Clear Sky Science · ru
Данные о сценах в фильмах из Amazon X-Ray на рынке США в сочетании с IMDb
Почему сцены в фильмах важны для понимания культуры
Фильмы формируют наше восприятие мира, однако большинство исследований кино фокусировалось на кассовых сборах, основных жанрах или звездности, а не на том, что действительно разворачивается на экране от сцены к сцене. В этой статье представлен новый набор данных, который позволяет исследователям рассматривать материал на уровне отдельных сцен, персонажей и реплик более чем трех тысяч фильмов, транслировавшихся в США на Amazon Prime Video. Комбинируя функцию X-Ray от Amazon с базой данных Internet Movie Database (IMDb), авторы предлагают подробную, стандартизованную карту того, кто появляется где и когда в каждом фильме, что открывает путь к более глубоким исследованиям представительства, повествования и даже систем искусственного интеллекта, обучающихся на видео.
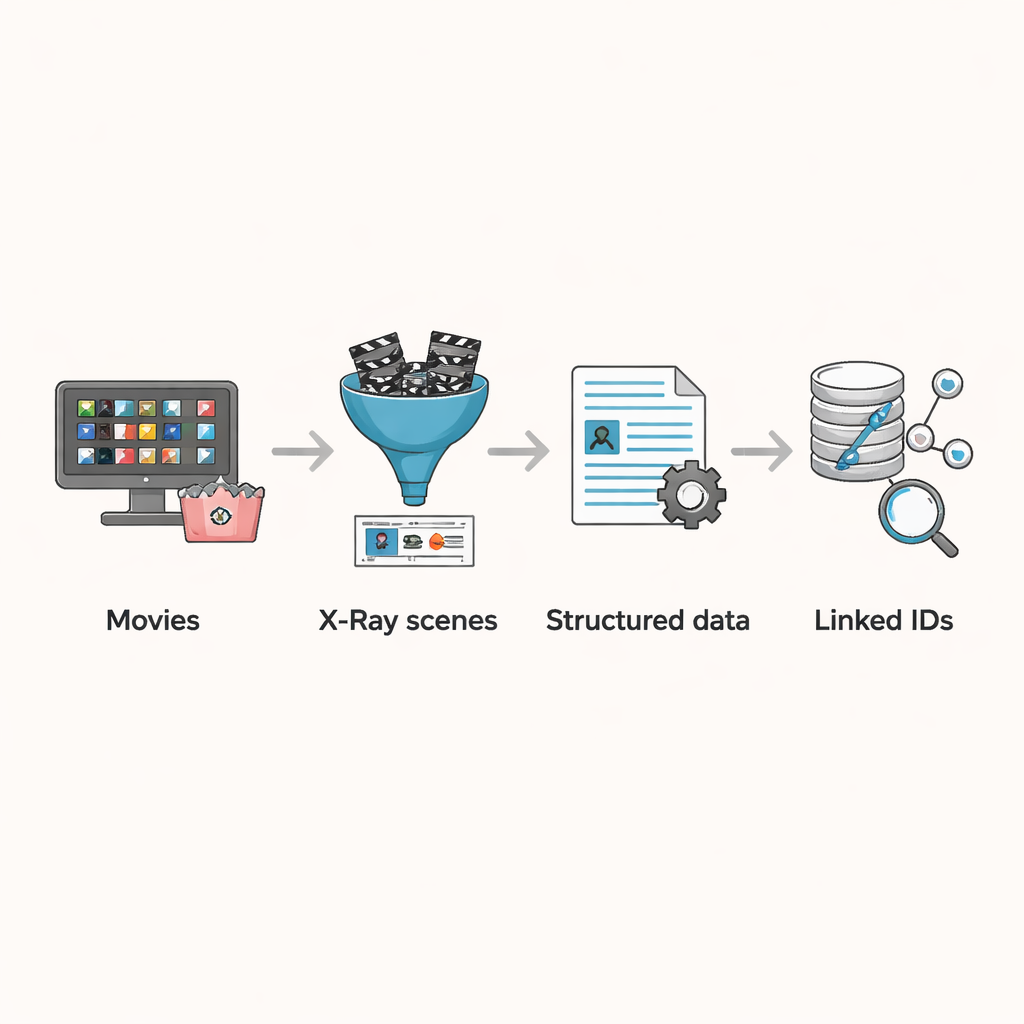
От черновых сценариев к готовым сценам
До сих пор большинство масштабных исследований кино опирались на сценарии или файлы субтитров. Эти источники полезны, но несовершенны. Сценарии часто представляют собой ранние версии, которые отличаются от финального монтажа, и в них могут отсутствовать второстепенные персонажи или поздние правки. Субтитры фиксируют произнесенные реплики, но не учитывают немых персонажей, массовку и чисто визуальное повествование — например, задержку камеры на лице героя. Из-за этих пробелов предыдущие попытки отслеживать, кто взаимодействует с кем на экране или как представлены разные группы, приходилось делать на основе текста, что может приводить к ошибкам в идентификации персонажей и их отношений.
Преобразование X-Ray в пригодные для исследований данные
Функция X-Ray от Amazon предлагает способ обойти эти проблемы. Когда зритель ставит фильм на паузу, X-Ray показывает, какие актеры и персонажи в данный момент присутствуют на экране — информация, которая курируется и привязана непосредственно к финальной отредактированной версии фильма. Авторы создали конвейер для сбора этих данных на уровне сцен для 3 265 фильмов, доступных в каталоге Prime Video в США по состоянию на август 2023 года. Они сначала собрали все фильмы, включенные в подписку Prime, отфильтровали те, для которых отсутствует информация X-Ray, и удалили дубли, вызванные повторяющимися названиями или альтернативными версиями. Для каждого оставшегося фильма они перехватывали потоки данных, которые использует плеер для загрузки информации X-Ray и субтитров, сохраняя результаты в структурированных файлах, где перечислены границы сцен, персонажи, присутствующие в каждой сцене, и, для большинства названий, точная привязка ко времени каждого сегмента субтитров.
Связывание сцен с более широкой картиной кино
Реальная ценность набора данных заключается в соединении этих разбиений по сценам с внешней информацией. Хотя X-Ray уже связывает каждого персонажа с профилем IMDb, он не содержит IMDb ID самого фильма. Авторы разработали алгоритм сопоставления, который начинается с названия фильма, получает несколько кандидатных совпадений из IMDb и затем сравнивает ведущий актерский состав из IMDb с актерами, указанными в данных X-Ray. Если по крайней мере один ключевой актер совпадает, фильм считается совпавшим. Этот автоматический процесс правильно сопоставил подавляющее большинство фильмов, а затем команда вручную проверила оставшиеся несколько сотен спорных случаев, исправив неверные классификации и удалив записи, которые на самом деле не являлись игровыми фильмами, например сольные стендап‑спешлы. В результате получился тщательно очищенный набор фильмов, где каждая сцена, персонаж и субтитр можно связать с богатыми метаданными, такими как год, страна и демография состава.
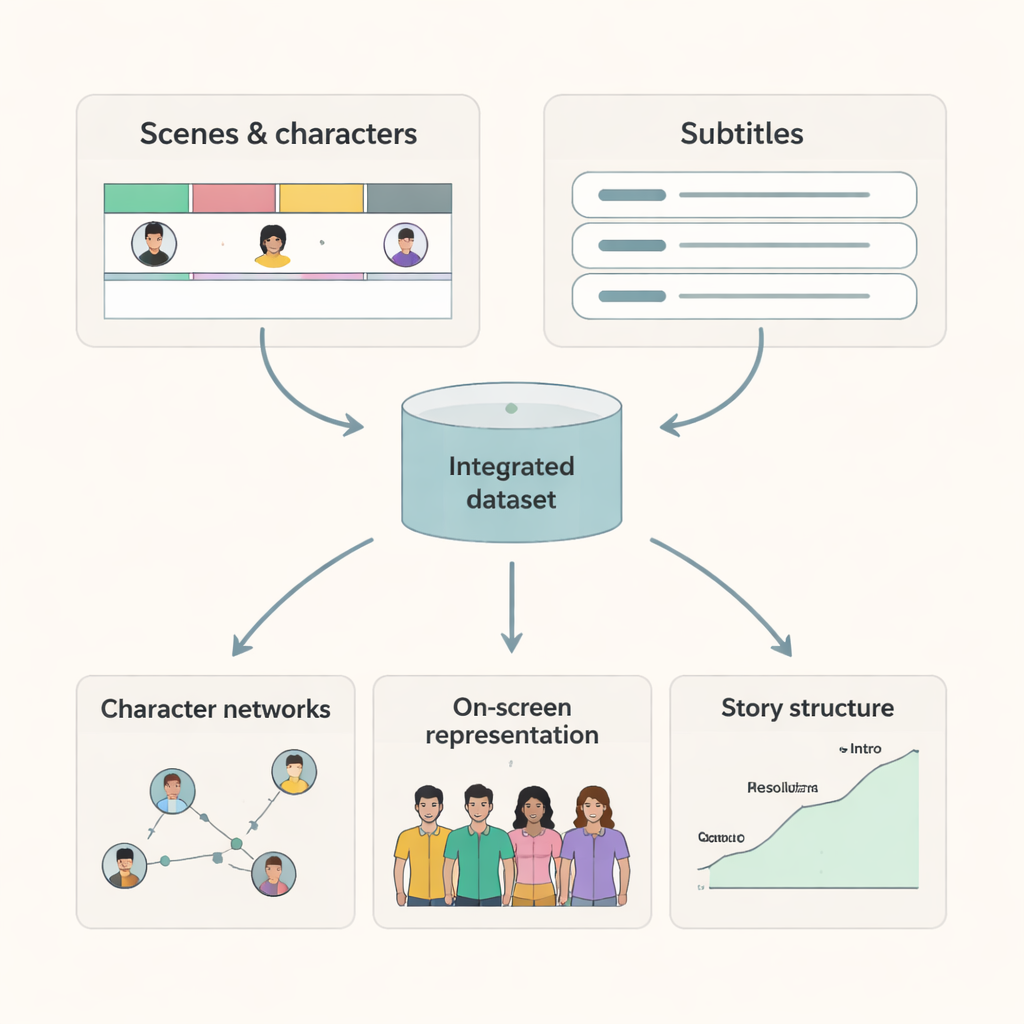
Что исследователи могут сделать с этими фильмами
Поскольку у каждой сцены есть четкие время начала и конца и список присутствующих, исследователи теперь могут строить точные карты взаимодействий персонажей и экранного времени. Субтитры, выровненные по сценам, дают возможность изучать, как язык различается между персонажами и контекстами, или как определенные темы разворачиваются через диалог. Комбинируя этот набор данных с дополнительной информацией из IMDb и других источников, ученые могут исследовать такие вопросы, как: как меняется гендерный баланс на экране с течением десятилетий? Получают ли персонажи из разных слоев общества равное внимание в сюжете? Чем отличаются модели взаимодействий в разных жанрах или странах? Набор данных также служит высококачественным ориентиром для моделей искусственного интеллекта, стремящихся понимать видеоконтент, поскольку он предоставляет эталонные данные о том, кто видим и когда.
Новая оптика на повседневные фильмы
Проще говоря, эта работа превращает тысячи фильмов в индексируемый каталог по сценам о том, кто появляется, кто говорит и как устроены сюжеты. Хотя коллекция ограничена фильмами, доступными на Prime Video в США, и зависит от внутренних процессов X-Ray у Amazon, она всё равно охватывает фильмы разных десятилетий и жанров, а не только известные лауреаты премий. Такое покрытие позволяет исследовать повседневные фильмы, а не только классические ленты, сохранившиеся в памяти. По мере обновления и расширения набора данных он обещает углубить наше понимание того, как фильмы отражают общество, и дать как социальным ученым, так и технологам более достоверное представление о том, что на самом деле происходит на экране.
Цитирование: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Ключевые слова: наборы данных о фильмах, анализ на уровне сцен, Amazon X-Ray, метаданные IMDb, показы на экране