Clear Sky Science · ru
Набор данных Kymata Soto о языке: электромагнитоэнцефалографический набор данных для обработки естественной речи
Слушая, как мозг воспринимает настоящие разговоры
Большая часть того, что мы говорим и слышим в повседневной жизни, — это непринуждённые разговоры, а не отдельные слова или тщательно прочитанные предложения. Тем не менее большая часть исследований мозга в области языка опиралась на искусственные задания. Набор данных Kymata Soto меняет это, предоставляя насыщенную открытую коллекцию записей активности мозга людей, которые просто слушают живые радиодискуссии на английском и русском языках, давая учёным мощное новое окно в то, как мозг обрабатывает естественную речь.
Новая библиотека реакций мозга на настоящую речь
Проект объединяет два передовых метода регистрации активности мозга — электроэнцефалографию (ЭЭГ) и магнитоэнцефалографию (МЭГ) — у 35 взрослых: 20 носителей английского языка и 15 носителей русского. Пока участники сидели спокойно и слушали примерно шесть с половиной минут радиоформата на своём языке, их мозговая активность записывалась с частотой тысяча снимков в секунду. Каждый человек слышал одно и то же аудио несколько раз, что позволило исследователям усреднить повторения и выделить устойчивые ответы мозга на фоне шума. В результате получена детальная, синхронизированная по времени запись того, как мозг реагирует, момент за моментом, по мере развития разговора.

Разговоры об истории мороженого и кофе
Вместо классических рассказов или искусственно сконструированных предложений команда выбрала увлекательные, но повседневные темы: историю мороженого для англоговорящих слушателей и историю колумбийского кофе для русскоговорящих. Обе записи были получены из студийных обсуждений BBC с тремя участниками (двое мужчин и одна женщина). Разговоры были отредактированы до примерно 400 секунд и воспроизводились через наушники на комфортной громкости. После каждого повторения участники отвечали на один или два простых вопроса с множественным выбором по содержанию — ровно столько, чтобы удостовериться, что они остаются внимательными и следят за сюжетом, но не для жёсткой проверки знаний.
Занятые глаза, сосредоточенный слух
Пока участники слушали, они смотрели на центральный крест на экране. Вокруг него дрейфовали облака цветных точек, которые изменялись, похоже, в случайном порядке. Эти движущиеся точки служили двум целям: они помогали людям сохранять фиксированное направление взгляда, что улучшает качество данных, и создавали управляемые паттерны визуального движения и цвета, которые другие исследователи могут впоследствии проанализировать. Важно, что точки не были синхронизированы с содержанием речи, то есть они не «иллюстрировали» историю и не добавляли смысла, но обеспечивали постоянный визуальный фон, который можно изучать параллельно со звуками.
От сырых мозговых сигналов до готовых к использованию данных
Исследователи тщательно задокументировали каждую часть эксперимента и организовали набор данных в соответствии с международным стандартом для данных мозга под названием BIDS. Для каждого участника доступны сырые ЭЭГ- и МЭГ-записи, временные маркеры начала аудио, посекундные визуальные события и тренировочные сегменты. Команда также предоставляет оригинальные аудиофайлы, полные транскрипты и точное время начала каждого слова и даже каждого отдельного звукового элемента речи. Включены скрипты, позволяющие другим автоматизированно воспроизвести точные отрывки аудио, которые использовались. Для англоязычной группы анонимизированные МРТ-сканы мозга доступны, чтобы можно было сопоставлять реакции мозга с индивидуальной анатомией; для русскоязычной группы согласие не позволило распространять МРТ-изображения, поэтому пользователям рекомендуется опираться на стандартные средние шаблоны мозга.
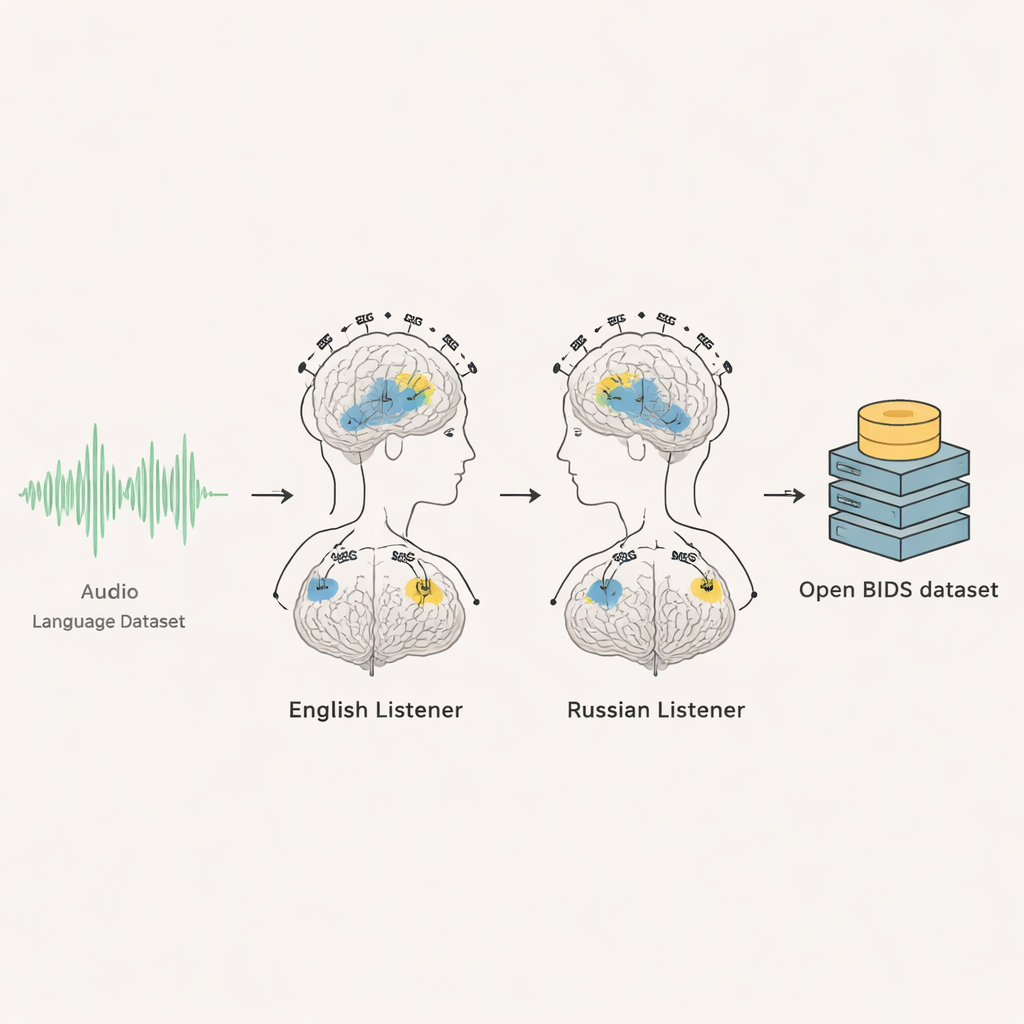
Проверка достоверности сигналов
Чтобы убедиться в научной надёжности данных, авторы провели валидационные анализы, сосредоточенные на том, как мозг отслеживает изменения громкости звука во времени. Они преобразовали аудио в несколько математических описаний «временной изменяющейся громкости», а затем исследовали, где и когда реакции мозга соотносились с этими паттернами громкости. Для слушателей как на английском, так и на русском языках мозг показал схожие временные паттерны, что согласуется с ранее опубликованными результатами. Это совпадение между языками и с предыдущими исследованиями является сильным признаком того, что записи чистые, надёжные и готовы к дальнейшему использованию.
Почему это важно для будущих исследований мозга и языка
Для неспециалистов главное — этот набор данных представляет собой новый общий ресурс, позволяющий множеству различных исследовательских групп изучать, как реальная, спонтанная речь обрабатывается в мозге. Поскольку он открыт, хорошо аннотирован и записан на двух разных языках, он может поддержать проекты от базовых вопросов о том, как мы понимаем разговор, до сравнений между языками и амбициозных попыток декодировать речь непосредственно из мозговой активности. Проще говоря, набор данных Kymata Soto о языке больше не столько про ответ на один конкретный вопрос, сколько про предоставление научному сообществу высококачественной общей основы для изучения того, как наши мозги понимают разговoры, которые наполняют нашу повседневную жизнь.
Цитирование: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Ключевые слова: мозг и язык, восприятие речи, ЭЭГ МЭГ, натуралистическая беседа, открытые нейровизуализационные данные