Clear Sky Science · ru
Выявление ключевых пиковых признаков для аутентификации оливкового масла с использованием рамановской спектроскопии и хемометрики
Почему история фальсификаций оливкового масла важна
Когда вы платите больше за бутылку оливкового масла, вы рассчитываете получить подлинный продукт, а не смесь, тихо разбавленную более дешевыми растительными маслами. Поскольку оливковое масло дорого и торговля им глобальна, фальсификации и неправильная маркировка — частые проблемы. В этом исследовании представлен быстрый неразрушающий метод обнаружения подобных подлогов: направление лазерного света на масла и анализ скрытых химических отпечатков с помощью умных компьютерных программ. Подход призван помочь защитить потребителей, добросовестных производителей и регуляторов, упростив проверку того, соответствует ли содержимое бутылки заявленному на этикетке.
Свет, читающий отпечатки масла
Исследователи использовали метод, называемый рамановской спектроскопией: направляют сфокусированный пучок света на образец и измеряют, как свет рассеивается. Разные молекулы по‑разному вибрируют, оставляя на спектре набор пиков, подобный штрих‑коду. Оливковое масло и распространённые фальсификаты — подсолнечное, рапсовое и кукурузное масла — имеют разные сочетания жирных кислот и природных пигментов, поэтому их спектры различаются. Изучая эти шаблоны на образцах чистых масел и тщательно приготовленных смесей, команда выделила небольшой набор «ключевых пиков», форма и интенсивность которых надёжно менялись в зависимости от доли оливкового масла в смеси.
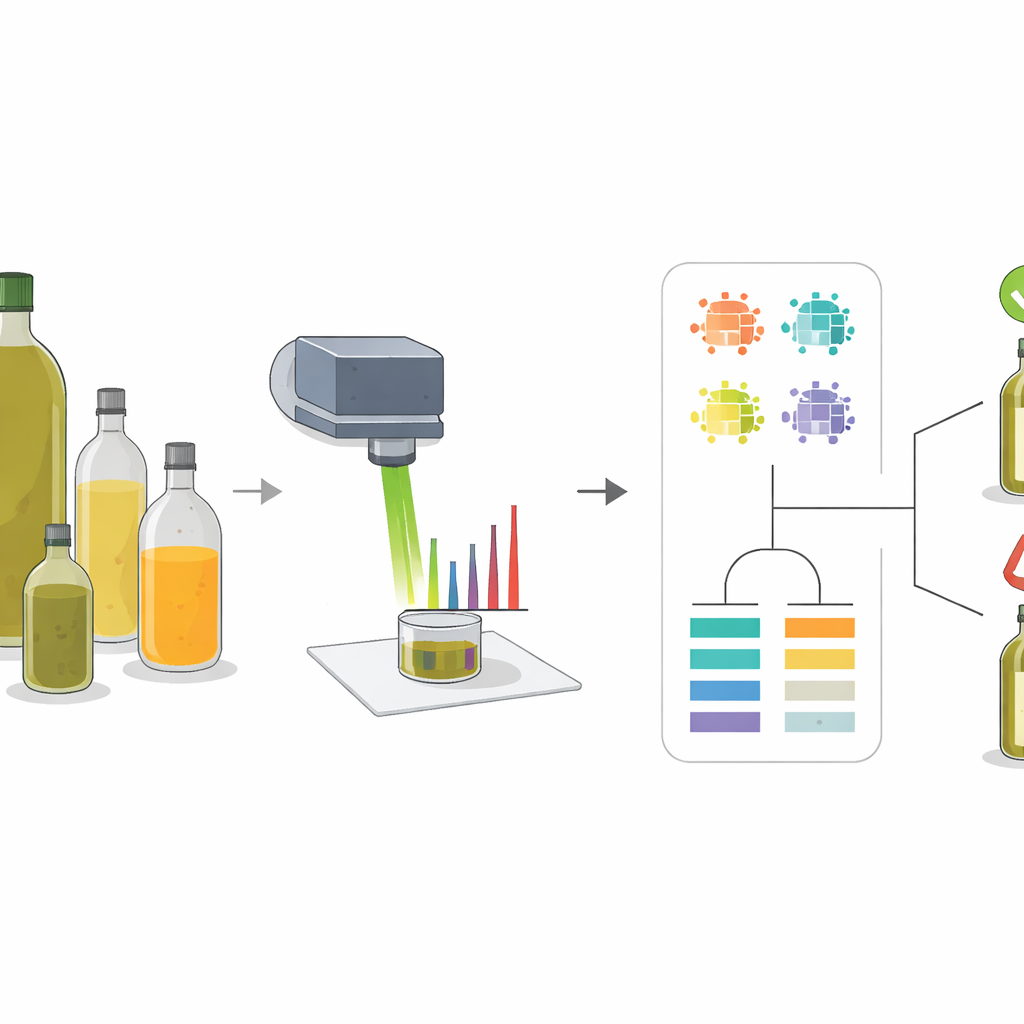
Поиск наиболее информативных сигналов
Вместо опоры на одно измерение команда извлекала несколько характеристик из каждого значимого пика: его высоту (интенсивность), занимаемую площадь, ширину на половине высоты и соотношение площадей с другими пиками. Затем использовали кластеризацию и карты корреляций, чтобы увидеть, как эти дескрипторы группируют разные масла и как они смещаются при увеличении доли оливкового масла. Пики, связанные с пигментами, такими как бета‑каротин, и с определёнными типами ненасыщенных жиров, оказались особенно информативными. Так, некоторые пики усиливались с ростом доли оливкового масла, тогда как другие ослабевали, поскольку были связаны с линолевой кислотой, более распространённой в подсолнечном масле. Такой многофакторный подход улавливал тонкие различия, которые были бы упущены при использовании лишь одного значения интенсивности.
Доверьте сортировку алгоритмам — честные и фальсифицированные образцы
Чтобы превратить спектральные отпечатки в практические решения, авторы обучили несколько моделей машинного обучения. Сначала они ставили задачу классификации десяти типов масел, включая четыре чистых масла и шесть видов бинарных и тернарных смесей. Деревья решений — случайные леса и градиентный бустинг на деревьях — показали лучшие результаты, практически верно относя почти все образцы к соответствующим категориям при использовании полного набора пиковых признаков. Затем те же модели применяли для численного предсказания: оценки фактического процентного содержания оливкового масла в смесях из двух и трёх масел. Снова подходы на основе деревьев превосходили более традиционные методы, точно отслеживая долю оливкового масла даже при сильном наложении сигналов от разных масел в спектрах.
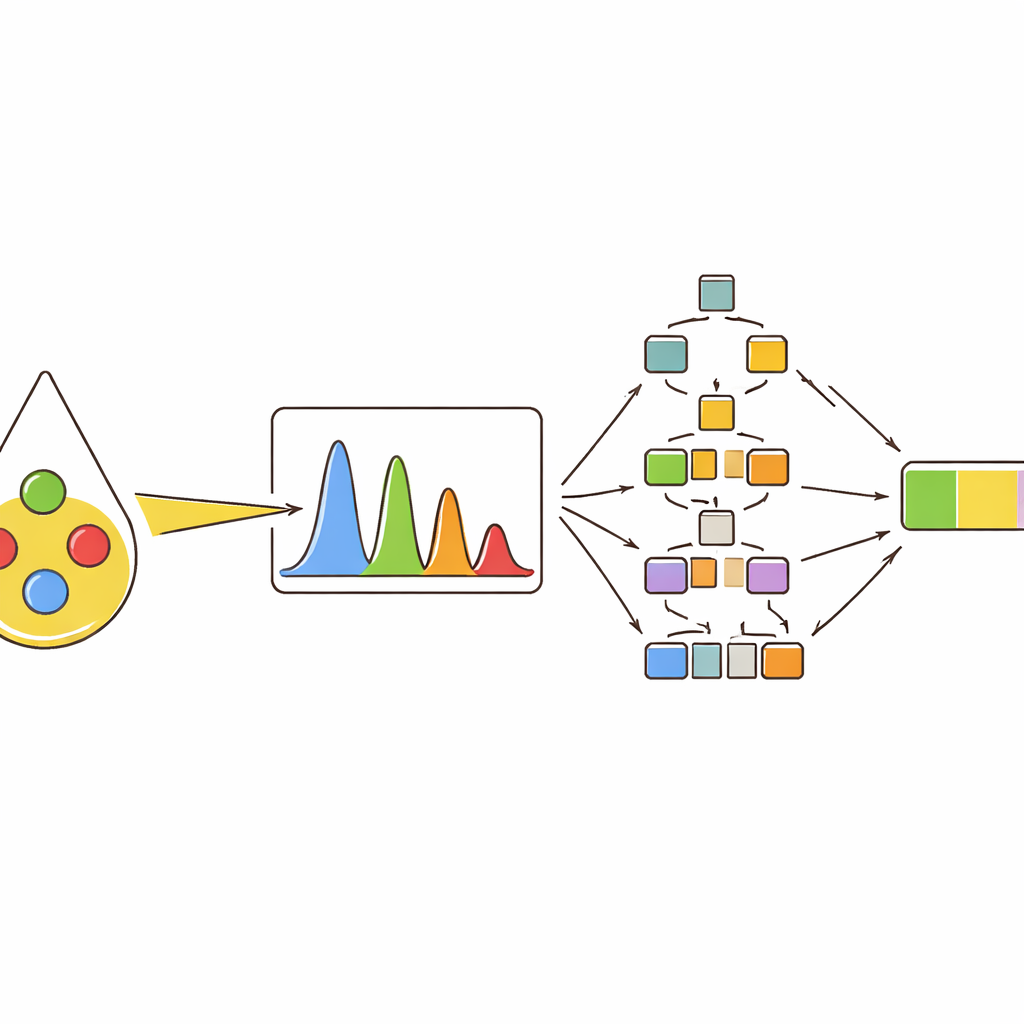
Открывая «чёрный ящик» умных моделей
Многие мощные инструменты машинного обучения трудно интерпретировать: они могут давать хорошие результаты, но не объяснять, почему было принято то или иное решение. Чтобы исправить это, исследование использовало метод объяснения, который присваивает каждой входной особенности вклад в итоговое предсказание. Это показало, что несколько конкретных пиков доминировали в решениях моделей, последовательно сдвигая прогнозируемую долю оливкового масла вверх или вниз в зависимости от своих значений. Те же пики постоянно появлялись как наиболее важные для разных типов смесей и в тестах на коммерческих супермаркетных образцах, содержащих лишь небольшое количество оливкового масла. Для этих реальных образцов лучшие модели оценивали долю оливкового масла очень близко к истинной, что подтверждает и точность, и прозрачность подхода.
Что это означает для вашей бутылки дома
Проще говоря, работа показывает: быстрый скан с помощью светового луча, интерпретируемый хорошо спроектированными и объяснимыми компьютерными моделями, может определить, является ли «оливковое масло» чистым, сильно разбавленным или находится где‑то посередине. Сосредоточившись на нескольких устойчивых спектральных признаках и комбинируя их в продвинутых, но интерпретируемых алгоритмах, исследователи создали инструмент, который можно интегрировать в рутинные проверки качества, потенциально даже в портативные устройства. Хотя нужны более широкие испытания на большем числе регионов, сортов и типов мошенничества, эта рамочная методика указывает на будущее, где проверка честности дорогих продуктов, таких как оливковое масло, станет быстрее, проще и надёжнее для всех.
Цитирование: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Ключевые слова: аутентификация оливкового масла, обнаружение фальсификаций продуктов, рамановская спектроскопия, машинное обучение, качество пищевых масел