Clear Sky Science · ru
Синтез научной литературы с помощью языковых моделей с расширенным поиском
Почему так трудно успевать за наукой
Каждый год в сети появляется миллионы новых научных статей. Ни один человек-исследователь не способен прочесть их все, тем не менее важные медицинские методы, климатические выводы и технологические прорывы могут быть скрыты в этом потоке информации. В этой статье рассматривается, смогут ли продвинутые системы ИИ помочь учёным просеивать океан исследований и сводить их в ясные, надёжные обзоры — без выдумок.
Новый тип помощника для исследований
Авторы представляют OpenScholar — систему искусственного интеллекта, созданную специально для чтения и синтеза научной литературы. В отличие от общих чат-ботов, OpenScholar тесно связан с гигантской открытой базой данных примерно из 45 миллионов научных работ, называемой OpenScholar DataStore. Когда учёный задаёт вопрос — например, как охлаждать левитированные наночастицы или какие методы лучше для визуализации мозга — система сначала ищет по этой базе соответствующие фрагменты, а затем составляет ответ с внутритекстовыми ссылками, подобно обзорной статье, написанной человеком. Этот процесс повторяется несколько раз: система критикует и улучшает свои черновики, повышая ясность, полноту и качество цитирования.
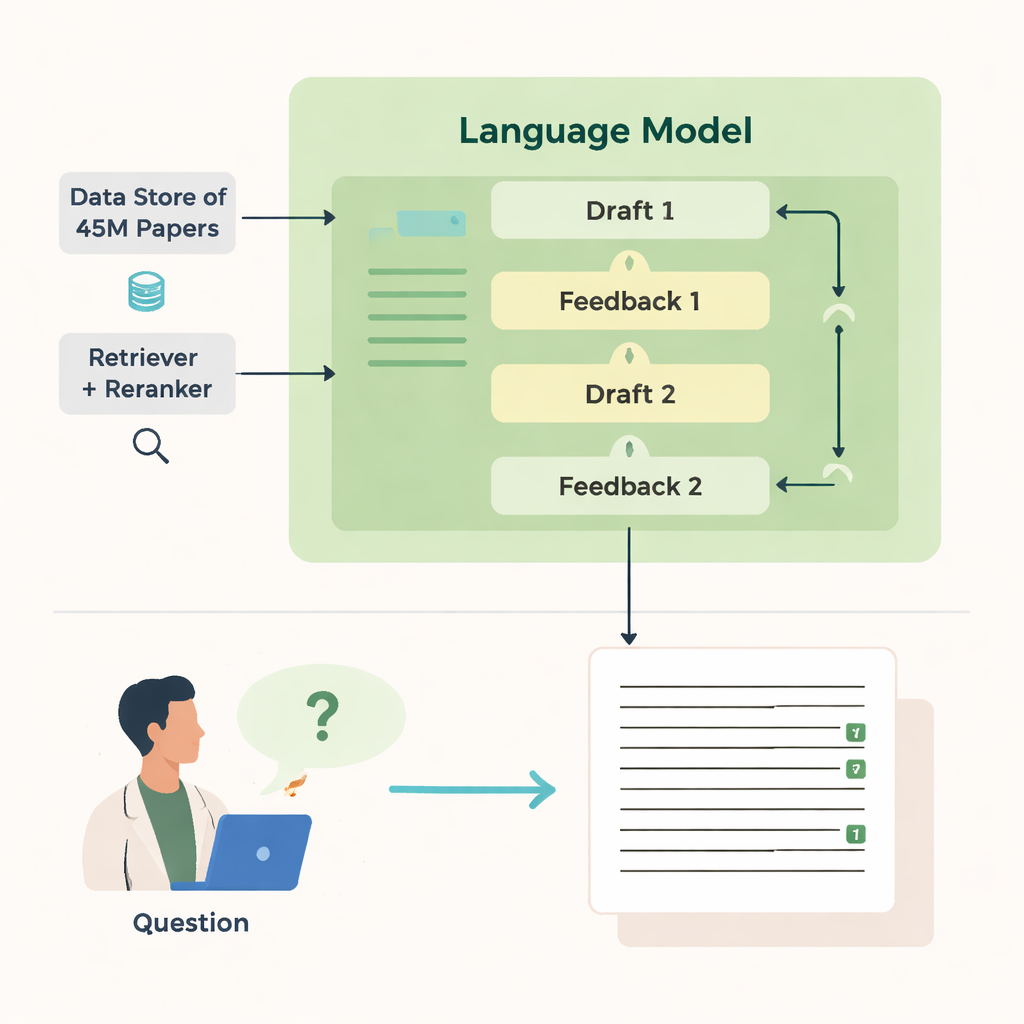
Как она ищет и пишет
Сила OpenScholar заключается в нескольких согласованных компонентах. Модуль «retriever» просматривает заранее вычисленные встраивания текстов (text embeddings) миллионов статей, чтобы найти перспективные фрагменты, тогда как «reranker» перенастраивает их порядок, фокусируясь на наиболее релевантных. Языковая модель затем использует эти доказательства для создания развёрнутого ответа с пронумерованными ссылками. После первого черновика модель генерирует отзывы самому себе — указывая на упущенные перспективы, слабую структуру или недостаток доказательств — и при необходимости запускает более целевые поиски. Затем она переписывает ответ, включая новые статьи и корректируя цитаты. Финальная проверка гарантирует, что утверждения, требующие подтверждения, подкреплены по крайней мере одним найденным источником.
Проверка утверждений и цитирований
Чтобы оценить, действительно ли OpenScholar полезен, авторы создали ScholarQABench — крупный бенчмарк, предназначенный имитировать реальные вопросы для обзора литературы. Он включает почти 3000 вопросов, составленных экспертами, и сотни развернутых ответов по информатике, физике, нейронауке и биомедицине. Важно, что эти вопросы обычно требуют чтения нескольких статей, а не только одного реферата. Команда оценила системы по множеству осей: фактическая корректность, полнота освещения ключевых пунктов, ясность изложения и насколько точно цитаты отражают исходные работы. Они сочетали автоматические проверки с детальными оценками экспертов уровня PhD, которые сравнивали ответы, сгенерированные ИИ, с ответами, написанными людьми.
Опередив сильные чат-боты и сравнявшись с экспертами
По этому бенчмарку OpenScholar превзошёл как стандартные языковые модели, так и более ранние инструменты, которые просто добавляли поиск к общему чат-боту. Компактная версия на восемь миллиардов параметров, обученная полностью на открытых данных, показала лучшие результаты в требовательной задаче синтеза на основе нескольких статей, чем GPT-4o и конкурирующая система PaperQA2, несмотря на то, что те опирались на более крупные проприетарные модели. Поразительная находка заключалась в частоте галлюцинаций ссылок у обычных чат-ботов: в 78–90% случаев их списки цитат включали статьи, которых не существовало или которые не подтверждали утверждения. В отличие от этого, точность цитирования OpenScholar сопоставима с точностью экспертов-человеков. При прямом сравнении эксперты предпочитали OpenScholar-8B экспертно написанным ответам примерно в половине случаев, а конвейер OpenScholar на основе GPT-4o — примерно в 70% случаев, в основном потому, что ИИ охватывал больше релевантных работ и организовывал их ясно.
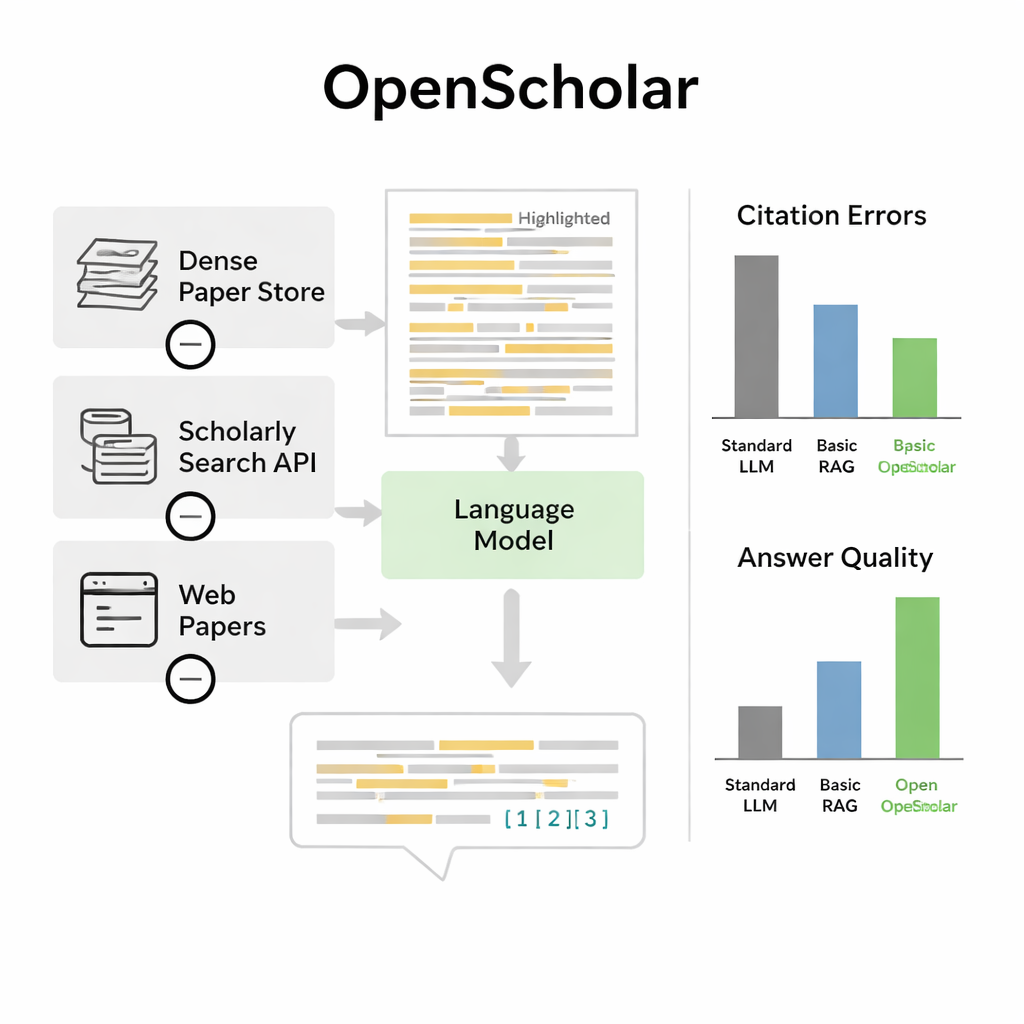
Ограничения и будущие улучшения
Несмотря на эти достижения, авторы подчёркивают, что OpenScholar не заменяет учёных. Система по-прежнему может пропускать наиболее репрезентативные статьи, переоценивать менее важные работы или допускать фактические ошибки, особенно в более компактных моделях. Сам бенчмарк тоже имеет ограничения: он в основном сосредоточен на информатике, биомедицине и физике, а тщательно аннотированных вопросов всё ещё относительно немного, поскольку время экспертов дорого. Оценки также с трудом полностью отражают более тонкие качества, такие как то, выделяют ли цитаты действительно ключевые работы или помог бы ответ на практике в проведении нового эксперимента.
Что это означает для повседневной науки
Для неспециалистов главный вывод заключается в том, что тщательно продуманные инструменты ИИ уже сейчас могут помочь учёным эффективнее ориентироваться в научной литературе при условии, что они связаны с реальными данными и подчинены строгим стандартам доказательности и прозрачности. OpenScholar показывает, что когда система ИИ создаётся с нуля для извлечения, проверки и цитирования реальных статей — и когда её производительность тестируется по сравнению с экспертами-людьми — она может выдавать обзоры литературы, которые не только читаемы, но и проверяемы. На практике такие инструменты могли бы освободить исследователей для большей сосредоточенности на проектировании экспериментов и интерпретации результатов, при этом люди остаются конечными судьями того, что является истинным и важным.
Цитирование: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Ключевые слова: обзор научной литературы, языковые модели с расширенным поиском, OpenScholar, точность цитирования, инструменты ИИ для исследований