Clear Sky Science · ru
Достоверное предсказание номеров классификации ферментов с помощью иерархического интерпретируемого трансформера
Почему важно прогнозировать «работы» ферментов
Каждая живая клетка функционирует благодаря бесчисленным крошечным химическим «машинам» — ферментам. У каждого фермента есть конкретная «работа», закодированная в номере Enzyme Commission (EC) — четырёхуровневом коде, напоминающем почтовый адрес. Корректное присвоение EC-номеров имеет решающее значение для понимания метаболизма, разработки новых лекарств, проектирования микробов для производства топлива или заменителей пластика, а также для отслеживания того, как экосистемы перерабатывают химические вещества. Экспериментальное определение функций ферментов медленное и дорогое. В этом исследовании представлен HIT-EC — новая модель искусственного интеллекта, которая способна надёжно предсказывать EC-номера по последовательностям белков и при этом объяснять, почему было сделано то или иное предсказание.
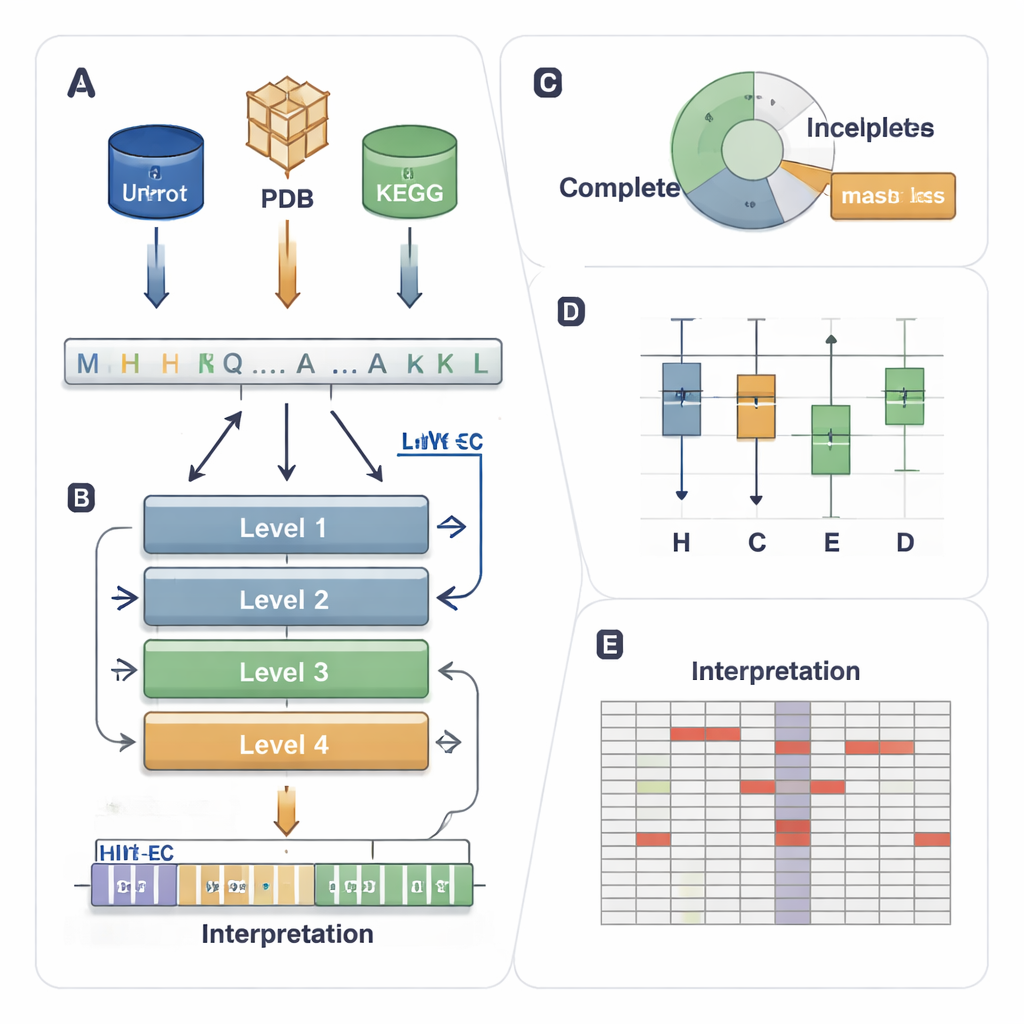
Система «почтовых индексов» для работы ферментов
Система EC присваивает каждому ферменту четырёхуровневый код, например 1.1.1.37. Первая цифра указывает на широкую класс- группу (например, ферменты, перемещающие электроны или переносящие группы), а последующие цифры описывают более точные детали реакции. Эта иерархия мощна, но делает задачу предсказания требовательной: модель должна правильно определить все четыре уровня среди тысяч возможных кодов, даже когда некоторые ферменты встречаются редко или частично аннотированы в базах данных (например, 3.5.-.-, где детальные уровни отсутствуют). Существующие вычислительные методы используют либо 3D-структуру, либо сходство последовательностей, либо глубокое обучение, но они часто испытывают трудности с редкими ферментами, игнорируют частично размеченные данные и обычно ведут себя как «чёрные ящики», дающие мало информации о причинах своих решений.
Четырёхэтажный ИИ, следующий лестнице EC
HIT-EC (Hierarchical Interpretable Transformer for EC prediction) создан так, чтобы отражать четырёхступенчатую иерархию EC. Он принимает исходную последовательность белка и пропускает её через четыре слоя трансформера, каждый из которых фокусируется на одном уровне EC. Локальные потоки связывают каждый уровень с предыдущим, обеспечивая согласованность тонких решений (четвёртой цифры) с более широкими (первой и второй цифрами). Параллельно глобальный поток сохраняет контекст всей последовательности на каждом этапе. Модель также можно обучать на последовательностях с неполными метками, используя «маскированную функцию потерь», которая просто игнорирует отсутствующие уровни EC вместо того, чтобы исключать такую последовательность. Это позволяет HIT-EC учиться на той большой доле белков в курируемых базах данных, которые аннотированы лишь частично.
Превосходство конкурентов по точности и скорости
Авторы собрали большую тщательно отфильтрованную выборку примерно из 200 000 ферментов с 1 938 различными EC-номерами из Swiss-Prot и Protein Data Bank. В повторных тестах с удержанием выборки HIT-EC превзошёл три ведущие метода (CLEAN, ECPICK и DeepECtransformer) как по глобальным, так и по классовым F1-метрикам, которые отражают баланс между корректными попаданиями и ложными срабатываниями. Он оказался особенно сильным для слабо представленных EC-кодов с 25 и менее известными примерами, где предыдущие методы часто давали сбой. HIT-EC также хорошо обобщал на новые ферменты, добавленные в Swiss-Prot после обучения, и на полные геномы различных бактерий, включая хорошо изученные штаммы Escherichia coli, Bacillus subtilis и Mycobacterium tuberculosis. Несмотря на сложность, модель была очень эффективной: на стандартном GPU она обрабатывала один белок примерно за 38 миллисекунд — в десятки раз быстрее некоторых конкурентов, зависящих от медленных поисков по сходству или ансамблей многих моделей.
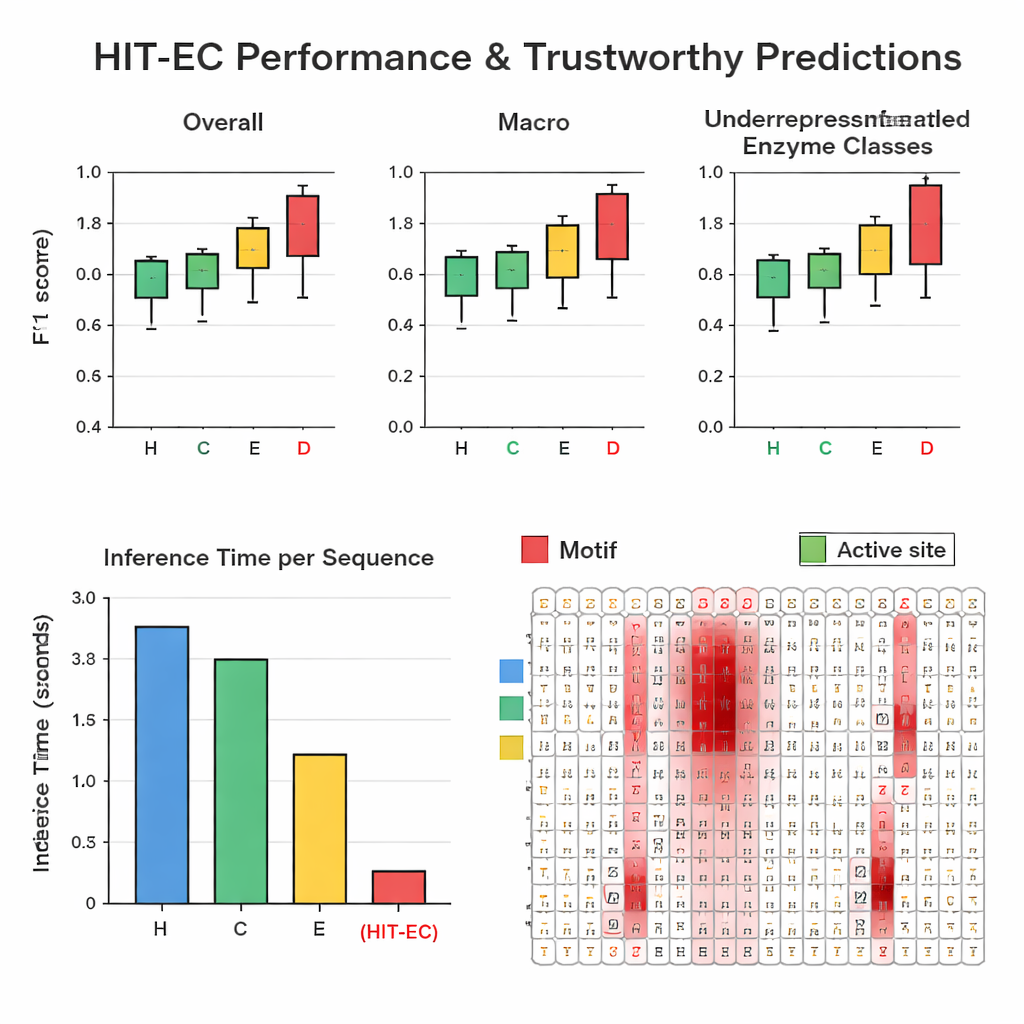
Видеть, на что «смотрит» модель
Чтобы сделать предсказания доверительными, HIT-EC спроектирован так, чтобы показывать, какие аминокислоты в последовательности повлияли на решение на каждом уровне EC. Авторы создали путь интерпретации, который сочетает веса внимания с градиентной информацией для оценки важности каждой позиции. Они валидаировали эти оценки на хорошо охарактеризованных семейств ферментов. Например, в семействе цитохрома P450 (CYP106A2) HIT-EC выделял известные функциональные мотивы, такие как участки связывания кислорода и гема, и обнаружил тонкий мотив EXXR, который упустила одна из эталонных моделей. Для классических представителей каждого верхнего уровня EC — таких как алкогольдегидрогеназа, гексокиназа и карбоангидраза — релевантные оценки модели подсвечивали учебниковые сигнатуры и сайты связывания субстрата. Эти интерпретации дают биохимические «доказательства» того, что модель основывает свои выводы на значимых признаках, а не на случайных корреляциях.
Помощь в изучении редких и появляющихся ферментов
Команда дополнительно протестировала HIT-EC на двух слабо изученных ферментах, важных для очистки загрязнений: цитохроме P450, участвующем в разложении ароматических загрязнителей, и гидролазе, разрушающей ПЭТ, из Streptomyces, помогающей расщеплять молекулы, связанные с пластиком. Оба фермента были экспериментально охарактеризованы, но не имели официальных назначенных EC-номеров. HIT-EC правильно предсказал ожидаемые EC-коды и выделил шаблоны мотивов и каталитические остатки, соответствующие известным данным из структурных и биохимических исследований. В целом работа показывает, что HIT-EC может не только присваивать EC-номера точнее и быстрее существующих инструментов, особенно для редких функций, но и прояснять, почему конкретному ферменту приписывают ту или иную химическую функцию. Такое сочетание эффективности и интерпретируемости делает модель перспективным инструментом для масштабной и надёжной аннотации ферментов в геномике, биотехнологии и экологических исследованиях.
Цитирование: Dumontet, L., Han, SR., Lee, J.H. et al. Trustworthy prediction of enzyme commission numbers using a hierarchical interpretable transformer. Nat Commun 17, 1146 (2026). https://doi.org/10.1038/s41467-026-68727-3
Ключевые слова: предсказание функций ферментов, глубокое обучение в биологии, модели трансформеров, аннотация белков, ферменты для биоремедиации