Clear Sky Science · ru
OmiGA для ультраэффективного картирования молекулярных количественных локусов признака
Почему это важно для здоровья и селекции
Современная генетика выявила миллионы различий в ДНК, которые тонко формируют такие признаки, как риск заболеваний, рост и обмен веществ. Большинство таких различий действует не за счёт прямого изменения белков, а путём точной настройки активности генов. Чтобы понять этот уровень регуляции, учёные сопоставляют «молекулярные признаки», например экспрессию генов, с геномом. В статье представлен OmiGA — новый аналитический набор инструментов, который делает такое картирование более точным и существенно быстрее, особенно в популяциях с большим числом родственников, например у сельскохозяйственных животных и в некоторых человеческих семьях. 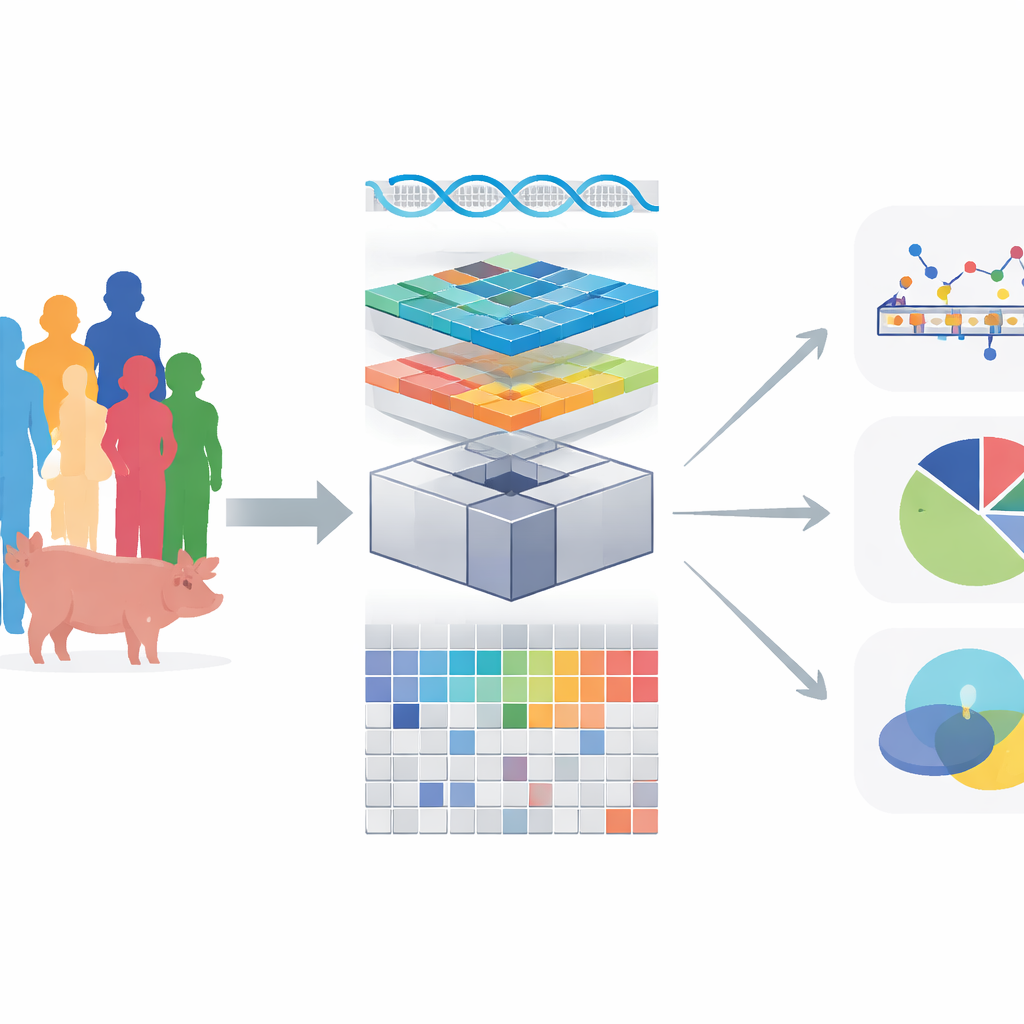
От ДНК к переключателям, управляющим генами
Вместо того чтобы смотреть только на внешние признаки, такие как рост или содержание жира, картирование молекулярных признаков выясняет, как варианты ДНК меняют внутренние показатели: какие гены включаются или выключаются, как сплайсится РНК и аналогичные измерения по тысячам генов и тканей. Участки генома, влияющие на эти молекулярные измерения, называются молекулярными количественными локусами признака (molQTL). Их обнаружение помогает проследить путь от изменения в ДНК до регуляции генов и далее до заболеваний или продуктивных признаков. Однако часто используемые инструменты упрощают статистику, чтобы сделать вычисления управляемыми. Они нередко игнорируют, насколько близки родственники между собой, или как целые участки генома наследуются совместно, что может породить ложные сигналы и скрыть реальные эффекты.
Почему родственная связь — статистическая головная боль
Во многих породах животных и в исследованиях человеческих семей индивиды разделяют большие сегменты ДНК из‑за недавних общих предков. Эта «сложная родственная связь» может заставить два удалённых генетических участка казаться связанными с одним и тем же молекулярным признаком просто потому, что они наследуются вместе, а не потому, что оба реально регулируют ген. Стандартные линейные модели пытаются частично исправить это, добавляя несколько сводных показателей происхождения, но они испытывают трудности, когда в геноме сильны дальние корреляции. Чем ближе родственная структура популяции и чем плотнее генетические данные, тем сильнее такие упрощения завышают кажущуюся силу сигнала, повышая частоту ложных открытий.
Специализированный движок для генетики в масштабе омics
OmiGA основан на линейных смешанных моделях — классе статистических инструментов, созданных для работы с родственной связью путём явного моделирования фонового генетического сходства между индивидами. Авторы переосмыслили эти модели для данных «омики», где десятки тысяч молекулярных признаков тестируют против миллионов вариантов ДНК. Они представили новые алгоритмы, которые избегают самых медленных шагов стандартных методов, повторно используют тяжёлые вычисления для многих признаков и могут выполняться на графических процессорах для дополнительного ускорения. OmiGA также оценивает, какая доля каждого молекулярного признака объясняется ближайшими вариантами ДНК, отдалёнными регионами и неаддитивными эффектами, где копии генов взаимодействуют более сложным образом. В совокупности эти возможности превращают ранее громоздкий подход в практичный инструмент для больших исследований. 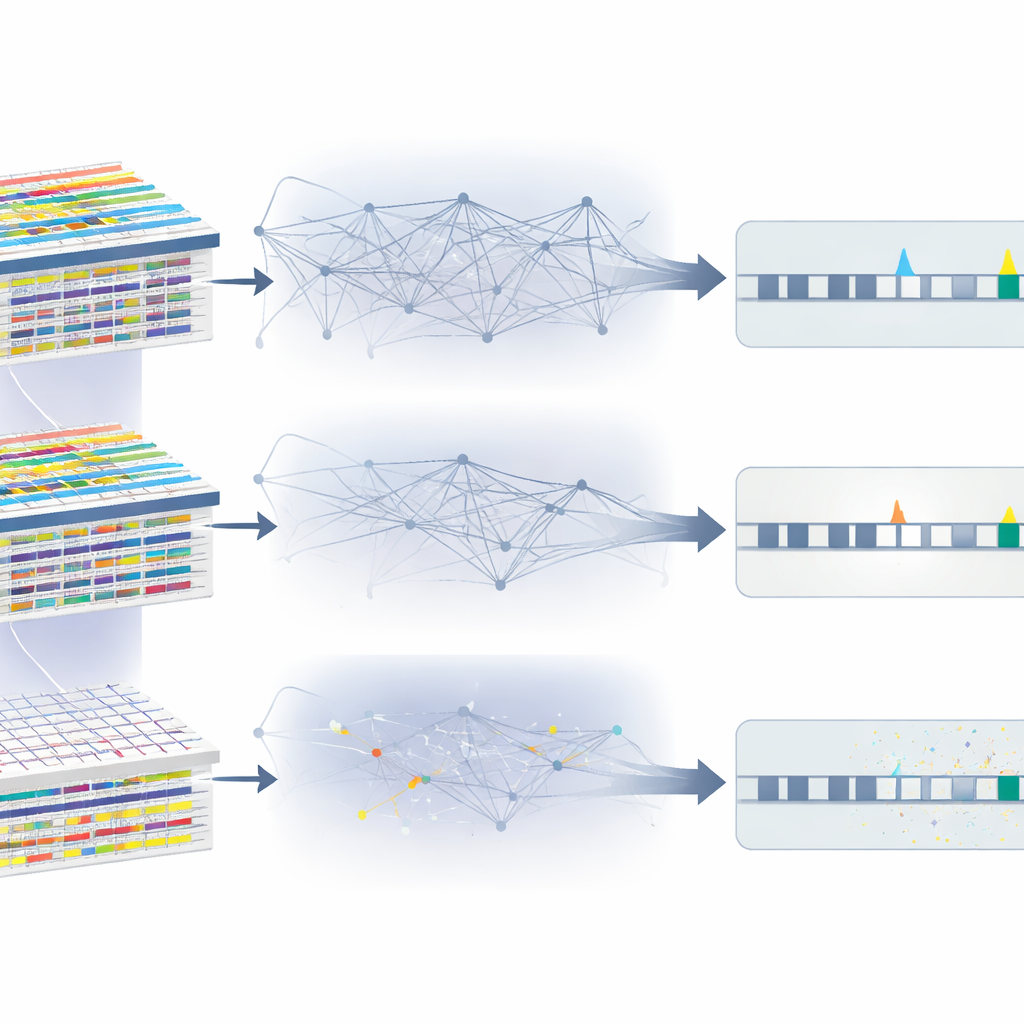
Более чёткие сигналы в симуляциях и реальных наборах данных
Авторы сравнили OmiGA с популярными инструментами, такими как tensorQTL, APEX, GCTA и LDAK, используя как смоделированные данные, так и реальные измерения у свиней и людей. В симуляциях, имитирующих тесно родственные популяции свиней и более слабо родственные когорты людей, OmiGA последовательно удерживал фоновый шум под контролем, одновременно поддерживая или увеличивая долю истинных открытий. В реальных данных по тканям свиней OmiGA выявил существенно больше генов, экспрессия которых явно связана с ближайшими вариантами ДНК, и сделал это при меньших вычислительных затратах. Он также дал более узкие наборы вероятных причинных вариантов при детальном изучении регионов и показал более сильное согласие между молекулярными сигналами и результатами традиционных ассоциаций признаков, что указывает на его лучшую способность точно локализовать истинные регуляторные изменения, лежащие в основе сложных признаков.
Новые взгляды на доминантность и контекстные эффекты
Помимо стандартных «аддитивных» эффектов, где каждая копия гена вносит независимый вклад, OmiGA умеет моделировать доминантные эффекты, когда одна копия может подавлять или усиливать другую. Применив это к данным человеческих клеток, авторы обнаружили, что многие гены с классическими эффектами также содержат скрытые доминантные влияния, а в некоторых случаях доминантная регуляция проявляется там, где аддитивных эффектов нет. OmiGA также выявляет контекст‑зависимую регуляцию, например генетические эффекты, которые отличаются в зависимости от происхождения или окружающей среды, и разделяет наследуемость на локальные и удалённые компоненты. Эти возможности открывают путь к более богатой картине того, как вариация ДНК формирует молекулярную биологию в различных популяциях.
Что это означает дальше
Для неспециалистов ключевая мысль такова: OmiGA предлагает более надёжный микроскоп для наблюдения того, как различия в ДНК настраивают активность генов, особенно в реальных популяциях, где родственники встречаются часто. Уменьшая количество ложных сигналов и выделяя истинно причинные варианты, он помогает более уверенно связывать молекулярные изменения с признаками, такими как риск заболеваний или качество мяса. Это, в свою очередь, может улучшить дальнейшие эксперименты, повысить качество селекционных решений в сельском хозяйстве и укрепить интерпретацию человеческих генетических исследований, показывая, какие регуляторные переключатели в геноме имеют наибольшее значение.
Цитирование: Teng, J., Zhang, W., Gong, W. et al. OmiGA for ultra-efficient molecular quantitative trait loci mapping. Nat Commun 17, 2680 (2026). https://doi.org/10.1038/s41467-026-68978-0
Ключевые слова: картирование молекулярных QTL, регуляция экспрессии генов, линейные смешанные модели, генетическая родственная связь, набор инструментов для омics