Clear Sky Science · ru
Предотвращение «могил» данных протеомики через коллективную ответственность и участие сообщества
Почему ваши медицинские данные не должны превращаться в цифровые кладбища
Современная медицина всё больше опирается на гигантские наборы данных, описывающие тысячи белков, работающих в наших клетках. Эти файлы часто выкладывают в открытый доступ в интернете, с обещанием, что другие учёные смогут перепроверить результаты или задать новые вопросы без проведения дополнительных экспериментов. Но если данные опубликованы в запутанных форматах, без ключевых деталей или зависят от проприетарного ПО, они превращаются в «могилы данных»: видимые для всех, но практически непригодные для использования. В этой статье показано, как университетский курс превратил студентов в детективов данных, чтобы выявить эту скрытую проблему, — и предлагаются простые исправления, которые могли бы сделать общие данные действительно пригодными для повторного использования.
Учиться науке, повторяя настоящие исследования
В Хельсинкском университете студентов магистратуры на курсе по протеомике на основе масс‑спектрометрии попросили выполнить амбициозную задачу: выбрать реальные общедоступные наборы данных по белкам из крупного репозитория и попытаться воспроизвести опубликованные результаты. Работая малыми командами, они скачали шесть проектов из сети ProteomeXchange, где хранятся результаты масс‑спектрометрии из многих лабораторий мира. Используя общий аналитический конвейер на языке R, студенты следовали тем же общим шагам, что и оригинальные исследователи: идентификация белков, измерение их содержания, очистка данных и проверка, какие белки меняются между условиями, например при болезни и в здоровой ткани.
Большие обещания, отсутствующие инструкции
Студенты быстро обнаружили, что «открыто» не всегда значит «повторно используемо». Во всех случаях отсутствовали или были трудны для поиска важнейшие инструкции. Ключевые связи между образцами и файлами данных не были описаны в простом машиночитаемом формате, поэтому командам приходилось догадываться, какие «сырые» файлы соответствуют каким биологическим группам, читая статьи и расшифровывая имена файлов. Детали о том, как контролировались ложноположительные срабатывания — например использование специальных «декой»-последовательностей белков — отсутствовали, что делало невозможной строгую оценку надёжности заявленных списков белков. В нескольких проектах основные результаты были «заперты» в проприетарных форматах файлов или зависели от коммерческого ПО, к которому у студентов не было доступа, вынуждая их заново выполнять большие части анализа с нуля.
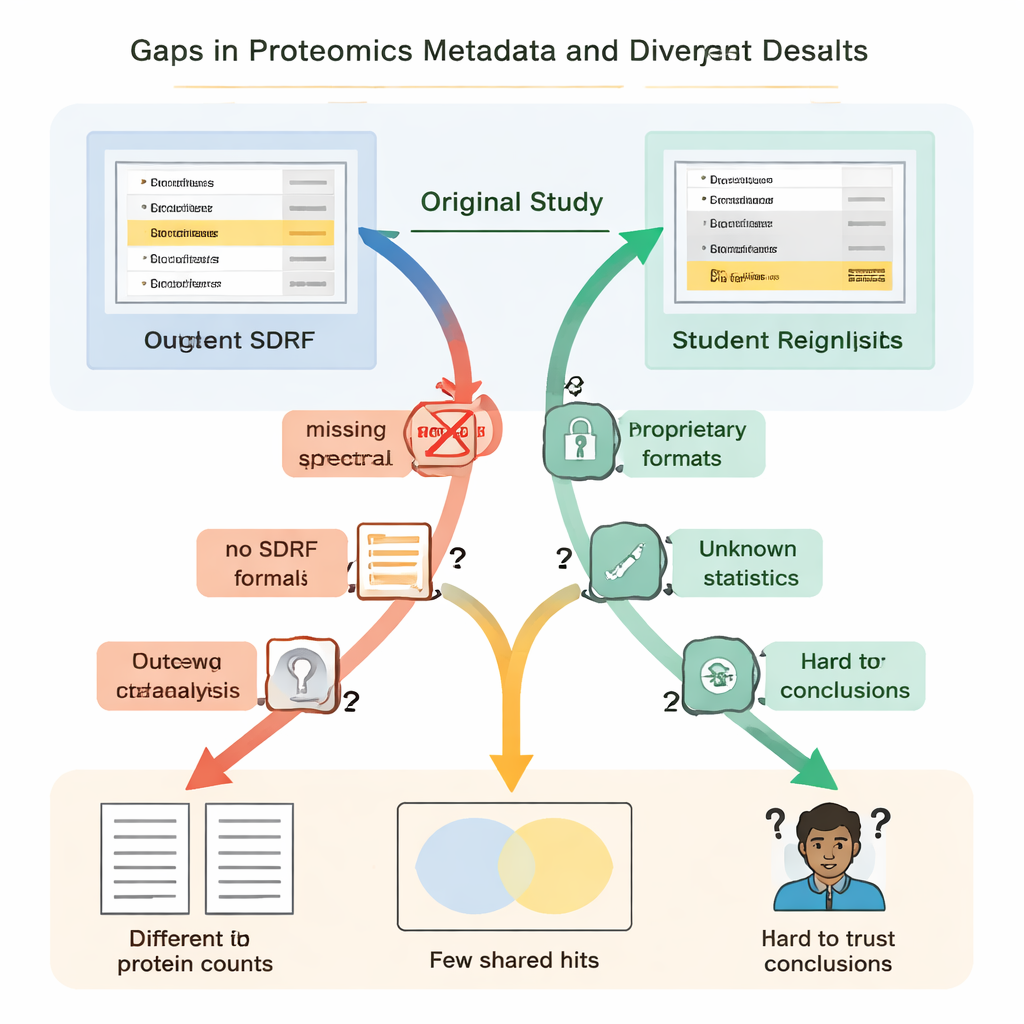
Когда мелкие пробелы дают большие расхождения
Эти пробелы были не просто неудобствами; они приводили к драматически разным научным результатам. В одном исследовании почечной болезни оригинальные авторы указали чуть менее пяти тысяч белков, тогда как переработка студентами — с использованием открытого инструмента и самостоятельно собранной спектральной библиотеки — выявила более тринадцати тысяч. Белок, выделенный в оригинальной статье как особо значимый, не выглядел убедительно в исходном файле идентификации и вовсе не обнаруживался в рабочем процессе студентов. В другом случае оригинальное исследование перечисляло 108 белков, меняющихся между условиями, но студенты, работая с теми же «сырыми» данными, но без полной информации о том, как выполнялась оригинальная статистика, смогли уверенно отметить лишь 11. В других проектах отсутствие биологических реплик в загруженных файлах делало корректное статистическое тестирование вовсе невозможным.
Что должен содержать по-настоящему «повторно используемый» набор данных
Из этих шести практических примеров вырисовалась ясная картина: основные барьеры для воспроизводимости вовсе не в самих масс‑спектрометрах, а в том, как результаты упакованы и распространены. Авторы утверждают, что каждый набор данных по протеомике должен сопровождаться минимальным пакетом для повторного анализа. В него должны входить «сырые» данные и открытые форматы результатов в соответствии с общепринятыми стандартами; стандартизованная таблица, связывающая каждый образец с его экспериментальными условиями; базовые сводки по контролю качества; любые спектральные библиотеки или файлы последовательностей белков, необходимые для повторного поиска; а также полные параметры анализа и код, желательно сохранённые вместе с версионированными контейнерами программного обеспечения. Репозитории, журналы и рецензенты могли бы помочь, подталкивая или требуя от авторов предоставлять этот пакет заранее, чтобы другим не приходилось восстанавливать рабочий процесс по разбросанным подсказкам.
Обучая учёных и одновременно исправляя систему
Сам курс выполнял двойную задачу. Для студентов он предлагал практический способ освоить сложные методы протеомики, статистику и программирование, одновременно показывая, насколько хрупкими могут быть опубликованные выводы при неполной документации. Для широкой научной общественности борьба студентов стала стресс‑тестом текущих практик обмена данными, чётко выявив, где именно метаданные и записи анализа оказываются недостаточными. Авторы предлагают, чтобы подобные курсы запускали и в других местах, превращая аудитории в механизмы контроля качества, которые постоянно продвигают более ясные и прозрачные данные.
От «могил данных» к живым ресурсам
Проще говоря, статья делает вывод, что многие наборы белковых данных, ныне лежащие в публичных репозиториях, рискуют превратиться в цифровые кладбища — дорогостоящие эксперименты, результаты которых нельзя надёжно проверить или развить дальше. Однако решение относительно простое: рассматривать метаданные, открытые форматы и общий код как неотъемлемые части эксперимента, а не как последумки. Если исследователи, рецензенты и репозитории коллективно будут настаивать на простом, хорошо задокументированном пакете при публикации данных протеомики, эти наборы останутся «живыми»: готовыми к повторному анализу, объединению с новыми исследованиями и использованию для укрепления доказательной базы биомедицинских открытий.
Цитирование: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
Ключевые слова: протеомика, воспроизводимость данных, открытая наука, масс-спектрометрия, обмен исследовательскими данными