Clear Sky Science · ru
Набор данных 7T fMRI со синтетическими изображениями для моделирования вне распределения в зрении
Почему это важно для понимания зрения и ИИ
Наши глаза воспринимают огромное разнообразие изображений каждый день — от лесов и лиц до дорожных знаков и шума на экране. Тем не менее большинство исследований мозга и искусственного интеллекта опираются на узкую часть этого визуального мира: фотографии природных сцен. В этой статье представлен новый тип набора данных мозга, который сознательно выходит за пределы этой зоны комфорта, используя тщательно спроектированные синтетические изображения, чтобы подвергнуть стресс‑тестированию как наши теории человеческого зрения, так и модели ИИ, вдохновлённые ими.
Создание новой визуальной испытательной платформы
Авторы расширяют влиятельный набор данных Natural Scenes Dataset (NSD), в котором регистрировали ультра‑высокое разрешение активности мозга на 7‑Тесла МРТ, пока участники просматривали десятки тысяч фотографий. Этот исходный набор уже послужил основой для создания одних из самых точных моделей того, как зрительная кора реагирует на изображения. Но поскольку все эти изображения — относительно обычные фотографии, трудно понять, действительно ли модель, хорошо работающая на NSD, улавливает общие принципы зрения или просто адаптировалась к конкретному «рациону» изображений. Чтобы решить эту проблему, команда просканировала тех же восьми добровольцев снова, на этот раз показав им 284 «синтетических» изображения, которые намеренно выходят за рамки привычного мира фотографий.
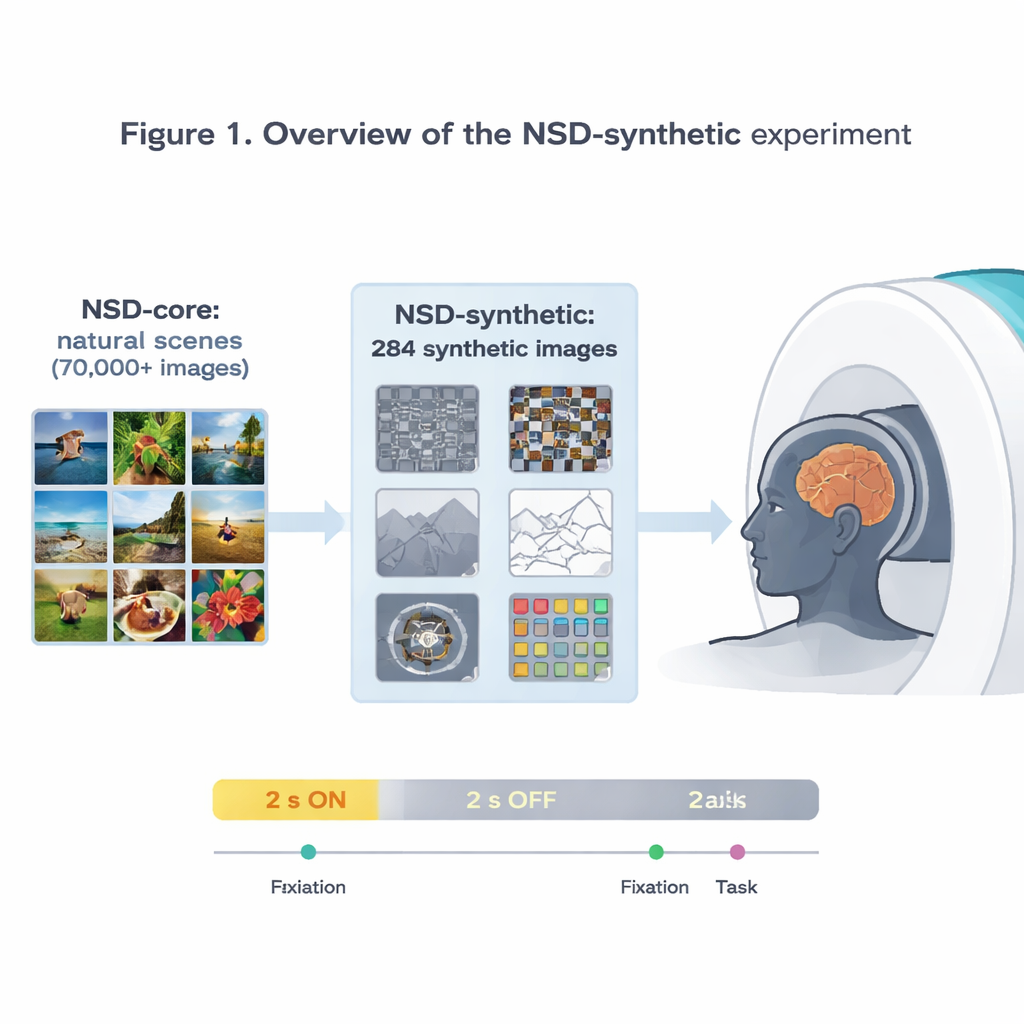
Странные изображения, надёжные реакции мозга
Синтетические изображения охватывают восемь семейств: разные виды визуального шума, простые природные сцены и их изменённые версии (например, перевёрнутые или линейные рисунки), сцены с пониженной контрастностью или перемешанной фазой, отдельные слова, размещённые в разных местах, спиральные решётки, проверяющие чувствительность к тонким узорам, и ярко окрашенные шумовые пятна. Пока участники либо фокусировались на крошечной мерцающей точке, либо выполняли простую задачу сравнения изображений, исследователи измеряли активность мозга каждые 1,6 секунды. Они показывают, что эти непривычные стимулы всё равно вызывают сильные, надёжные сигналы, особенно в ранних зрительных областях, реагирующих на базовые признаки — края, контраст и цвет. Шаблоны активности по коре соответствуют хорошо известным предпочтениям специализированных областей, например области, чувствительной к словам, которая сильнее реагирует на слова, расположенные в центре, и области, чувствительной к сценам, которая сильнее реагирует на изображения окружения.
Доказательство того, что данные действительно «вне распределения»
Чтобы этот новый набор данных бросал вызов моделям, реакции мозга на него должны истинно отличаться от ответов, вызванных природными фотографиями. Авторы сжали шаблоны активности как из оригинального NSD, так и из сессии с синтетическими изображениями в двумерную карту, отражающую схожесть ответов между изображениями. В этом пространстве ответы на синтетические изображения формируют отдельные кластеры, отличные от ответов на природные фото, даже с учётом различий между сессиями сканирования. Более того, синтетические изображения естественно группируются по визуальному типу — шум с шумом, решётки с решётками и так далее — что показывает: мозг организует эти стимулы в соответствии с их внутренней структурой, а не только по внешнему виду.
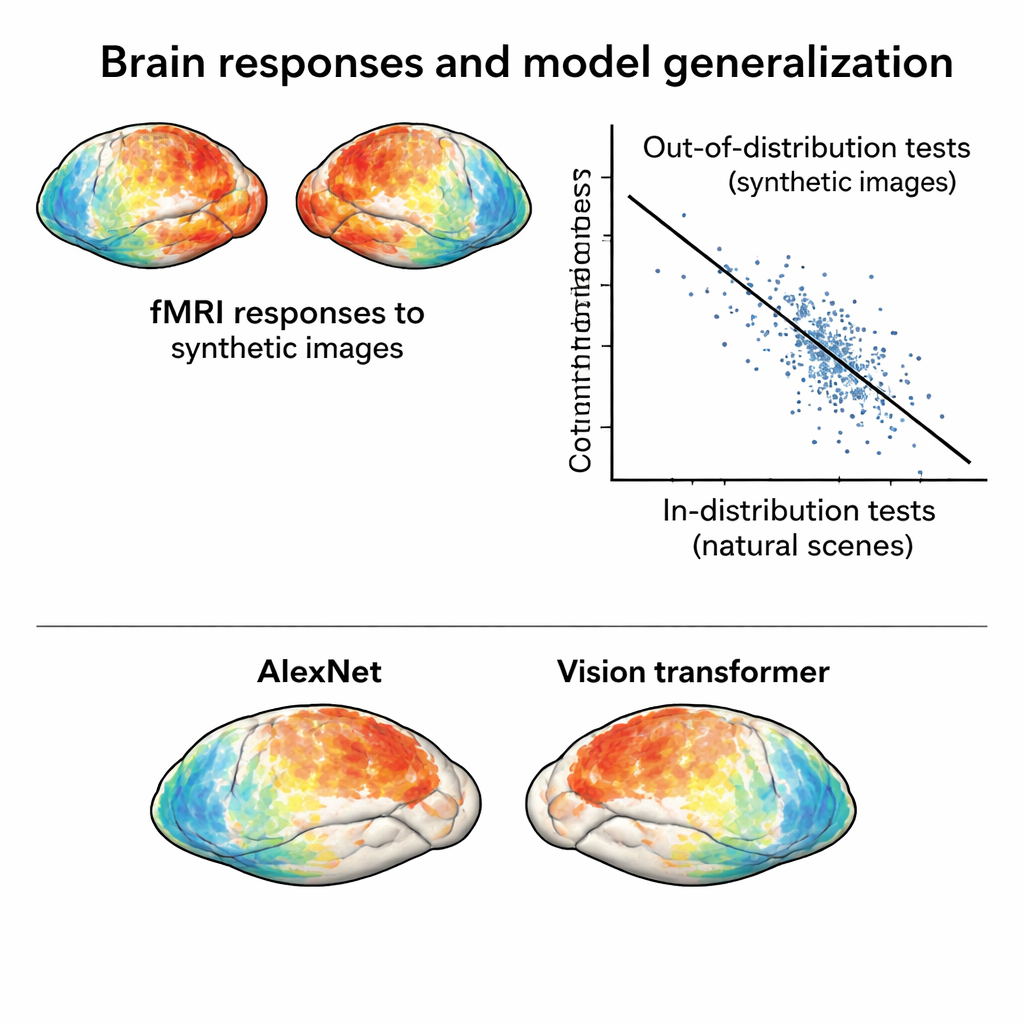
Ставим мозг и модели ИИ перед более жёстким испытанием
Имея этот новый набор данных «вне распределения», команда обучает стандартные кодирующие модели — математические инструменты, предсказывающие ответы мозга на основе признаков изображения, извлечённых глубокими нейронными сетями. Модели, обученные только на природных фото, показывают хорошие результаты при тестировании на похожих фотографиях, но их точность заметно падает при прогнозировании реакций на синтетические изображения. Это падение не связано с шумом в данных — ответы на синтетические стимулы на самом деле очень чистые — а отражает реальные провалы моделей. Что важно, сравнение разных архитектур нейросетей в этих более жёстких условиях выявляет различия, которые едва заметны при тестах в рамках распределения. Например, современный визуальный трансформер и самоконтролируемая сеть оба превосходят классические сверточные сети при работе с синтетическими изображениями, что указывает на то, что способ обучения модели сильно влияет на её устойчивость.
Как далеко модели могут уйти от знакомых изображений?
Авторы идут дальше и рассматривают «расстояние» от тренировочных данных как континуум, а не как ярлык «да/нет». Они измеряют, насколько далеко реакция мозга на каждое изображение находится от облака ответов на природные сцены. Чем дальше синтетическое изображение в этом пространстве, тем хуже обычно работают модели и тем менее точно можно определить, какое изображение видел человек, опираясь только на активность мозга. Они также показывают, что даже внутри мира обычных фотографий умело подобранные тестовые наборы могут вести себя как «слабо вне распределения»: модели лучше всего работают на изображениях из того же кластера, что и их тренировочный набор, хуже — на далёких природных сценах и ещё хуже — на синтетических стимулях. Эта градуированная картина превращает новый набор данных в инструмент для выяснения, какие именно виды визуальной структуры современные модели упускают.
Что это значит для будущих исследований мозга и ИИ
Для неспециалистов ключевое сообщение таково: высокие показатели на знакомых картинках не гарантируют, что вдохновлённая мозгом модель ИИ действительно воспроизвела то, как мы видим. Выпустив NSD‑synthetic вместе с оригинальным NSD, авторы предоставляют публичную «полосу для краш‑тестов» для моделей зрения: способ увидеть, где они ломаются, когда изображения становятся более абстрактными, более цветными или менее природными. Поскольку набор данных открыт и тесно интегрирован с уже существующим и широко используемым ресурсом, он, вероятно, станет стандартным эталоном для тестирования и улучшения теорий человеческого зрения и искусственных сетей, стремящихся имитировать его.
Цитирование: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Ключевые слова: зрительная кора, набор данных fMRI, синтетические изображения, вне распределения, глубокие нейронные сети