Clear Sky Science · ru
Массивное параллельное нанопоровое считывание для профилирования пептидов и идентификации белков
Чтение белков по одному молекуле
Белки — рабочие лошадки наших клеток; знание того, какие именно белки присутствуют, как они модифицированы и как взаимодействуют, важно для понимания здоровья и болезней. Современные стандартные методы изучения белков мощные, но часто медленные, дорогие и трудн масштабируемы. В этой работе описан новый способ «прослушивания» отдельных фрагментов белков при их прохождении через крошечное отверстие в мембране с последующим применением искусственного интеллекта для преобразования сигналов в детальные отпечатки. Подход может открыть путь к более быстрым и дешевым тестам для отслеживания маркеров заболеваний и проверки реальной эффективности исследовательских и диагностических антител.
Преобразование белков в читаемые фрагменты
Авторы опираются на нанопоровую технологию, изначально разработанную для секвенирования ДНК. В их системе натуральные белки сперва расщепляют на более короткие фрагменты — пептиды — и мягко модифицируют так, чтобы каждый кусочек можно было связать с двух сторон короткими участками ДНК. Это создаёт структуру «Олиго–Пептид–Олиго», которая хорошо ведёт себя в нанопоровых устройствах, предназначенных для ДНК. Команда использует специфический фермент для разрезания, который обычно оставляет на конце каждого фрагмента определённую аминокислоту — лизин, — что делает химию более предсказуемой и совместимой с большим числом белков. В результате получают очищенную библиотеку множества таких конструкций пептид–ДНК, подготовленную всего за несколько часов.
«Прослушивание» с помощью множества нанопоров одновременно
Для фактического обнаружения этих пептидных фрагментов авторы используют массив биологических нанопоров — крошечных белковых отверстий в мембране, подключённых к электродам. При приложении напряжения структуры ДНК–пептид–ДНК поочерёдно протягиваются через каждый пор с помощью молекулярного мотора. Когда пептид проходит через самую узкую часть поры, он частично блокирует поток ионов, изменяя электрический ток. Платформа использует 256 пор параллельно и может собрать более 100 000 таких событий из одной библиотеки в течение двух часов, производя огромный поток сигналов от одиночных молекул, фиксирующих то, как каждый конкретный пептид взаимодействует с порой. 
От шумных сигналов к чётким отпечаткам
На первый взгляд эти токовые трассы выглядят шумными и переменными: один и тот же пептид может входить в пору в разных ориентациях и принимать разные конформации. Традиционные сводные показатели, такие как средний ток и длительность события, часто перекрываются для похожих пептидов. Ключевое достижение работы — двухступенчатая конвейерная схема на основе ИИ. Сначала глубокая сверточная нейронная сеть обучается на большом количестве трасс для классификации, какой пептид породил тот или иной паттерн. Затем команда строит «матрицы плотности», суммирующие, как сигнал меняется в ходе каждого события, по сути превращая облака шумных трасс в устойчивые двумерные отпечатки. Сохраняются только те считывания, чья детальная временная структура соответствует этим отпечаткам. Стратегия «CNN плюс отпечаток» повышает точность до примерно 99% для тестовых пептидов и надёжно различает фрагменты, отличающиеся одной аминокислотой, некоторые изомеры и многие распространённые химические модификации, приобретаемые белками в клетках.
Проверка антител и идентификация целых белков
Поскольку антитела распознают короткие участки белков, авторы применяют платформу для картирования, какие фрагменты действительно связывают различные коммерческие антитела. Смешивая перекрывающиеся пептидные куски предшественника гормона, обогащая те, что связаны каждым антителом, и затем считывая их нанопоровой системой, они могут точно определять предпочитаемые участки связывания и показывать, когда пары антител, рекомендованные поставщиком, на самом деле распознают одно и то же место и плохо подходят для «сэндвич»-ассэев. В другом тесте они исследуют известную тег-последовательность и четыре почти идентичных варианта, демонстрируя, что относительное число нанопоровых чтений для каждого пептида хорошо коррелирует со силой связывания антител, что согласуется с более трудоёмкими поверхностными измерениями. Наконец, они демонстрируют идентификацию белков: система обучается на пептидных отпечатках трёх человеческих белков, затем вслепую переваривают целые белки и показывают, что объединённый профиль классифицированных пептидов достаточен для корректного определения, какой белок перед нами, даже при наличии некоторых неоднозначных или отсутствующих фрагментов. 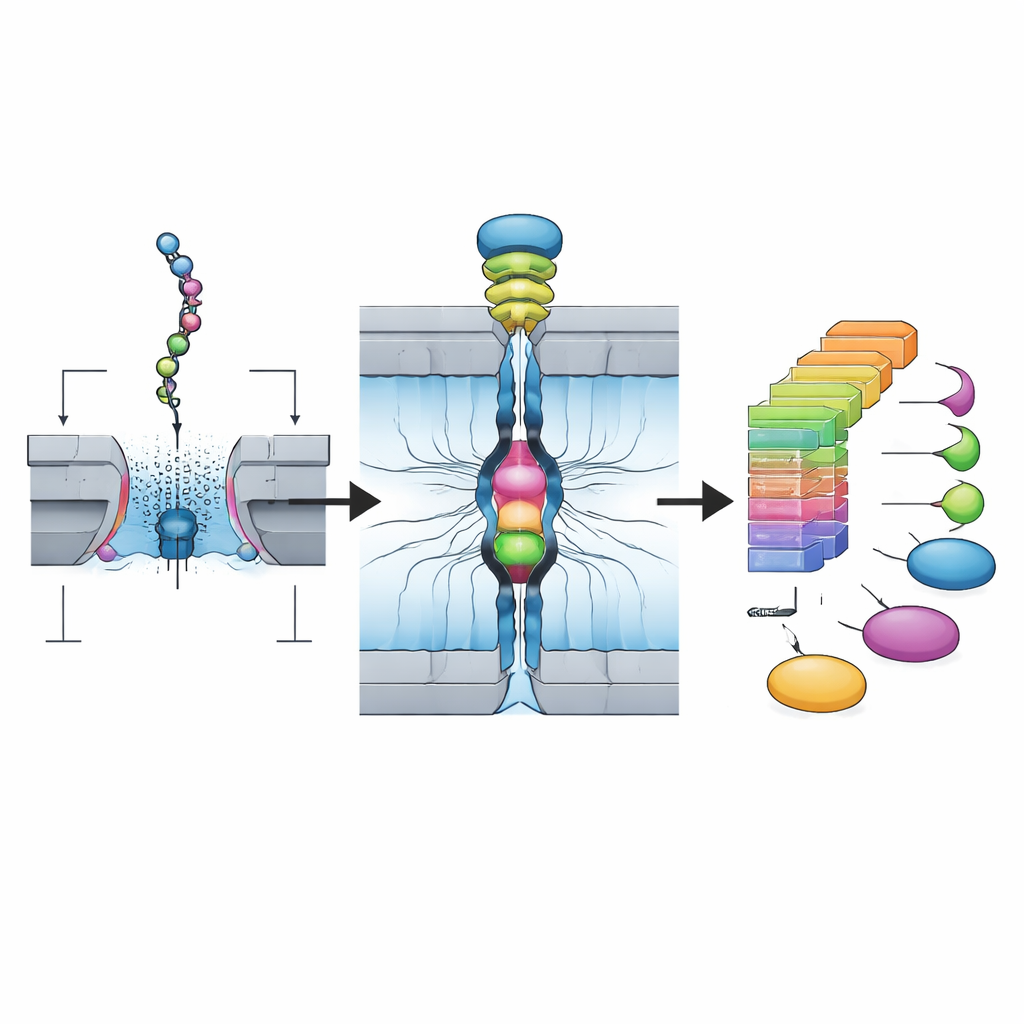
Почему это важно для будущих тестов
Проще говоря, исследование показывает, что секвенсор нанопоров в стиле ДНК, в сочетании с продуманной химией и ИИ, может выступать как высокопараллельный «стетоскоп» для пептидных фрагментов. Вместо того чтобы последовательно читать каждую аминокислоту, система опирается на богатые статистические отпечатки, полученные из тысяч событий от одиночных молекул, чтобы различать тонкие различия в заряде, размере и модификациях. Это позволяет быстро и недорого проверять качество антител и прокладывает путь к распознаванию целых белков по их пептидным профилям. Хотя остаются ограничения — например, трудности с некоторыми типами пептидов и необходимость качественных обучающих данных — работа описывает конвейер «от начала до конца», который может приблизить рутинный высокопроизводительный анализ белков к обычным исследовательским лабораториям и, в перспективе, к клинической диагностике.
Цитирование: Wang, J., Chen, J., Pan, H. et al. Nanopore-based massively parallel sensing for peptide profiling and protein identification. Nat Commun 17, 3058 (2026). https://doi.org/10.1038/s41467-026-69628-1
Ключевые слова: нанопоровое зондирование, протеомика, пептидный отпечаток, валидация антител, идентификация белков