Clear Sky Science · ru
Прогнозирование и обнаружение млекопитающих метаболитов с помощью языковых моделей
Скрытая химия внутри наших тел
Каждая капля крови или мочи содержит тысячи мельчайших молекул, которые отражают то, что мы едим, как мы живём и заболеваем ли мы. Тем не менее для большинства этих молекул учёные не знают ни их имён, ни их функций. В этой статье представлена система искусственного интеллекта DeepMet, которая «читает» язык этих молекул и предсказывает, какие из них отсутствуют на текущих картах человеческой и животной химии. Направляя эксперименты к наиболее многообещающим кандидатам, DeepMet помогает исследователям раскрывать эту химическую тёмную материю и лучше понимать, как работают наши организмы.
Почему так много молекул остаются неизвестными
Современные приборы способны одновременно взвешивать и частично характеризовать тысячи молекул в образце ткани. Но преобразовать эти отпечатки в точные структуры — задача сложная. Существующие базы данных перечисляют множество известных метаболитов, однако большинство сигналов, наблюдаемых в реальных образцах, не совпадает ни с чем из этих каталогов. Этот разрыв указывает на то, что текущие карты метаболизма неполны и что многие природные молекулы у млекопитающих никогда не были описаны. Авторы поставили задачу создать инструмент, который мог бы учиться на известных метаболитах, а затем прогнозировать наиболее правдоподобные отсутствующие — подобно тому, как языковые модели предсказывают вероятные слова в предложении.
Обучение машины грамматике метаболизма
Команда обучила нейронную сеть DeepMet примерно на 2000 хорошо задокументированных человеческих метаболитов, кодируя каждый из них короткой строкой, описывающей структуру. После начального обучения на молекулах, похожих на лекарства, чтобы усвоить общие химические правила, DeepMet была дополнительно дообучена на наборе метаболитов. При генерации новых структур модель выдавала молекулы, занимающие те же области химического пространства, что и реальные метаболиты, и даже воспроизводила многие известные типы ферментативных реакций, несмотря на то, что ей явно не сообщали эти правила. Иными словами, DeepMet, по-видимому, усвоила негласную «грамматику», которая связывает базовые строительные блоки — такие как сахариды и аминокислоты — в биологически реалистичные малые молекулы.
Прогнозирование новых, вероятно существующих молекул
Затем исследователи сгенерировали из DeepMet миллиард кандидатов и подсчитали, как часто появлялась каждая уникальная структура. Часто повторяющиеся структуры, как правило, походили на известные метаболиты, имели общие химические ядра с ними и соответствовали правдоподобным ферментативным преобразованиям. Чтобы проверить, соответствуют ли эти высокочастотные кандидаты реальным молекулам, команда сравнила предсказания DeepMet с метаболитами, которые были добавлены в Human Metabolome Database после окончания набора данных для обучения модели. DeepMet уже сгенерировала большинство этих поздних открытий и ранжировала многие из них среди наиболее вероятных кандидатов. Из тысяч топ-регистров, отсутствовавших в базах, авторы закупили или синтезировали 80 соединений и проверили реальные человеческие образцы с помощью масс-спектрометрии. Они подтвердили присутствие нескольких ранее нераспознанных метаболитов, некоторые из которых были упущены, хотя упоминались в существующей литературе.
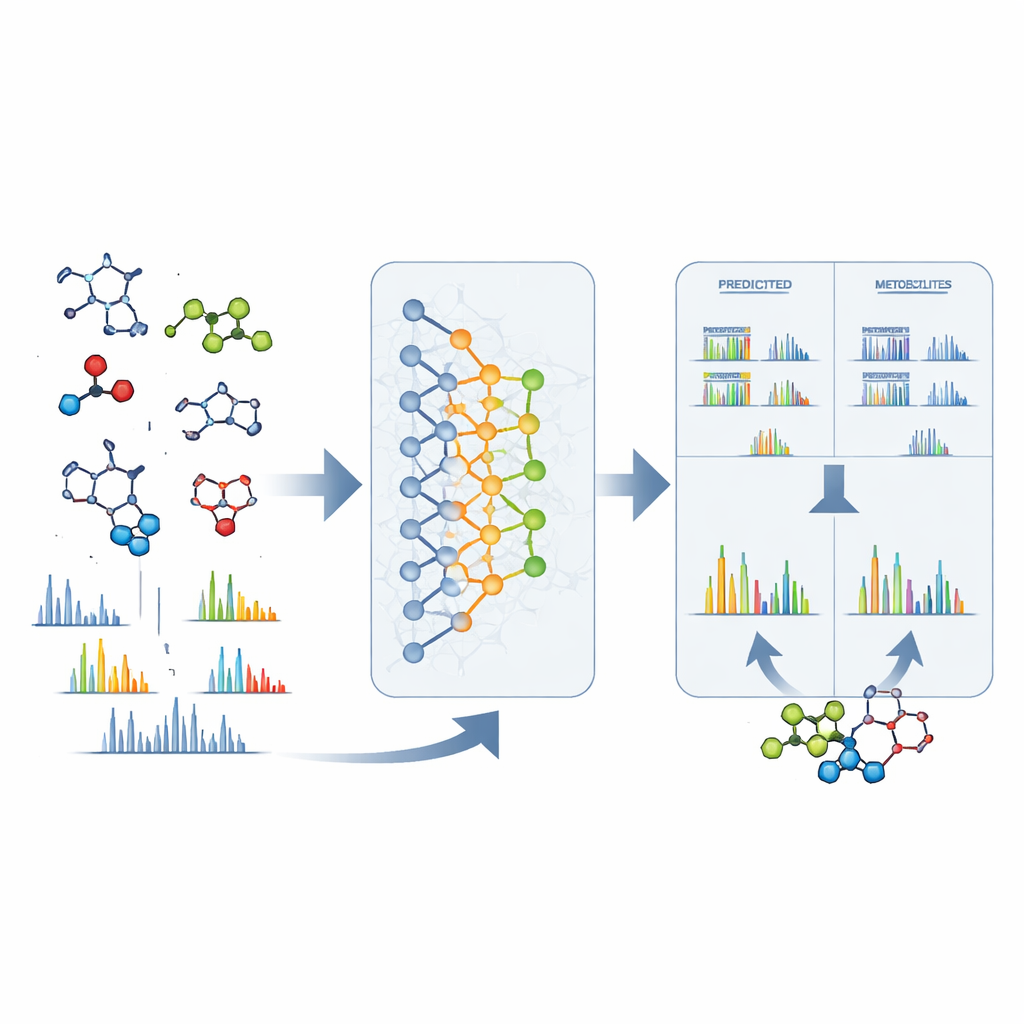
От необработанных сигналов к конкретным структурам
DeepMet также полезна, когда в масс-спектрометре обнаружен неизвестный пик. Имея только точную массу загадочной молекулы, модель может перечислить множество структур с такой массой и ранжировать их по степени «метаболитоподобия». Почти в трети тестовых случаев правильная структура оказывалась на первом месте; во многих других она появлялась среди небольшого числа высокоранжированных кандидатов и обычно была очень похожа по форме на фаворита модели. Чтобы ещё сильнее сузить круг, авторы совместили DeepMet с отдельным ПО, предсказывающим, как каждый кандидат распадается в масс-спектрометре. Сопоставление этих предсказанных паттернов с реальными спектрами примерно удвоило точность идентификации. Поиск в больших публичных наборах данных с использованием этого комбинированного подхода дал предварительные структуры для многих ранее анонимных сигналов и указал на метаболиты, различающиеся при болезнях, диетах и состояниях микробиома.
Освещение химической тёмной материи жизни
Сочетая химическую интуицию, извлечённую из данных, с мощным сопоставлением шаблонов масс-спектров, DeepMet предлагает дорожную карту для целенаправленного и практичного обнаружения новых метаболитов. Она ещё не в состоянии раскрыть каждую неизвестную молекулу — некоторые структуры лежат слишком далеко от того, что модель видела, а отдельные изомеры остаются неразличимыми без специализированных методов. Тем не менее исследование показывает, что инструменты в стиле языковых моделей не только способны «придумывать» реалистичные молекулы, но и предвосхищать реальные соединения, которые биологи затем подтверждают у животных и людей. Для неспециалиста вывод таков: ИИ теперь может помогать химикам системно обнаруживать скрытую химию в наших телах, потенциально выявляя новые биомаркеры, прослеживая связи «диета–микробиота–хозяин» и постепенно превращая сегодняшнюю метаболическую тёмную материю в хорошо изученную биологию завтрашнего дня.
Цитирование: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Ключевые слова: метаболомика, химические языковые модели, DeepMet, масс-спектрометрия, метаболическая тёмная материя