Clear Sky Science · ru
CNeuroMod-THINGS — плотнo выборочная fMRI‑база данных для исследований визуальной нейронауки
Почему просмотр картинок может раскрыть, как работает наш ум
Каждый день наши глаза воспринимают тысячи изображений — от кружек и смартфонов до собак, деревьев и людных улиц. За кулисами мозг быстро распознаёт то, что мы видим, и часто запоминает это. Проект CNeuroMod-THINGS поставил задачу зафиксировать эту скрытую активность с исключительной детализацией, создав одну из глубочайше измеренных баз данных активности мозга, собранных во время просмотра реальных фотографий. Этот ресурс предназначен для ускорения следующего поколения исследований мозга и искусственного интеллекта.
Создание богатой библиотеки мозговых откликов
Вместо того чтобы отсканировать сотни добровольцев один или два раза, команда многократно сканировала всего четырёх крайне мотивированных участников. Каждый человек приходил 33–36 раз, что в рамках более широкого проекта CNeuroMod суммарно дало примерно 200 часов сканирования мозга и десятки часов, посвящённых только картинкам. В ходе этих сессий участники просмотрели до 4 320 различных фотографий из коллекции THINGS, охватывающей 720 категорий повседневных объектов — такие как инструменты, животные, транспорт и мебель. Такой тщательный подбор изображений обеспечивает представительство многих уголков нашего визуального мира, а не лишь нескольких популярных объектов.

Игра на память внутри МРТ-сканера
Чтобы удерживать внимание участников и проверять память, исследователи превратили просмотр картинок в непрерывную игру на распознавание. В каждом испытании одно изображение появлялось в центре экрана, пока человек лежал в МРТ-сканере. С помощью кастомного контроллера в стиле видеоигры участники сообщали, считали ли они картинку новой или уже виденной ранее, и насколько уверены в своём решении. Большинство изображений показывали три раза: при первом показе, затем снова через несколько минут в той же сессии и ещё раз при более позднем визите, часто примерно через неделю. Такая схема позволяла команде сравнивать краткосрочную и долгосрочную память для одних и тех же картинок, отслеживая при этом соответствующие изменения в мозговой активности.
Фиксация детализированных сигналов зрения и памяти
Набор данных выходит далеко за пределы простых «включено/выключено» показателей активности мозга. Авторы использовали продвинутые методы анализа, чтобы оценить отдельный отклик для каждого испытания и каждого изображения в каждой крошечной трёхмерной «пиксельной» единице сканирования (вокселе). Они также отслеживали направление взгляда с помощью камер для трекинга глаз, мониторили дыхание и пульс и измеряли движение головы. Контроль качества показывает, что сигналы удивительно стабильны: участники отвечали почти в каждом испытании, держали взгляд близко к центру экрана и двигались очень мало. В ключевых зрительных областях — регионах, известным сильными реакциями на лица, тела или сцены — одно и то же изображение вызывало высоко согласованные паттерны активности при каждом показе. Эти паттерны были настолько выражены, что при упрощённом отображении откликов в двумерной карте изображения со сходным смыслом (например, животные или транспорт) склонялись группироваться вместе.
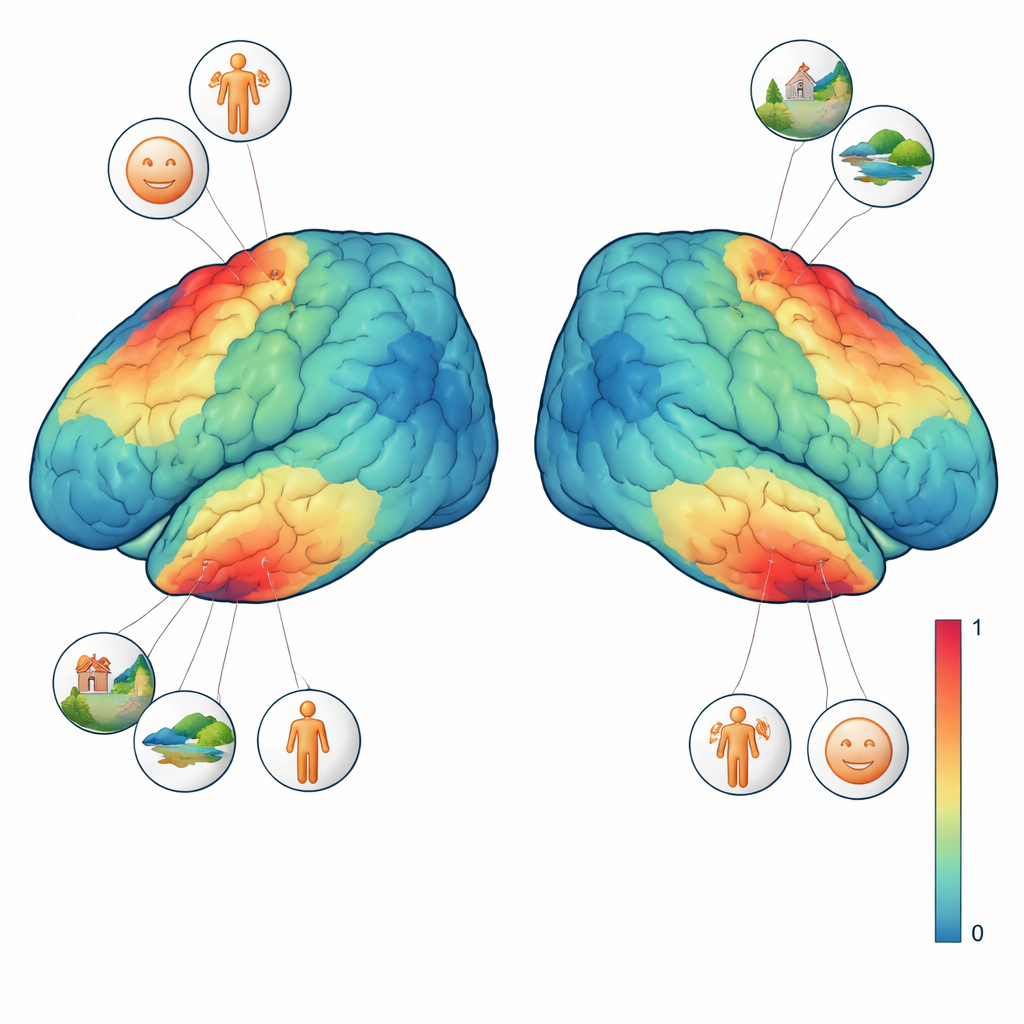
Картирование того, что важно для разных областей мозга
Чтобы лучше интерпретировать эти сигналы, трое из четырёх участников прошли дополнительные тесты зрения. В одном из них через текстурированный фон прокатывались расширяющиеся формы, чтобы показать, какую часть визуального поля «видит» каждая область мозга. В другом показаны короткие блоки лиц, мест, частей тела, персонажей и общих объектов, чтобы локализовать области, предпочитающие тот или иной тип изображений. Совмещая эти локализующие задачи с основным экспериментом, команда могла задавать точные вопросы, например: отвечает ли один воксел сильнее, когда присутствует лицо, или когда видна вся сцена? Они обнаружили, что области, селективные к лицам, реагировали сильнее всякий раз при появлении любого лица, в то время как область, селективная к сценам, предпочитала изображения с богатым фоном — комнаты, улицы или пейзажи — даже если людей на них не было видно. Эти тонкие предпочтения проявлялись на уровне отдельных изображений и даже отдельных вокселов.
Основа для более интеллектуальных моделей зрения
В своей основе CNeuroMod-THINGS — это тщательно курируемый публичный ресурс, а не разовый результат. Все данные мозга, трекинг глаз, поведенческие ответы, аннотации изображений и код анализа свободно доступны по открытой лицензии. Поскольку одни и те же четыре человека сканировались во множестве других задач — при просмотре фильмов, в видеоиграх, при прослушивании историй — исследователи теперь могут строить детализированные, персонализированные модели, связывающие контролируемые эксперименты с более естественными впечатлениями. Для неспециалистов главный вывод в том, что у нас теперь есть таблица высокого разрешения, показывающая, как реальный человеческий мозг реагирует на тысячи повседневных изображений. Это поможет учёным проверять идеи о зрительном восприятии и памяти и направит разработку систем искусственного зрения, которые видят мир чуть ближе к тому, как видим его мы.
Цитирование: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Ключевые слова: fMRI, зрительное восприятие, распознавание объектов, данные мозга, память