Clear Sky Science · ru
Надёжность больших языковых моделей в роли медицинских помощников для широкой публики: рандомизированное пререгистрированное исследование
Почему ваш телефон может не быть лучшим «первым врачом»
Все больше людей обращаются к ИИ-чатботам за помощью, когда они плохо себя чувствуют, надеясь быстро получить ответ на вопросы: стоит ли тревожиться, что могут означать симптомы и нужно ли ехать в больницу. В этом исследовании ставится простой, но срочный вопрос: если обычные пользователи используют мощные языковые модели в качестве медицинских помощников дома, принимают ли они благодаря этому действительно лучшие решения о своём здоровье — или технология создаёт ложное чувство безопасности?
Проверка умных машин на реалистичных случаях
Чтобы выяснить это, исследователи в Великобритании составили десять правдоподобных медицинских сценариев, например внезапная сильная головная боль или затруднённое дыхание, основанных на распространённых состояниях, с которыми многие из нас могут столкнуться. Команда опытных врачей согласовала лучший «следующий шаг» для каждого случая — от оставаться дома и следить за собой до вызова скорой помощи — и перечислила ключевые состояния, которые внимательный человек должен рассмотреть. Затем 1 298 взрослых по всей Великобритании случайным образом распределили по одной из четырёх групп: использование одного из трёх ведущих ИИ-чатботов или использование того, на что они обычно опираются дома, например поиск в интернете или личный опыт.
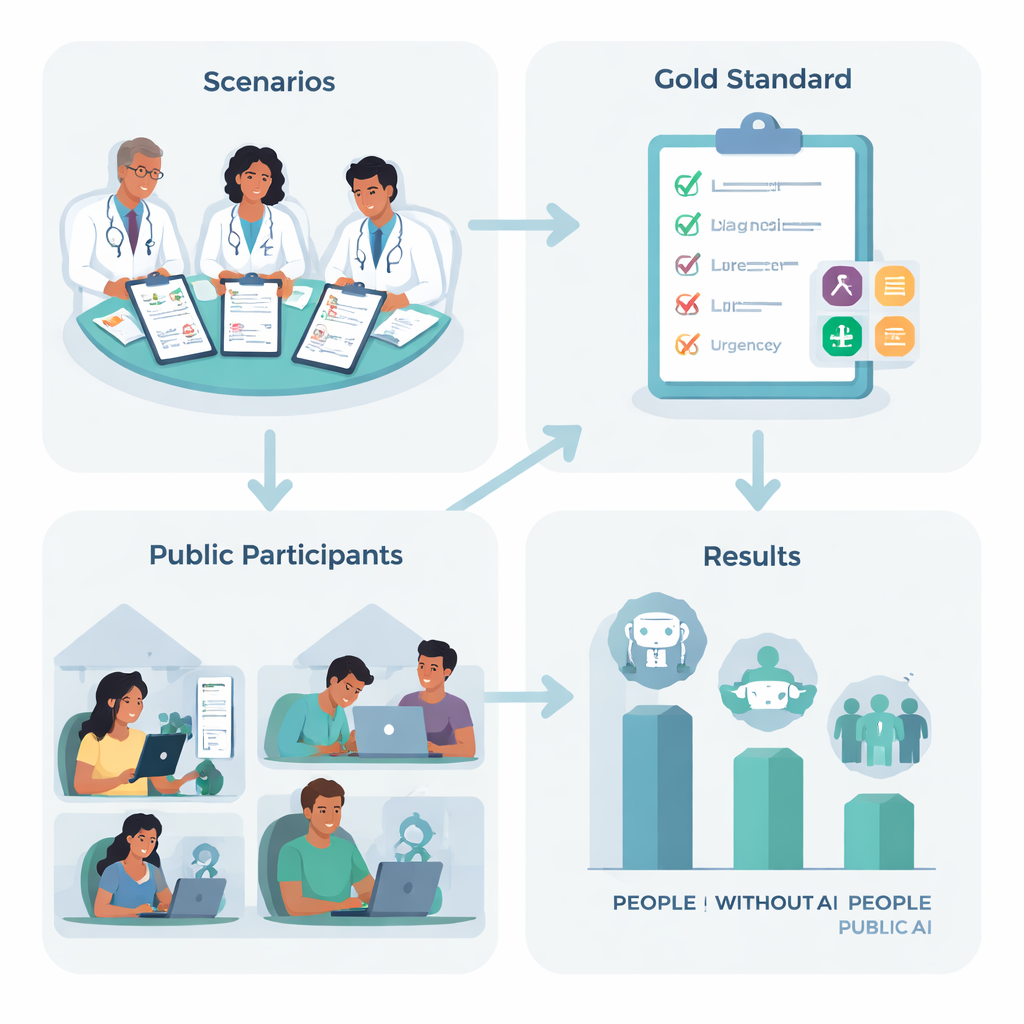
Как показали себя люди и машины — отдельно и вместе
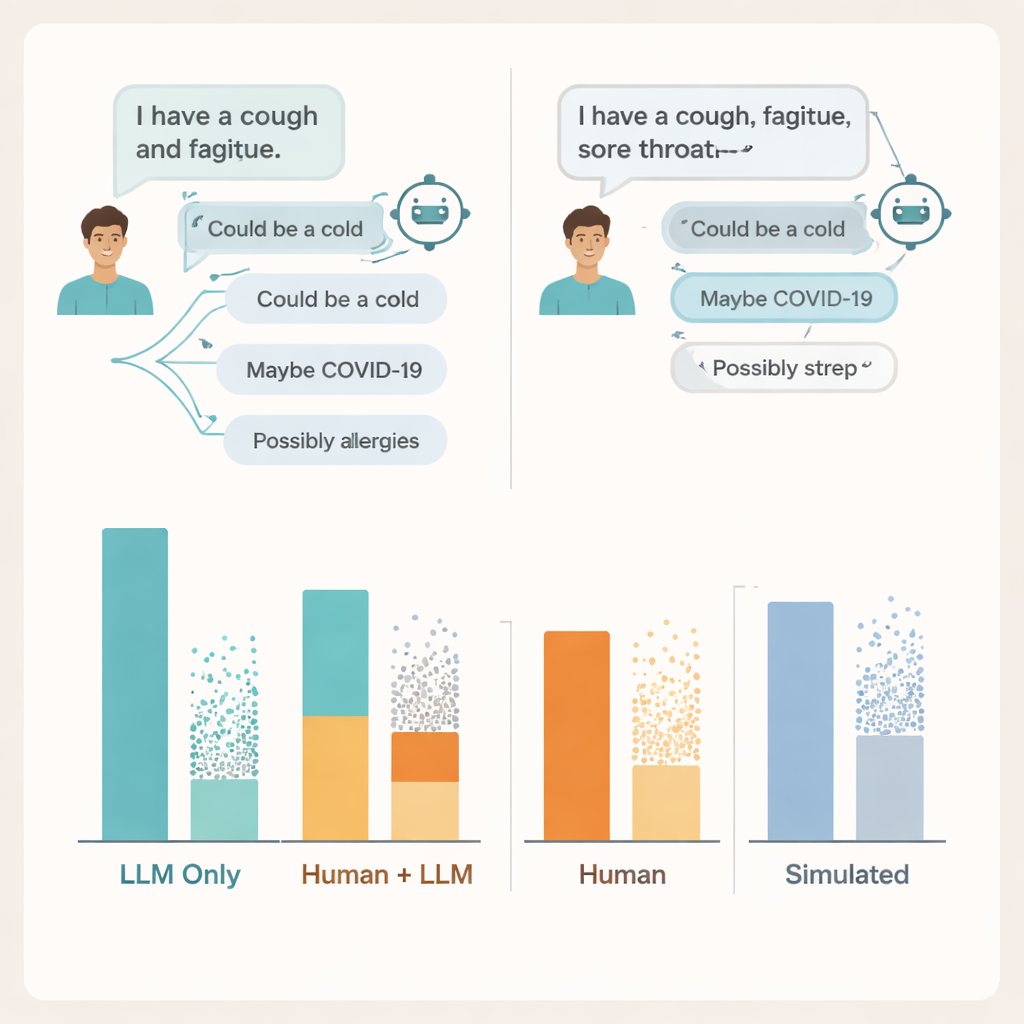
Когда языковые модели тестировали отдельно, подавая им полные описания случаев и прямо спрашивая диагноз и рекомендуемое действие, они выступили впечатляюще. По трём системам они правильно указывали хотя бы одно релевантное медицинское состояние примерно в 95% случаев и выбирали верный уровень срочности более чем в половине случаев — значительно лучше случайного выбора. На бумаге эти системы выглядели как сильные кандидаты, способные направлять обеспокоенных пациентов.
Когда советы ИИ встречаются с реальными людьми
Но как только в игру вступили обычные пользователи, картина изменилась. Участники, пользовавшиеся ИИ, не показали большей точности по сравнению с контролем в выборе следующего шага, а по названию релевантных основных состояний они выступили даже хуже. Люди в не-ИИ группе были примерно в 1,8 раза чаще способны назвать правильное состояние, чем те, кто использовал чатботы. Большинство участников во всех группах недооценивали серьёзность ситуации. Другими словами, доступ к продвинутой языковой модели не помог людям лучше понять свои симптомы и не подтолкнул их явно к более безопасным решениям.
Где разговор даёт сбои
Чтобы понять причины, исследователи проанализировали реальные расшифровки чатов. Они обнаружили проблемы с обеих сторон диалога. Многие пользователи не указывали достаточно деталей о своих симптомах, чтобы ИИ мог дать обоснованный совет — как иногда пациенты опускают важную информацию при разговоре с врачом. Сами модели часто упоминали хотя бы одно релевантное состояние, но также добавляли несколько неверных или отвлекающих вариантов, и пользователи не могли отличить, какие предложения имеют значение. В некоторых случаях почти идентичные описания симптомов приводили к резко разным рекомендациям от одной и той же модели, что затрудняло людям формирование ясного ощущения, когда можно доверять увиденному на экране.
Почему стандартные тесты пропускают реальные риски
Команда также сравнила эти результаты с двумя популярными способами оценки медицинских ИИ: вопросами в формате экзамена с множественным выбором и полностью смоделированными «пациентскими» чатами, проводимыми между двумя моделями. В обоих случаях системы снова выглядели сильными, достигали или превосходили типичные проходные баллы по экзаменоподобным вопросам и показывали лучшие результаты в чатах с моделями, чем с реальными людьми. Тем не менее высокие баллы на экзаменах и отточенные смоделированные диалоги не соответствовали тому, насколько успешно реальные люди пользовались теми же инструментами. По мнению авторов, бенчмарки, проверяющие знание в изоляции, упускают из виду беспорядочный, хрупкий характер реального взаимодействия человека и ИИ.
Что это значит для пациентов и систем здравоохранения
На данный момент, заключают авторы, существующие универсальные языковые модели не готовы выступать в роли беспомощных первичных советчиков для широкой публики. В них, безусловно, содержится много медицинских знаний, но эти знания не автоматически превращаются в более безопасные решения, когда встревоженные люди вводят фрагментарные, запутанные вопросы дома. Чтобы ИИ действительно стал полезен в ситуациях с высокими ставками, таких как здравоохранение, потребуется не только улучшение экзаменационных показателей — понадобятся тщательный дизайн, тестирование с разнообразными реальными пользователями и более строгие проверки того, как собирается, объясняется и воспринимается информация в ходе диалога.
Цитирование: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Ключевые слова: медицинские чатботы, самодиагностика, искусственный интеллект в здравоохранении, принятие решений пациентами, большие языковые модели