Clear Sky Science · ru
Обратно‑спроектированные нанофотонные ускорители нейронных сетей для ультракомпактных оптических вычислений
Почему важно уменьшать размеры компьютеров из света
Современный искусственный интеллект работает на массивном электронном оборудовании, которое потребляет огромные объёмы энергии и выделяет тепло. В этой работе рассматривается совершенно иной путь: использование крошечных узоров света на чипе вместо потоков электронов для выполнения частей вычислений нейронных сетей. Авторы показывают, что, «вылепливая» свет на наноскопическом уровне, можно создать ультракомпактные оптические ускорители, распознающие рукописные цифры и медицинские изображения, занимая при этом гораздо меньше места и, теоретически, значительно меньше энергии по сравнению с современной электроникой.
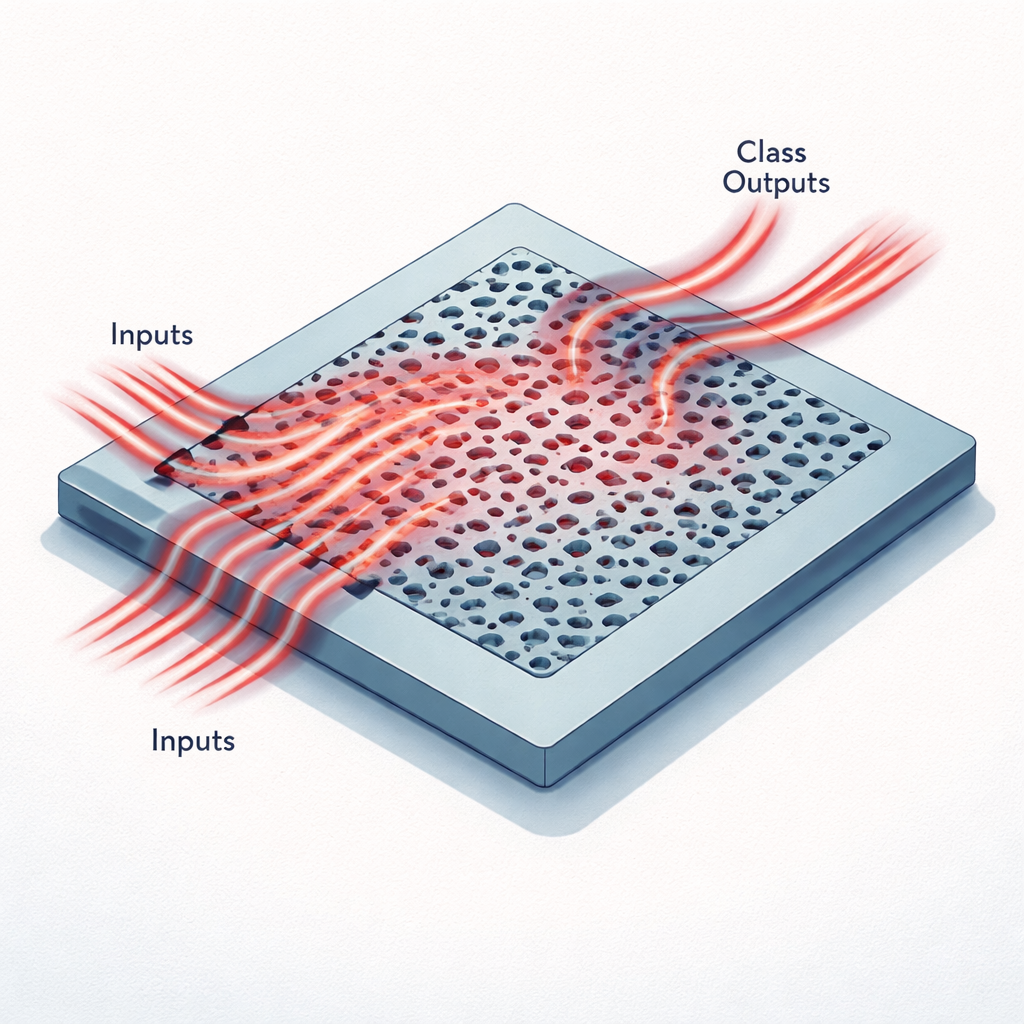
Крошечные чипы, которые думают светом
Вместо проводов и транзисторов эти ускорители используют плоский кусок кремния с узором из отверстий и каналов, размеры которых меньше длины волны инфракрасного света. Данные изображения сначала сжимаются до небольшого набора чисел, которые затем кодируются в яркости света, вводимого в несколько узких волноводов на одной телекоммуникационной длине волны. По мере того как этот свет проходит через структуру с узором, он рассеивается, интерферирует и перенаправляется в несколько выходных волноводов. Каждый выход соответствует возможному классу, например одной из десяти цифр в наборе MNIST или одной из шести категорий в медицинском наборе MedNIST. Распределение оптической мощности на выходах выполняет ту же роль, что и последний слой цифровой нейронной сети.
Когда алгоритмы рисуют оптическую схему
Спроектировать такую структуру вручную было бы почти невозможно, потому что каждая крошечная «воксель» материала может изменить поведение света. Исследователи вместо этого применяют подход обратного проектирования: они начинают с случайного рисунка кремния и стекла, моделируют распространение света в нём в трёх измерениях, а затем корректируют узор, чтобы уменьшить функцию потерь, измеряющую ошибки классификации. Они используют линейность уравнений Максвелла — законов, управляющих светом — чтобы сделать обучение эффективным. Вместо того чтобы моделировать каждое тренировочное изображение отдельно, они один раз моделируют каждый входной канал и затем восстанавливают поля для всех изображений как линейные комбинации этих предварительно вычисленных полей. Математический приём, называемый смежным методом (adjoint method), даёт точные градиенты, указывающие алгоритму, как сдвинуть каждую воксель, чтобы улучшить работу.

Компактные классификаторы изображений размером с песчинку
С помощью этой стратегии команда спроектировала два нанофотонных ускорителя нейронных сетей на стандартной платформе silicon‑on‑insulator. Один, площадью всего 20 на 20 микрометров, классифицирует рукописные цифры из набора MNIST; другой, 30 на 20 микрометров, классифицирует медицинские изображения из MedNIST. В моделировании эти крошечные устройства достигли точности 97,8% и 99,1% соответственно. Экспериментально изготовленные версии тех же дизайнов, испытанные с реальными лазерами и детекторами, показали 89% точности для MNIST и 90% для MedNIST — впечатляющие результаты с учётом крошечных размеров чипов. Оптические структуры вмещают примерно от 160 000 до 240 000 обучаемых параметров в областях меньше зерна пыли, что соответствует примерно 400 миллионам параметров на квадратный миллиметр.
Созданы для скорости, эффективности и масштабирования
Поскольку устройства пассивны — в них нет движущихся частей или перенастраиваемых элементов во время инференса — им не требуется постоянная подстройка после изготовления. «Веса» нейронной сети жёстко запрограммированы в геометрии наноструктуры, поэтому вычисления происходят на скорости света с по существу «в памяти» выполненной обработкой: свет входит с закодированными данными и выходит уже сведённым в значения классов. Метод обучения также спроектирован для масштабирования. Каждый шаг оптимизации требует лишь фиксированного числа полнофизических симуляций, определяемого числом входов и выходов, а не размером набора данных, и эти симуляции могут выполняться параллельно на нескольких графических процессорах. Авторы также описывают, как несколько таких оптических ядер можно сложить друг на друга с фотодетекторами между ними, подобно слоям глубокой нейронной сети, и как мультиплексирование по длине волны или во времени может увеличить пропускную способность.
Что это значит для аппаратного обеспечения будущего ИИ
Проще говоря, эта работа показывает, что возможно «выращивать» кастомные кусочки стекла и кремния, которые ведут себя как специализированные слои нейронных сетей, причём всё это в площади, достаточно малой, чтобы разместить на одном чипе сотни или тысячи таких элементов. Хотя полностью оптические компьютеры всё ещё в перспективе, эти обратно‑спроектированные нанофотонные ускорители могут снять с электронных процессоров часть самых энергоёмких задач ИИ. В сочетании с быстрыми модуляторами, детекторами и продуманной системной архитектурой они указывают путь к компактному, маломощному оборудованию, где свет, а не только электричество, выполняет значительную часть тяжёлой работы машинного обучения.
Цитирование: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Ключевые слова: фотонные нейронные сети, нанофотоника, оптические вычисления, аппаратные ускорители, обратное проектирование