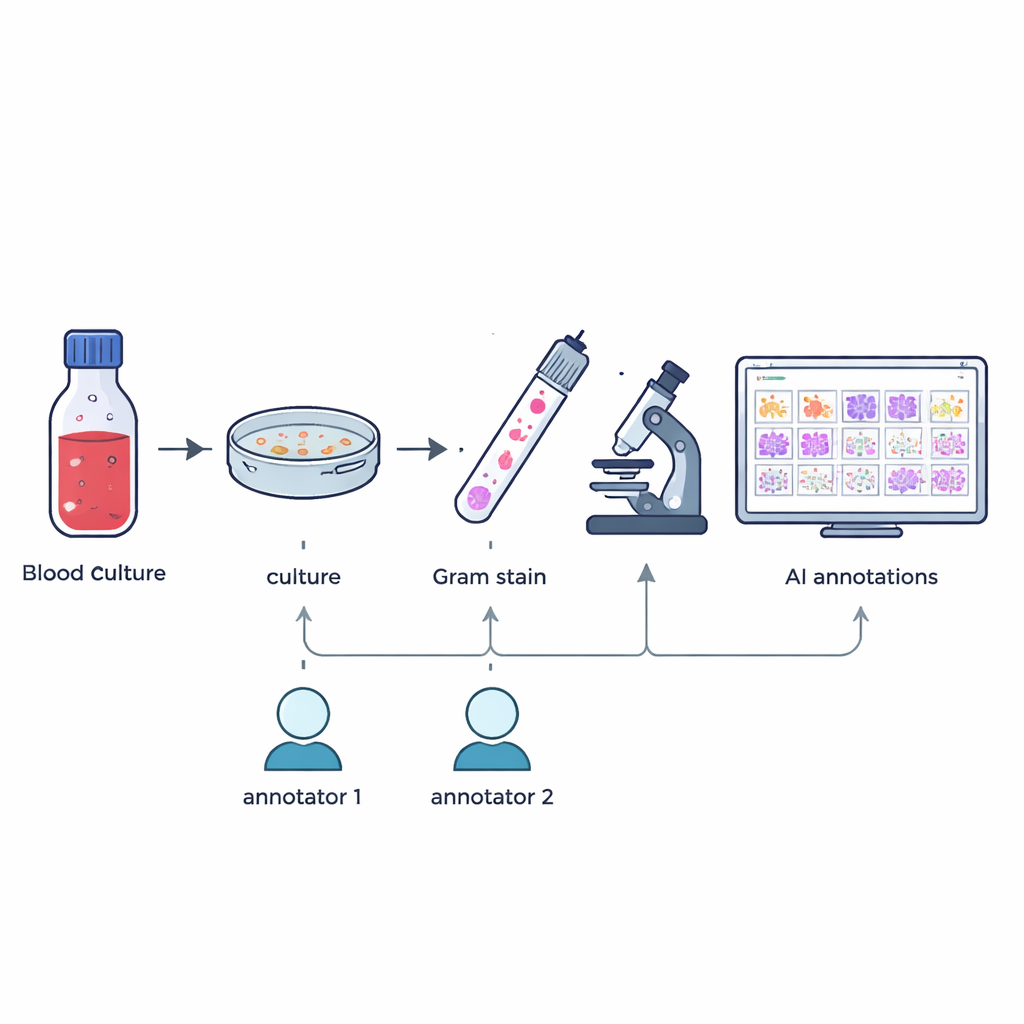
Исследователи собрали 57 различных видов бактерий и грибов, выращенных из положительных флаконов гемокультур в рамках рутинной работы больницы. С января по май 2024 года, как только гемокультура зарегистрировала позитивный сигнал, персонал готовил мазки, окрашенные по Gram, на стеклах и подтверждал вид с помощью высокоточного метода идентификации MALDI-TOF масс-спектрометрии. Не изменяя обычные протоколы и не собирая дополнительных образцов, команда затем делала цифровые снимки в высоком разрешении типичных полей при 100× погружении в масло, получив 505 крупных цветных изображений, которые отражают то, что видят специалисты на практике.
Тщательная разметка мельчайших форм
Создание полезного обучающего набора для искусственного интеллекта требует точного указания положения каждого микроба на изображении. Два опытных микробиологических техника независимо друг от друга обводили прямоугольниками отдельные микробные клетки или их скопления на каждом изображении, руководствуясь только тем, что они видели под микроскопом. Специальное программное обеспечение сравнило два набора разметки: боксы, которые перекрывались в достаточной степени, объединялись, а любые расхождения или несоответствия помечались. Старший эксперт с более чем 20-летним опытом затем вручную проверял такие случаи. Этот многоступенчатый процесс дал 7 528 проверенных аннотаций, которые выделяют кокки (округлые клетки), бациллы (палочковидные клетки) и грибы, при этом исключая частичные или сомнительные объекты.
Что содержит набор данных
Готовый ресурс сочетает несколько слоев информации. Все 505 изображений предоставлены в виде JPEG файлов высокого разрешения, а окончательные, верифицированные экспертами боксы сохранены в стандартном формате COCO JSON, широко используемом в исследованиях компьютерного зрения. Дополнительные файлы связывают каждое изображение с видом микроорганизма, его Gram-статусом (положительный или отрицательный), широкой морфологической группой, типом флакона гемокультуры, из которого был образец, и временем, потребовавшимся для появления положительного сигнала. Поскольку каждое изображение содержит только один вид, все боксы на данном изображении имеют одинаковые биологические свойства. Пользователи могут выбрать единый большой файл аннотаций или отдельные файлы для каждого изображения, а также включен простой Python-скрипт для визуализации любого изображения с наложенными бокcами.
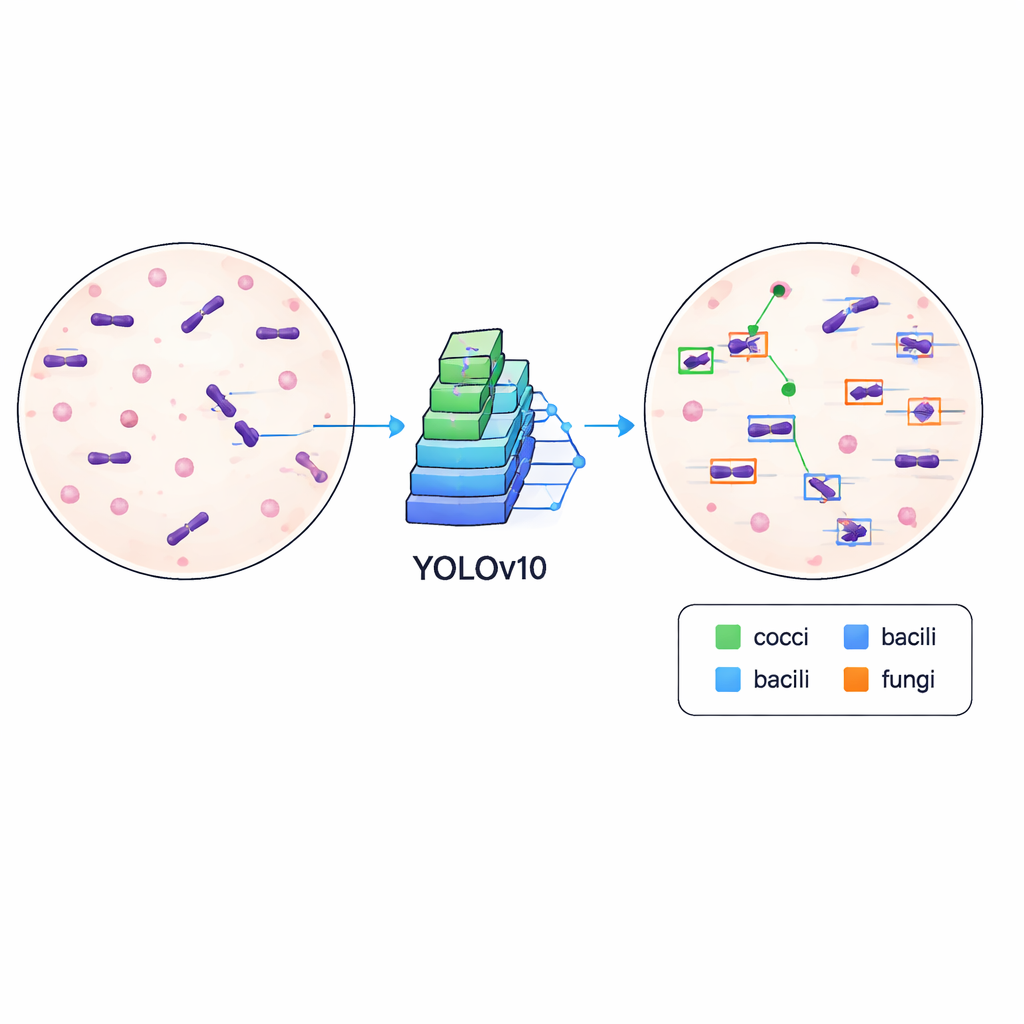
Обучение компьютеров распознавать микробы
Чтобы показать, что набор данных не только аккуратно организован, но и практичен, авторы обучили современный алгоритм детекции объектов, известный как YOLOv10, находить и классифицировать микробы на изображениях. Они разделили данные на тренировочную и валидационную выборки и запустили обучение модели на 500 эпох на высокопроизводительной графической плате, отслеживая, насколько хорошо она учится точно рисовать боксы и различать типы клеток. Обученная система достигла среднего показателя точности (mean average precision) примерно 84,6% при стандартном пороге совпадения, что указывает на способность надежно локализовать и маркировать микробы при разнообразии внешнего вида препаратов, включая различия в интенсивности окраски, мусоре на фоне и резкости.
Как можно использовать этот ресурс
Поскольку данные оформлены в общепринятых форматах, они легко интегрируются в существующие конвейеры компьютерного зрения. Исследователи могут сначала обучить систему просто отличать истинные микробы от мусора, что поможет лабораториям отфильтровывать ложноположительные сигналы гемокультур. Также возможно группировать микробы по широким морфологическим формам, что соответствует потребностям клиницистов для раннего, так называемого «уровня 1» отчета, который направляет начальный выбор антибиотиков. Более амбициозная задача — различать отдельные виды по тонким визуальным признакам. Авторы отмечают ограничения: некоторые клетки сгруппированы, часть препаратов представлена одним источником на вид, и резкость может варьировать — как и в реальной практике. Тем не менее каждая включенная аннотация была тщательно проверена, что делает набор данных надежной отправной точкой.
Что это означает для пациентов
Проще говоря, эта работа превращает рутинные препараты гемокультур в общую обучающую площадку для интеллектуального ПО. Делая доступными как изображения, так и экспертные разметки, исследование снижает барьер для команд по всему миру, которые хотят создавать и тестировать ИИ-инструменты для быстрого и последовательного чтения Gram-окраски. Хотя такие системы не заменят микробиологов, они могут помочь быстрее выявлять опасные инфекции, уменьшать ошибки интерпретации и способствовать более рациональному применению антибиотиков. Для пациентов это может означать более быстрое и точное лечение в критические моменты.
Цитирование: Yi, Q., Gou, X., Zhu, R. et al. An annotated dataset of Gram stains from positive blood cultures. Sci Data 13, 294 (2026). https://doi.org/10.1038/s41597-026-06651-3
Ключевые слова: инфекции кровотока, Gram-окраска, набор данных медицинских изображений, искусственный интеллект, диагностика в микробиологии