Clear Sky Science · ru
DNA-алмаз формирует раскладываемую модель созвездия составных букв для хранения данных в ДНК
Почему в будущем данные могут жить в ДНК
Наши телефоны, компании и научные приборы генерируют данные гораздо быстрее, чем могут расти емкости жёстких дисков и магнитных лент. ДНК — та же молекула, которая несёт генетическую информацию в живых организмах — также может использоваться для хранения цифровых файлов в исключительно компактной и долговечной форме. В этой статье представлен новый способ упаковать ещё больше информации в синтетические цепочки ДНК, сохраняя при этом практичность и надёжность чтения, что потенциально делает хранение в ДНК дешевле и более масштабируемым.
От четырёх букв ДНК к более богатым смесям
Традиционное хранение в ДНК использует четыре натуральные основания — A, T, G и C — для представления цифровых данных, подобно нулям и единицам на диске. В такой схеме каждая позиция в цепочке ДНК может нести максимум два бита информации, потому что ограничена одним из четырёх вариантов. Авторы развивают появляющуюся идею: вместо того чтобы помещать в каждую позицию одно основание, они создают внимательно контролируемые смеси оснований, называемые составными буквами. Например, позиция может состоять из 50:50 смеси A и T или 25:25:25:25 смеси всех четырёх оснований. При синтезе множества копий каждой цепочки секвенирование этих смесей выявляет пропорции оснований и, соответственно, цифровой символ, который может представлять более двух бит.
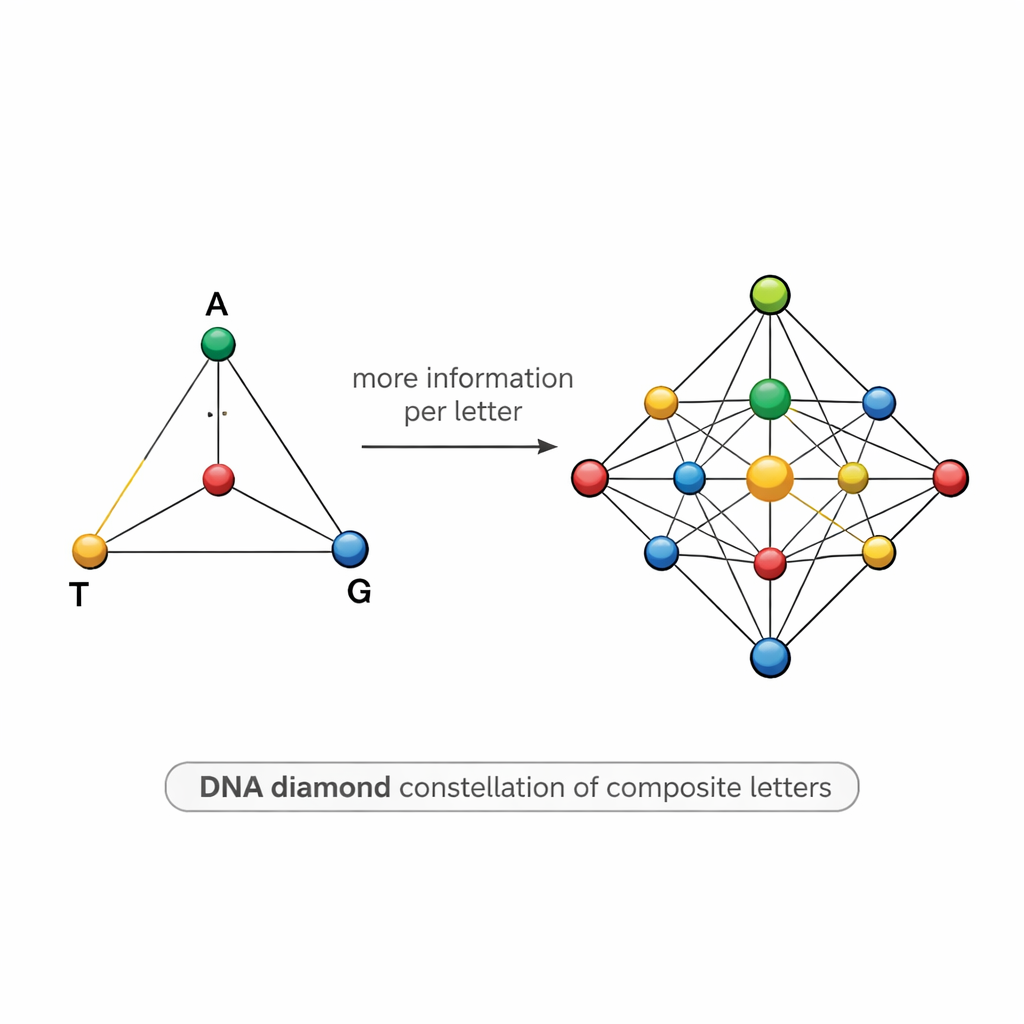
Бриллиантоподобная карта символов ДНК
Проектирование таких смесей непростое. Если два символа слишком похожи — например, один содержит 50% A и 50% T, а другой 55% A и 45% T — шум секвенирования может их смешать, вызывая ошибки и вынуждая учёных секвенировать гораздо больше копий, чем хотелось бы. Чтобы справиться с этим, команда предлагает структурированную модель «ДНК-алмаз»: набор из 15 составных букв, расположенных как точки на тетраэдре, вершины которого — A, T, G и C. Набор включает чистые основания в вершинах, равные смеси двух оснований вдоль рёбер, смеси трёх оснований на гранях и идеально равную смесь всех четырёх оснований в центре. Такая тщательно подобранная конфигурация повышает теоретическую информацию на позицию до примерно 3,9 бит, при этом символы остаются достаточно различимыми на практике.
Более умное декодирование с энтропией и индексированием
Чтение данных из ДНК означает вывод того, какая составная буква была намерена в каждой позиции, на основе зашумлённых измерений частот оснований. Авторы заимствуют стратегию из телекоммуникаций, называемую разбиением множества. Сначала они оценивают, насколько «смешанной» кажется позиция, используя величину, называемую энтропией, которая низка для чистых оснований и выше для сложных смесей. Это быстро относит каждую позицию к одной из четырёх групп: чистые основания, смеси из двух оснований, смеси из трёх или смесь из четырёх оснований. Затем внутри выбранной группы более точный расчет правдоподобия выбирает наиболее вероятную букву. Такой двухступенчатый подход уменьшает путаницу между символами и сокращает время вычислений по сравнению с ранними методами. Чтобы дополнительно избежать смешения разных фрагментов, каждая молекула ДНК несёт защищённые от ошибок индексные последовательности на обоих концах, а чтения неправильной длины — часто вызванные вставками или делениями — фильтруются до декодирования.
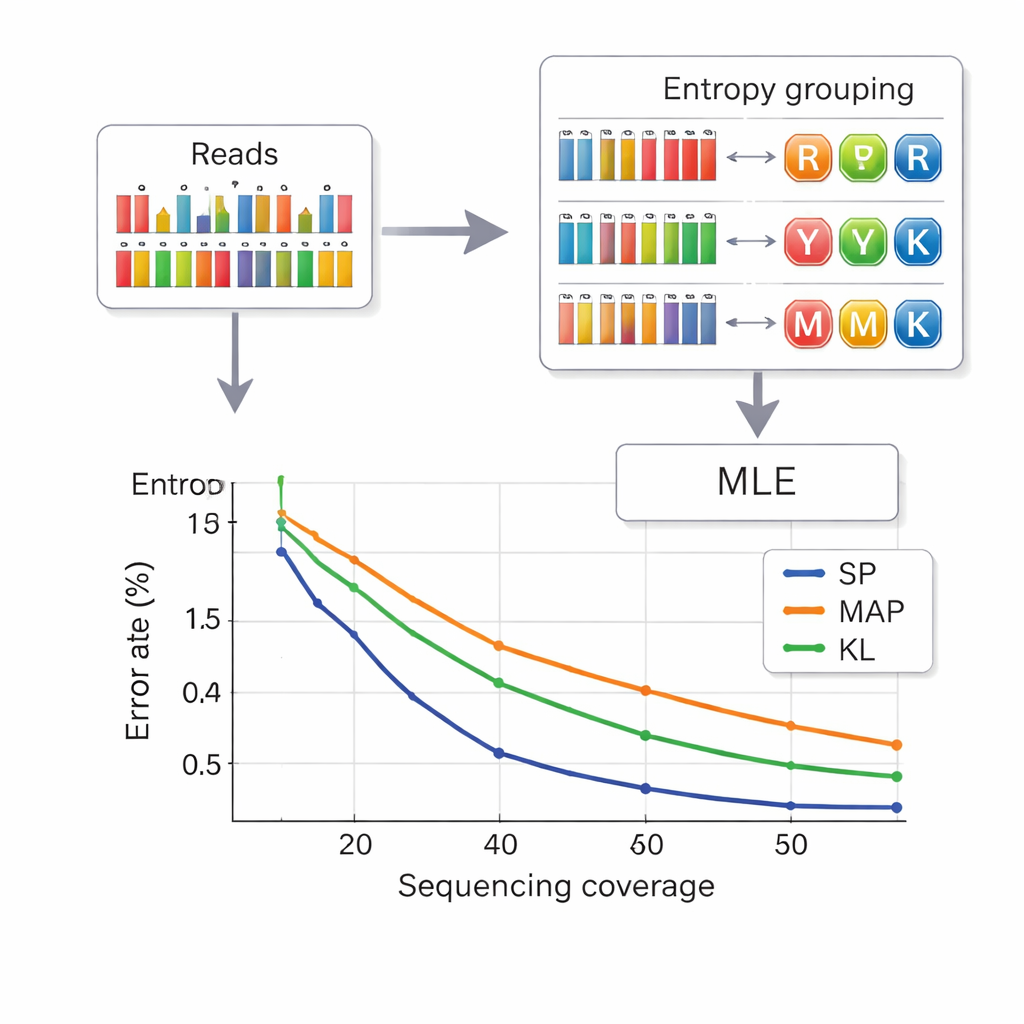
Упаковка больше данных при меньшем числе чтений
Исследователи протестировали свою систему как в небольших, так и в крупных пулах ДНК, используя коммерческие платформы синтеза. С восьмибуквенным составным алфавитом они достигли плотности полезной нагрузки 2,5 бита на позицию ДНК и смогли полностью восстановить файлы при среднем числе секвенирований 14 прочтений на цепочку — лучшая плотность по сравнению с предыдущими шестибуквенными схемами при меньшем числе чтений. С полным 15-буквенным алфавитом «ДНК-алмаз» они получили 3,125 бита на позицию для основной информации и также восстановили всё без ошибок при покрытии 33×. Моделирование и эксперименты показали также, что их метод на основе энтропии работает почти так же хорошо, как самый точный, но более медленный подход к декодированию, и явно лучше старых методов, особенно при меньших глубинах секвенирования.
Что это значит для будущей памяти
Для неспециалиста ключевое сообщение в том, что авторы нашли способ «научить» ДНК новым приёмам без изобретения новой химии: путём умного смешивания существующих четырёх оснований и более интеллектуального декодирования они могут хранить больше бит на молекулу при контролируемых затратах. Их бриллиантоподобный алфавит в сочетании с надёжным индексированием и исправлением ошибок показывает, что высокоёмкое хранение данных в ДНК возможно при относительно скромных усилиях по секвенированию. По мере того как синтез и секвенирование ДНК продолжают удешевляться, такие конструкции могут помочь превратить ДНК из лабораторного курьёза в реальный носитель для архивирования цифровой памяти мира.
Цитирование: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Ключевые слова: хранение данных в ДНК, составные буквы, плотность информации, исправление ошибок, цифровой архив