Clear Sky Science · ru
Извлечение отношений на основе трансформеров и нормализация понятий с использованием аннотированного корпуса клинических исследований
Помочь врачам быстрее находить подходящих пациентов
Любое клиническое исследование зависит от поиска пациентов, соответствующих длинному списку медицинских состояний, назначений и временных ограничений. Сегодня врачам часто приходится вручную просматривать электронные медицинские карты и описания исследований — это медленно и подвержено ошибкам. В этой статье представлен большой, тщательно проверенный набор испанских текстов клинических исследований и показано, как современные методы искусственного интеллекта могут преобразовать неструктурированный язык в организованные данные, прокладывая путь к более быстрому, справедливому и точному медицинскому исследованию.
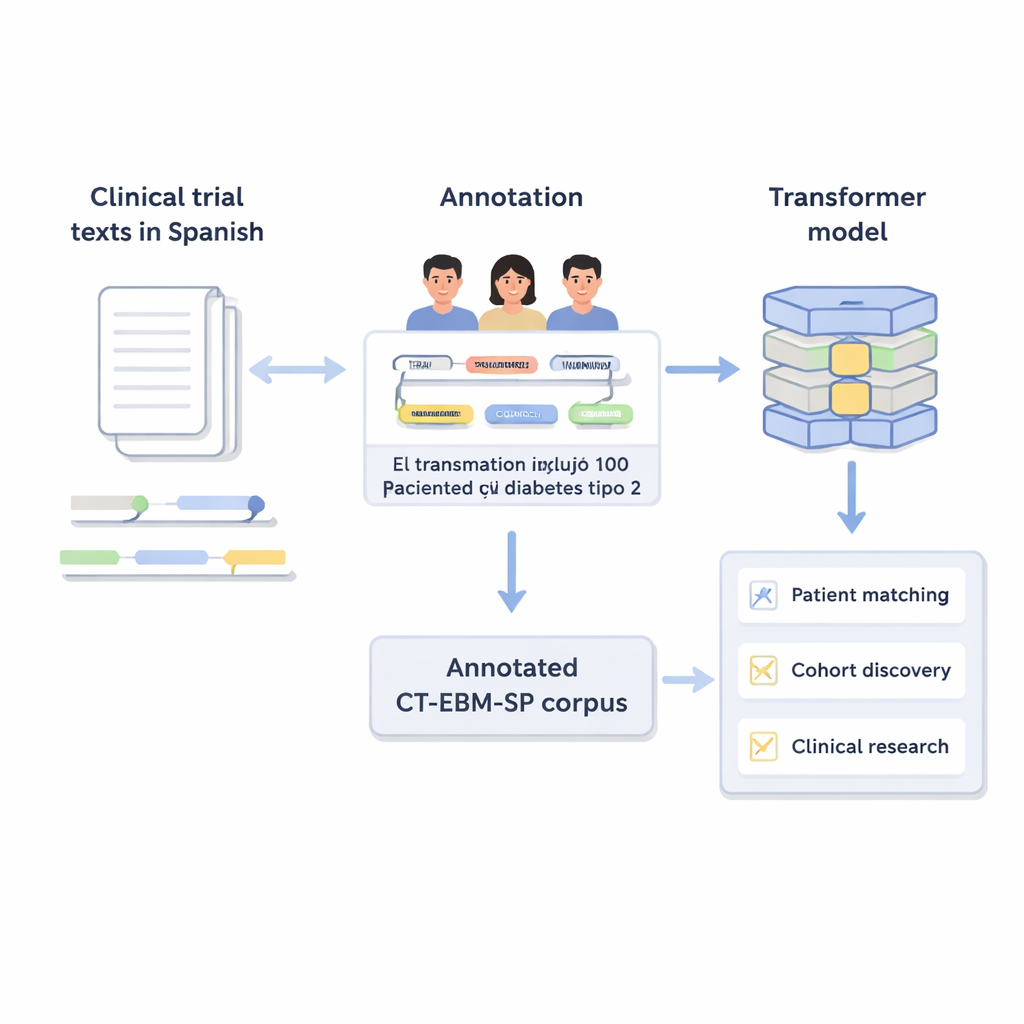
Преобразование свободного текста в организованную информацию
В описаниях клинических исследований указывается, кто может и кто не может участвовать, используя повседневную медицинскую лексику: возрастные ограничения, перенесённые заболевания, результаты анализов и назначенные лечения. Компьютерам сложно работать с таким свободным текстом. Авторы создали версию 3 корпуса CT‑EBM‑SP — набор из 1200 испанских текстов клинических исследований, содержащих почти 300 000 слов. Эксперты-человеки просмотрели эти тексты и пометили 23 типа медицинских сущностей, таких как заболевания, препараты, результаты тестов и выражения времени, а также маркеры отрицания (например, «sin antecedentes de») и неуверенности. Они также пометили 11 атрибутов, фиксирующих подробности, например произошло ли событие в прошлом или будущем и произошло ли оно у пациента или члена семьи.
Сделать медицинские термины единым языком
Одна из основных проблем в медицине — один и тот же концепт может быть записан разными способами. Для решения этой задачи команда связала большинство помеченных сущностей со стандартизированными кодами из Unified Medical Language System (UMLS), огромного многоязычного медицинского словаря. Этот шаг, называемый нормализацией понятий, означает, что разные написания или фразы указывают на один уникальный идентификатор. Например, несколько вариантов «25‑гидроксивитамина D» сопоставляются с одной концепцией UMLS. В сумме корпус включает более 87 000 сущностей и более 68 000 отношений, и около 82% сущностей были успешно нормализованы. Два эксперта независимо проверяли эти соответствия, добившись очень высокой согласованности, что указывает на надёжность аннотаций.
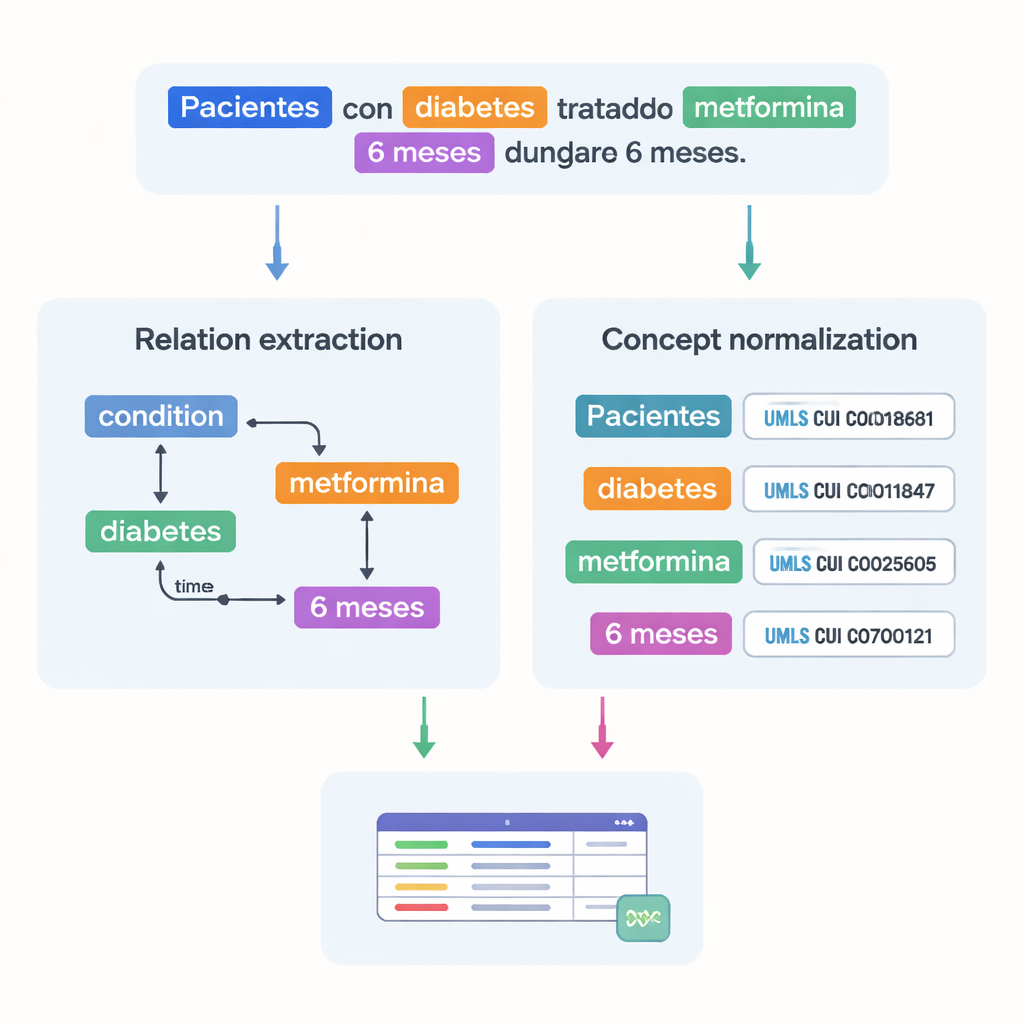
Фиксация связей между медицинскими фактами
Помимо перечисления медицинских терминов, набор данных фиксирует, как они связаны друг с другом. Авторы разработали 18 типов отношений, отражающих важные в исследованиях шаблоны, например какая доза относится к какому препарату, как долго длится лечение или какое состояние испытывает пациент. Временные отношения показывают, происходит ли одно событие до или после другого, а другие связи отмечают, где в организме проявляется заболевание или выражает ли фраза отрицание или предположение. Вместе эти отношения позволяют компьютерам строить графы состояния пациента — кто такой пациент, какое у него состояние, какое лечение он получает и в какие сроки — вместо простого распознавания изолированных слов.
Обучение и тестирование современных моделей ИИ
Чтобы показать практическую полезность корпуса, авторы дообучили несколько моделей ИИ на основе трансформеров, включая многоязычные версии BERT и RoBERTa. Они обучали модели для двух задач: извлечение отношений, которое учится восстанавливать связи между сущностями, и нормализация медицинских понятий, которая сопоставляет текст с кодами UMLS. По задаче извлечения отношений лучшая модель достигла F1-показателя близкого к 0.88, что означает корректное выявление большинства связей при относительно небольшом числе ошибок. Для нормализации понятий многоязычная модель SapBERT, использованная без дополнительного обучения, правильно угадывала точную концепцию с первой попытки почти в 90% случаев. Эти результаты показывают, что хорошо аннотированные корпуса среднего размера могут обеспечивать точные и эффективные модели даже без гигантских универсальных языковых систем.
Почему этот ресурс важен для будущей помощи
Корпус CT‑EBM‑SP и сопутствующие модели создают основу для инструментов, которые могут автоматически разбирать испанские тексты клинических исследований, сопоставлять их с медицинскими записями пациентов и поддерживать поиск когорт в больницах. Поскольку данные выровнены по международным медицинским стандартам и тщательно проверены экспертами, они также могут помочь в создании аналогичных ресурсов для других языков с меньшим объёмом цифровых инструментов. Простыми словами, эта работа направлена на то, чтобы правильным пациентам было проще и безопаснее предлагать подходящие исследования, ускоряя медицинские открытия и снижая нагрузку на медицинских специалистов.
Цитирование: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Ключевые слова: клинические испытания, обработка медицинских текстов, испанское здравоохранение, модели трансформеров, медицина, основанная на доказательствах