Clear Sky Science · ru
Прогнозирование длин волн излучения с помощью машинного обучения, поддержанного текстовым майнингом, и экспериментальная валидация
Превращая научный текст в свет
Ежегодно учёные публикуют десятки тысяч статей о светоизлучающих материалах — веществах, используемых в экранах телефонов, медицинских сканерах и детекторах излучения. В этих статьях содержатся измерения того, какие именно цвета излучают разные материалы, но информация разбросана по тексту, написана непоследовательно и плохо читается компьютерами. В этой работе показано, как автоматически извлечь такие данные из литературы, собрать крупную и надёжную базу данных и затем применить машинное обучение для предсказания цвета света, который будут излучать новые материалы — что помогает исследователям гораздо быстрее разрабатывать лучшие фосфоры.
Почему светоизлучающие материалы важны
Фосфоры — это материалы, которые поглощают энергию и перенаправляют её в видимое излучение. Они лежат в основе таких технологий, как ультра‑высокое разрешение дисплеев, белые светодиоды, медицинская визуализация и детекторы радиации. Инженерам нужны фосфоры, которые дают точно определённые цвета, сохраняют яркость при высоких температурах и минимально теряют энергию. За последние два десятилетия исследования этих материалов резко возросли, и научная литература заполнилась подробными отчётами о составах и длинах волн излучения. Однако эти данные в основном спрятаны в неструктурированном тексте — фразах в абзацах, подписях и описаниях экспериментов, написанных для людей, а не для машин. 
Учим компьютеры читать статьи по материалам
Авторы построили специализированный конвейер текстового майнинга, ориентированный на литературу о фосфорах. Вместо использования универсальных языковых инструментов они разработали правила, понимающие, как химики на самом деле пишут формулы, особенно для «допированных» материалов, где в матрицу вводят малую долю другого элемента. Их система корректно распознаёт сложные названия, например матрицу‑хозяина с рядом ионов‑допантов и их концентрациями, и связывает эти названия с рядом стоящими числами, представляющими длины волн излучения. Она также справляется со сложными конструкциями, такими как предложения «излучает на 630 нм» без повторного упоминания названия материала, или абзацы, где вместе упомянуто несколько материалов и несколько длин волн. Классифицируя каждое предложение по числу содержащихся в нём материалов и свойств и затем подбирая соответствующий алгоритм сопоставления для каждой ситуации, конвейер существенно уменьшает путаницу в том, какое число относится к какому материалу.
Построение чистой карты состава к цвету
Применив этот конвейер к 16 659 журнальным статьям, команда извлекла около 6 400 надёжных «пара материал–излучение»: формулу фосфора, длину волны пика излучения, единицу измерения и цифровой идентификатор статьи. Тщательная проверка показала высокую точность как в распознавании полных формул фосфоров, так и в связывании их с правильными значениями длин волн. Имея эту структурированную базу данных, исследователи сосредоточились на особенно важной группе: материалах, допированных ионами европия (Eu²⁺), которые могут излучать по всему видимому спектру в зависимости от окружающей кристаллической среды. Они рассчитали физически значимые дескрипторы для каждой матрицы — такие как детали кристаллической структуры, длины связей и электронная ширина запрещённой зоны — и затем с помощью методов отбора признаков сузили их до нескольких ключевых параметров, наиболее важных для предсказания цвета.
Доверяем машинному обучению предсказывать свечение
Далее авторы обучили и сравнили несколько моделей машинного обучения для предсказания длины волны излучения по этим дескрипторам. Лучший результат показал алгоритм XGBoost, достигнув коэффициента детерминации (R²) около 0,91 на невидимых тестовых данных — сильный признак того, что модель улавливает ключевые зависимости между структурой и цветом. Чтобы проверить работоспособность подхода в реальных условиях, они использовали модель для предложения перспективных новых сульфидных и нитридных фосфоров с допированием Eu²⁺, синтезировали четыре кандидата в лаборатории и измерили их излучение. Наблюдаемые длины волн отличались от предсказаний лишь примерно на 10 нанометров, то есть «угадывания» модели оказались очень близки к экспериментальной реальности. 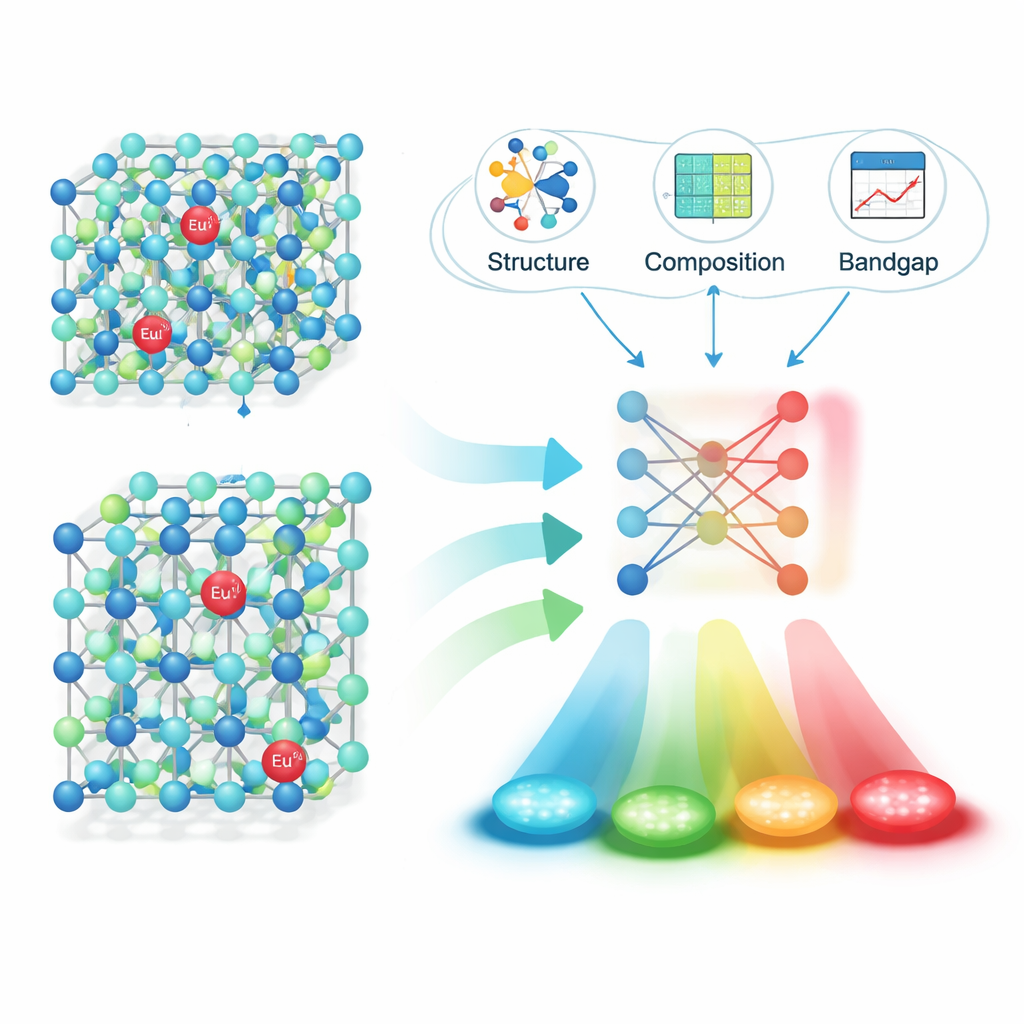
От статей к практическим решениям
Для неспециалистов ключевая мысль в том, что эта работа превращает разбросанные, написанные людьми статьи в согласованную, удобную для поиска карту, связывающую «из чего состоит материал» с «какого он цвета при свечении». Автоматизируя этапы чтения, организации и обучения — а затем подтверждая прогнозы реальными экспериментами — исследование описывает замкнутый цикл: текст → данные → модель → новый материал. Этот подход можно расширить на другие свойства, такие как яркость и стабильность, и даже на другие классы функциональных материалов. Таким образом он указывает на будущее, в котором вместо длительных проб и ошибок в лаборатории учёные смогут быстро фокусироваться на наиболее перспективных рецептурах, ускоряя разработку лучшего освещения, дисплеев и сенсорных технологий.
Цитирование: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Ключевые слова: люминесцентные материалы, текстовый майнинг, машинное обучение, фосфоры, прогнозирование длины волны излучения