Clear Sky Science · ru
Семантическое согласование модели метаданных Архива генома и фенома человека Германии в европейской геномике
Почему для обмена данными генома нужно больше, чем просто файлы
Современная медицина всё чаще опирается на чтение нашей ДНК для постановки диагнозов и подбора терапии. Но настоящая сила геномики раскрывается, когда данные из многих больниц и стран можно объединить. Это возможно лишь в том случае, если каждый набор данных описан ясно и совместимо, а также если строго соблюдаются законы о конфиденциальности, такие как европейский GDPR. В этой статье объясняется, как Немецкий архив генома и фенома человека (GHGA) создаёт подробную «систему описания» геномных исследований, чтобы ценные данные можно было находить, понимать и безопасно обменивать по всей Европе.
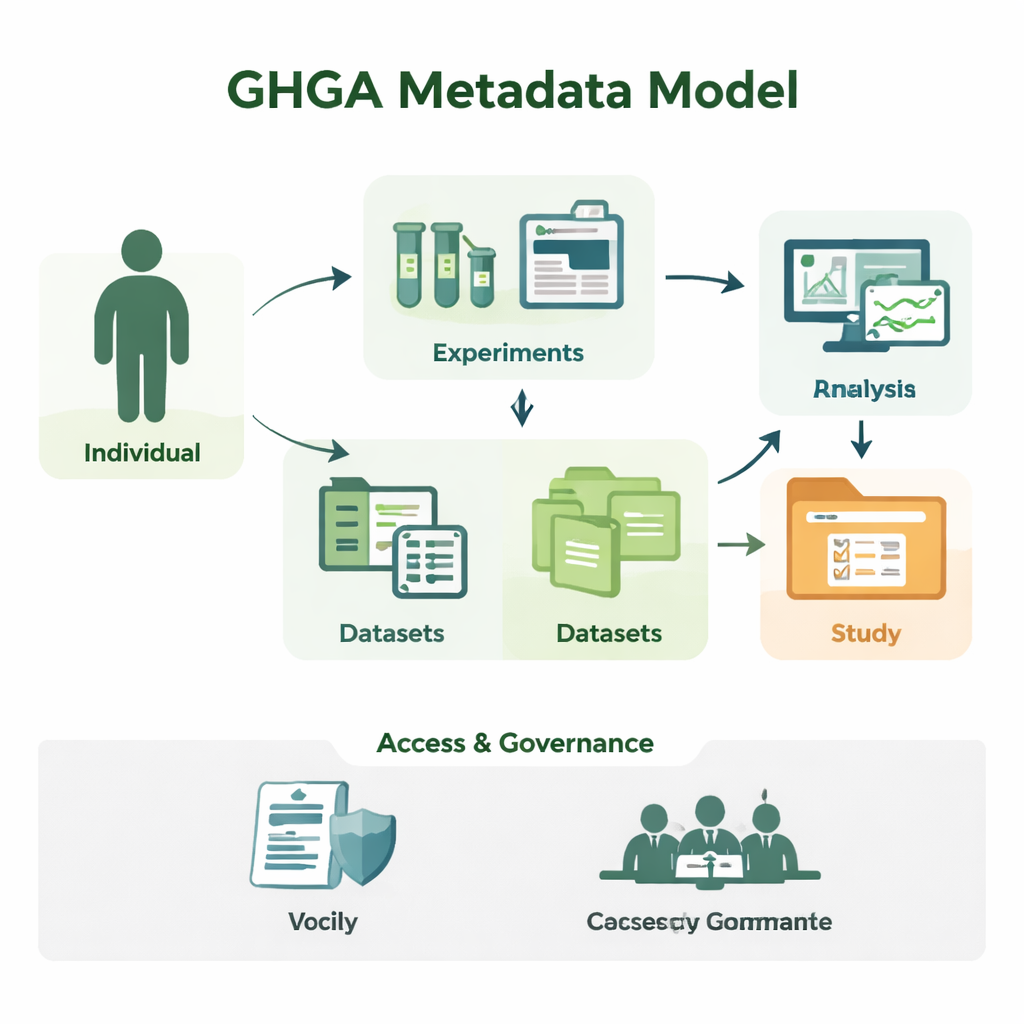
От сырых последовательностей к понятным исследованиям
Геномные исследования производят огромные объёмы последовательностей, но сами по себе файлы с буквами ДНК мало что значат. Учёным нужно знать, от кого взят образец, какая ткань использовалась, как проводился эксперимент и при каких условиях данные можно повторно использовать. GHGA фиксирует эту сопутствующую информацию как метаданные. Его модель организует метаданные в 16 блоков, таких как человек, участвующий в исследовании ("Индивид"), взятый образец, проведённый эксперимент и анализ, созданные файлы данных, а также наборы данных и исследования, которые их объединяют. Отделяя научные сведения от административных, например условий доступа, модель отражает работу реальной лаборатории и портала данных, но в форме, которую компьютеры могут надёжно обрабатывать.
Сохраняя полезность данных, обеспечивая анонимность людей
Поскольку GHGA работает с чувствительными данными о здоровье людей, команда должна была спроектировать модель так, чтобы она была научно насыщенной, но не упрощала идентификацию какого-либо человека. Европейские правила GDPR определяют как персональные данные любую информацию, которую можно разумно связать с конкретным человеком, даже при удалённых именах. В статье описан тщательный анализ приватности, показавший, как комбинация деталей — например, возраст, почтовый индекс и редкие диагнозы — может раскрыть личности. В ответ публичный портал GHGA избегает детализированных географических данных, группирует возраст в широкие диапазоны вместо точных лет и объединяет подробные коды диагнозов в более крупные категории. Так исследователи по‑прежнему видят, релевантен ли им набор данных, а усилия, необходимые для выделения конкретного человека, становятся нереалистичными.
Проверка совместимости с европейской экосистемой геномики
Чтобы быть по‑настоящему полезной, модель метаданных GHGA должна вписываться в более широкую европейскую сеть геномных архивов и инструментов. Авторы поэтому сопоставили свою модель, поле за полем, с четырьмя другими широко используемыми фреймворками: двумя версиями European Genome-phenome Archive (EGA), стандартом ISA-tab и моделью FAIR Genomes из Нидерландов. Они провели детальный «кроссвок», задаваясь для каждого поля GHGA вопросом, есть ли эквивалент в других моделях и наоборот. Они обнаружили, что большинство ключевых свойств GHGA имеют ясные аналоги в других системах, особенно для описания исследований, образцов, экспериментов, анализов и форматов файлов. Это означает, что наборы данных GHGA можно понять и интегрировать вместе с данными, хранящимися в других европейских системах.
Нахождение общего — и то, чего ещё не хватает
Из этого сравнения команда выделила 25 «консенсусных» полей метаданных, которые присутствуют как минимум в трёх из пяти моделей. Они охватывают базовые сведения, такие как пол и состояние здоровья участников, использованная ткань, тип секвенирования и прибор, метод анализа, форматы файлов, а также краткие описания исследований и контактные данные. Эти общие поля соответствуют существующим минимальным требованиям к отчётности и могут служить основным чек‑листом для тех, кто разрабатывает новые порталы геномных данных. В то же время анализ выявил информацию, которую некоторые модели собирают, но которую GHGA в настоящее время опускает или принимает только в виде гибкого свободного текста — например точные даты взятия образцов и секвенирования, исключённые диагнозы и подробные имена контактов. Многие из этих пропусков — сознанные компромиссы в пользу приватности и анонимности.
Что это значит для будущих исследований в здравоохранении
В целом исследование показывает, что модель метаданных GHGA подробна, гибка и тесно согласована с международной практикой, при этом оставаясь в рамках строгих европейских правил конфиденциальности. Она уже покрывает все поля, которые другие архивы рассматривают как обязательные, и может быть расширена под новые технологии, такие как одноклеточная и пространственная омics. Предлагая ясный способ описать, кто и что включено в геномное исследование, как были получены данные и при каких условиях их можно использовать повторно, GHGA помогает превратить разрозненные хранилища данных в единый исследовательский ресурс. Для пациентов это повышает вероятность того, что их данные, однажды переданные, смогут безопасно способствовать открытиям и лучшим методам лечения через границы в течение многих лет.
Цитирование: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Ключевые слова: обмен геномными данными, стандарты метаданных, конфиденциальность и GDPR, GHGA, персонализированная медицина