Clear Sky Science · ru
Три нерешённых вопроса переносимости полиgenетических скорингов
Почему прогнозирование здоровья по ДНК сложнее, чем кажется
Врачи и исследователи всё чаще рассчитывают использовать на основе ДНК так называемые «полиgenетические скоринги» для оценки риска распространённых заболеваний — например, диабета, сердечно‑сосудистых заболеваний или астмы. Но эти оценки часто работают хорошо лишь у людей, которые похожи на исходных участников исследования, обычно европейского происхождения. В статье исследуется, почему такие прогнозы плохо «переносятся» на людей с другим генетическим фоном или жизненными условиями, и что это значит для справедливого применения генетических скорингов в медицине.
Чего обещают полиgenетические скоринги — и в чём они уступают
Полиgenетические скоринги объединяют ничтожно малые эффекты множества генетических вариантов по всему геному в одно число, предназначенное для предсказания признака — например роста или артериального давления. Их строят на основе масштабных исследований ассоциаций по всему геному (GWAS), которые связывают маркеры ДНК с признаками в сотнях тысяч добровольцев. Однако при переносе этих скорингов на новые группы людей точность оказывается сильно переменной. Как правило, способность предсказания ухудшается по мере того, как новая группа генетически или социально отличается от участников исходного GWAS. Это называют проблемой переносимости: скоринг, работающий в одном контексте, может вводить в заблуждение в другом и тем самым усугублять неравенство в здравоохранении при некритическом использовании.
Взгляд за пределы «предковости»: расстояние на генетической карте
Чтобы исследовать эту проблему, авторы использовали данные UK Biobank, содержащие генетическую и медицинскую информацию более 400 000 человек. Они построили полиgenетические скоринги для 15 высоко наследуемых признаков, таких как рост, масса тела, показатели кровяных клеток и уровень холестерина, на основе большой группы преимущественно белых британских участников. Затем они проверили, насколько хорошо эти скоринги предсказывают признаки у 69 500 других участников с широким спектром генетических предысторий. Вместо того чтобы относить людей к широким «коробкам» по происхождению, команда поместила каждого человека на непрерывную шкалу «генетического расстояния»: насколько профиль ДНК данного человека удалён от среднего участника GWAS при проекции на генетическую карту, основанную на главных компонентах.
Сила предсказания слабеет — но не просто и не справедливо
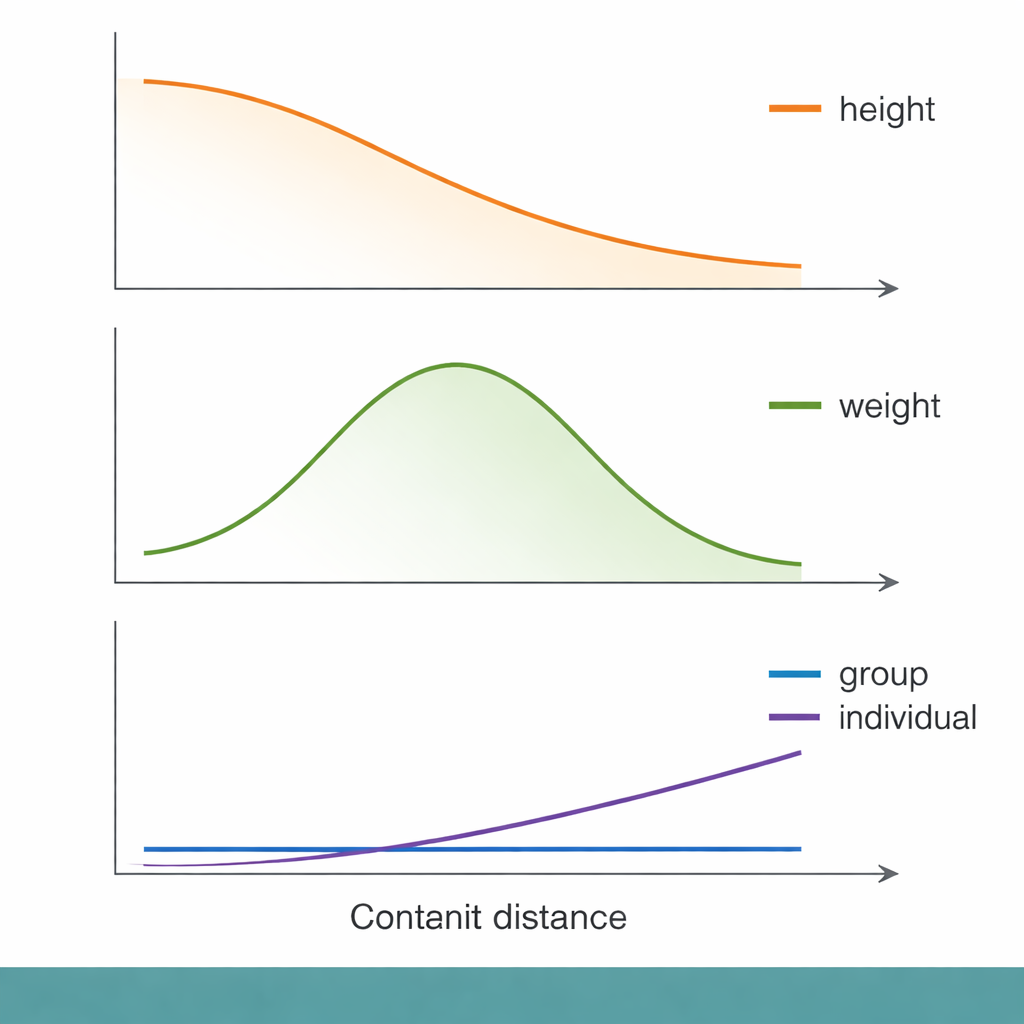
По этой шкале генетического расстояния проявились знакомые закономерности. Для роста, например, групповая точность предсказания плавно снижалась по мере увеличения генетической удалённости от группы GWAS. Однако при рассмотрении на уровне отдельных людей генетическое расстояние объясняло лишь малую часть того, насколько точно предсказывался признак. Социально‑экономические показатели, такие как индекс лишения Таунсенда (показатель материальной неблагополучности на уровне района), объясняли плохие предсказания примерно так же хорошо — а иногда и лучше. Иными словами, люди с более низким социально‑экономическим статусом в среднем получали менее точные генетические прогнозы даже в пределах одной и той же полосы генетического расстояния, что подчёркивает: социальный контекст может иметь такое же значение, как и ДНК, для полезности скоринга.
Разные признаки — разная история — разные ответы
Не все признаки вели себя одинаково. Для веса и доли жира в теле точность предсказания на самом деле достигала пика при промежуточных значениях генетического расстояния, а затем падала, что ломает простую модель «чем дальше, тем хуже». Иммунные признаки, например количество лейкоцитов и лимфоцитов, показали особенно загадочное поведение. Для некоторых из этих признаков групповая точность предсказания падала почти до нуля даже у людей, которые генетически не были сильно удалены от выборки GWAS. Авторы предполагают, что иммунные признаки могли формироваться под воздействием быстро меняющихся эволюционных давлений — например, исторических инфекций — которые меняют набор значимых генетических вариантов в разных популяциях. В таких случаях сама генетическая архитектура могла измениться настолько, что скоринг, построенный на одной группе, становится почти бесполезным в другой.
То, как мы оцениваем качество, меняет картину
Картина становится ещё сложнее, если изменить способ измерения «хорошего предсказания». Многие предыдущие работы опирались на одну статистику — R², которая отражает, какую долю вариации признака объясняет скоринг в группе. Авторы показывают, что другие метрики могут рассказать иную историю, особенно для заболеваний. Для астмы и точность (сколько из предсказанных случаев являются истинными) и полнота (сколько истинных случаев выявлено) снижались с генетическим расстоянием примерно одинаково. Но для сахарного диабета 2 типа точность оставалась относительно постоянной, тогда как полнота фактически увеличивалась с расстоянием — то есть скоринг находил большую долю истинных случаев в более далеких группах, хотя был построен на более близкой группе. В зависимости от того, важнее ли клинике обнаружить всех пациентов с высоким риском или избежать ложных тревог, можно сделать прямо противоположные выводы о переносимости скоринга.
Что это значит для использования ДНК‑скорингов в реальной практике
В целом исследование аргументирует: нельзя судить о полезности полиgenетических скорингов, опираясь лишь на широкие метки происхождения или на одно число точности. Качество индивидуального предсказания зависит от сочетания факторов: тонких паттернов генетического сходства, эволюционной истории каждого признака, условий среды и социальной среды, в которых живут люди, и от конкретного способа построения скоринга и выбора метрики его эффективности. Чтобы полиgenетические скоринги применялись справедливо и эффективно в медицине, исследователям потребуются лучшие методы учёта тонкой генетической структуры, моделирования социальных и экологических влияний и согласования оценочных метрик с практическими клиническими решениями. До тех пор генетические оценки риска следует использовать осторожно, учитывая группы и контексты, в которых они работают плохо, а не только те, где они показывают хорошие результаты.
Цитирование: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Ключевые слова: полиgenетические скоринги, генетическое прогнозирование, различия в здравоохранении, генетическое происхождение, персонализированная медицина