Clear Sky Science · ru
Всеобъемлющее бенчмаркинг методов одно- и многонациональных поли генетических скорингов с платформой PGS-hub
Почему важен ваш генетический риск‑балл
Врачи становятся лучше в чтении нашей ДНК, чтобы оценивать, у кого выше вероятность развития распространённых заболеваний — например сердечных болезней, диабета или шизофрении. Эти оценки, называемые полигенными скорингами, объединяют крошечные эффекты множества генетических вариантов в одно число. Однако сейчас существует много конкурирующих способов вычисления таких скорингов, и они по‑разному работают для людей с разным происхождением. В этом исследовании авторы поставили цель напрямую сравнить ведущие методы и создать онлайн‑сервис PGS‑hub, который позволяет исследователям рассчитывать такие баллы единообразно и просто.
Универсальная платформа для калькуляторов генетического риска
Авторы создали PGS‑hub — веб‑платформу, которая скрывает большую часть технической сложности, связанной с полигенными скорингами. Пользователи загружают результаты генетических исследований, суммирующие, как миллионы маркёров ДНК связаны с заболеванием или признаком. Затем они выбирают популяционное происхождение интересующей их когорты — например европейское или африканское — и выбирают из меню популярных методов скоринга. Платформа автоматически преобразует входные данные в нужные форматы, подставляет заранее подготовленные референс‑панели, описывающие корреляции между соседними маркёрами ДНК, и выполняет большое количество заданий на вычислительном кластере. На выходе получается компактный файл весов, который можно применить к индивидуальным геномам, чтобы получить балл для каждого человека. 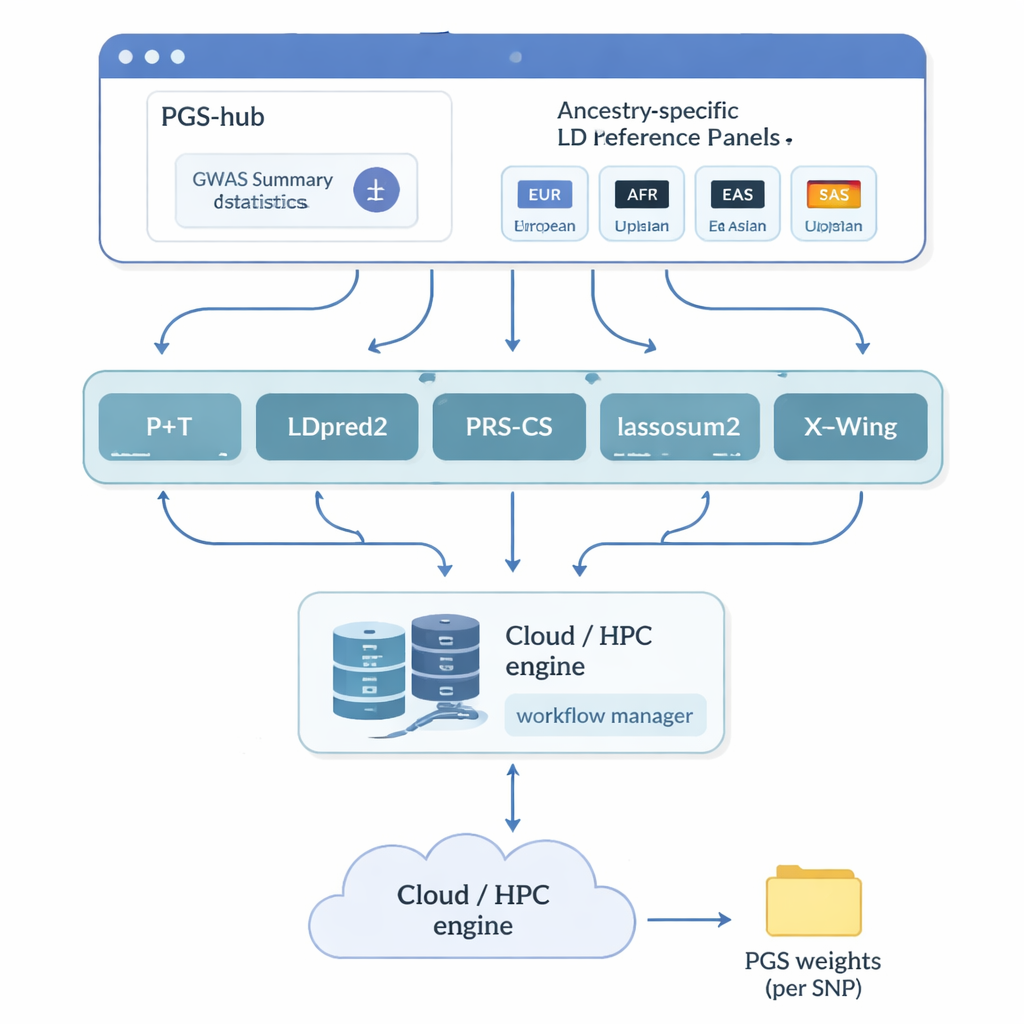
Тестирование 13 методов скоринга
Чтобы выяснить, какие подходы работают лучше, команда сравнила 13 современных методов на 36 заболеваниях и признаках в почти 380 000 людей европейского происхождения и чуть более 8 000 людей африканского происхождения из UK Biobank. Они оценивали не только насколько хорошо каждый скоринг предсказывал наличие заболевания или высокий уровень признака, но и сколько времени и памяти требовал каждый метод. Среди европейцев метод LDpred2 в целом давал самые точные скоринги и зачастую явно превосходил другие. Небольшая группа альтернатив — lassosum2, PRS‑CS и SDPR — во многих признаках показывала сопоставимые результаты, тогда как более старые подходы отставали. Для признаков вроде роста или болезни Крона лучшие скоринги объясняли значительную долю генетического риска; для других, например функции почек, все методы испытывали трудности, что отражает более слабые генетические сигналы.
Выводы для разнообразных популяций и комбинированных подходов
Ключевая проблема в генетическом прогнозировании — то, что модели, обученные в основном на европейцах, могут плохо переноситься на людей с другим происхождением. Когда авторы повторили бенчмарк на данных африканского происхождения, каждый метод показал ухудшение результатов, подчёркивая нехватку крупных исследований в этих популяциях. Тем не менее LDpred2 и SDPR обычно оставались среди лучших вариантов. Команда также изучила «многонациональные» подходы, которые явно объединяют информацию из разных популяций. Здесь относительно простая стратегия — линейное объединение лучших анастроспецифичных LDpred2‑скорингов в единый LDpred2‑multi — превзошла более сложные многонациональные модели, такие как PRS‑CSx и X‑Wing, как для европейских, так и для африканских групп. Плюс к этому авторы показали, что ансамбль, смешивающий сильнейшие скоринги из разных методов, дополнительно повышает точность предсказаний по всем признакам, особенно для высоконаследуемых заболеваний, таких как шизофрения и ишемическая болезнь сердца. 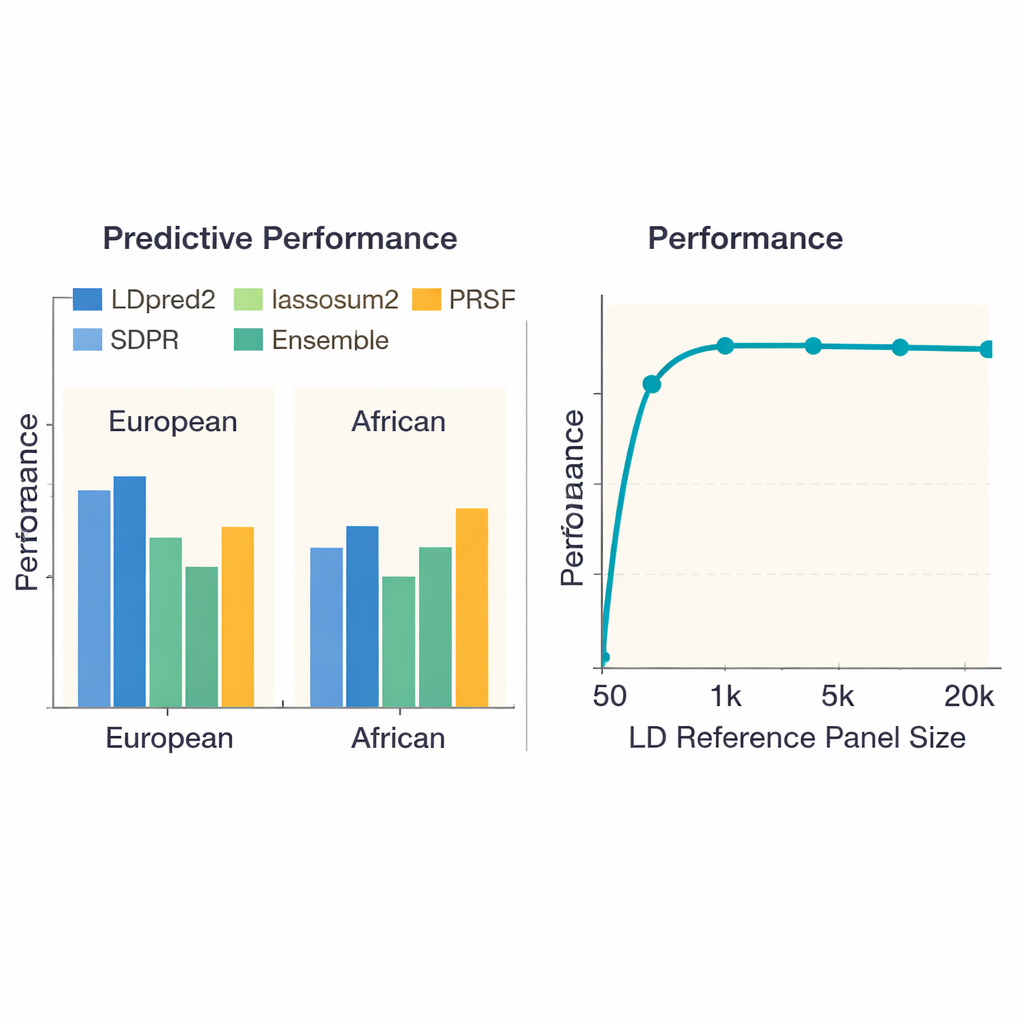
Как выбор данных и вычислительные ограничения влияют на скоринги
Исследование изучило, как размер референс‑панели — набора людей, используемых для оценки того, как соседние маркёры ДНК со‑вариируют — влияет на качество. Когда панель была очень маленькой (меньше 1000 человек), точность скорингов заметно падала. По мере роста панели до примерно 5000 человек производительность резко улучшалась, а затем выравнивалась, что говорит о том, что для очень больших панелей отдача снижается. Удивительно, но простое добавление большего числа маркёров ДНК не всегда помогало: использование около 6,6 миллиона вариантов иногда ухудшало предсказания по сравнению с тщательно подобранным набором примерно в 1,1 миллиона, вероятно потому, что лишние маркёры добавляли больше шума, чем полезного сигнала. Авторы также зафиксировали большие различия в вычислительных затратах. Простые методы, такие как базовая обрезка и пороговая фильтрация, выполнялись менее чем за час на признак, тогда как некоторые байесовские подходы требовали сотен CPU‑часов — важная информация для крупных проектов или групп с ограниченными ресурсами.
Что это значит для будущего генетического прогнозирования
Для неспециалистов главный вывод таков: не все генетические риск‑баллы равны, и детали их построения сильно влияют на то, кто от них выиграет. Эта работа даёт практическое руководство: методы вроде LDpred2 и хорошо продуманные ансамбли, как правило, дают наиболее надёжные прогнозы на больших европейских наборах данных, а многонациональные комбинации могут превосходить более сложные модели, рассчитанные на перекрёстные популяции. В то же время снижение точности для людей африканского происхождения подчёркивает острую необходимость в больших и более разнообразных генетических исследованиях. Объединив множество методов в одной стандартизированной онлайн‑платформе, PGS‑hub снижает барьеры для исследователей по всему миру в создании и сравнении полигенных скорингов — важный шаг к справедливому и эффективному использованию таких скорингов в медицине.
Цитирование: Chen, X., Wang, F., Zhao, H. et al. Comprehensive benchmarking single and multi ancestry polygenic score methods with the PGS-hub platform. Nat Commun 17, 2014 (2026). https://doi.org/10.1038/s41467-026-68599-7
Ключевые слова: полигенные скоринги, генетическое прогнозирование риска, платформа PGS-hub, многонациональная геномика, UK Biobank