Clear Sky Science · ru
Физические нейронные сети с обучением, учитывающим остроту
Почему это важно для будущего аппаратуры ИИ
По мере того как искусственный интеллект становится мощнее, его ограничивает всё чаще не хитрость алгоритмов, а чипы, на которых они выполняются. Один перспективный выход — строить нейронные сети прямо в физическом оборудовании с использованием света, аналоговой электроники или других волновых систем. В этой статье представлен новый способ обучения таких «физических нейронных сетей», который позволяет сохранять точность в реальных, шумных условиях — когда устройства слегка неправильно собраны, возникают температурные дрейфы или компоненты теряют выравнивание.
От цифровых мозгов к физическим машинам
Современные системы ИИ обычно работают на цифровом оборудовании, например на графических процессорах, где обучение полагается на алгоритм обратного распространения ошибки для настройки миллионов численных весов. Физические нейронные сети стремятся перенести эти вычисления в реальные материалы и устройства — такие как фотонные чипы, сети интерферометров или дифракционные оптические схемы — поведение которых по сути воспроизводит вычисления нейронных сетей. Поскольку такие системы обрабатывают информацию там, где она хранится, они могут быть значительно быстрее и энергоэффективнее традиционных чипов. Но их обучение сложно: либо обучают цифровую модель и надеются, что она совпадёт с аппаратурой, либо обучают прямо на устройстве. Обе стратегии сталкиваются с проблемами, когда реальные приборы отклоняются от идеальной модели или со временем дрейфуют.
Два несовершенных способа обучения физических сетей
Первый подход, называемый in silico (в кремнии), обучает все параметры в компьютерной модели, а затем копирует их в аппарат. Это работает хорошо только если математическая модель почти полностью соответствует изготовленному устройству, что редко бывает правдой, когда учитываются вариации производства, электрические шумы и тепловые эффекты. Второй подход, in situ (на месте), включает физическое устройство непосредственно в процесс обучения, многократно измеряя выходы при изменении параметров. Хотя это обходит ошибки моделирования, возникают другие проблемы: градиентную информацию получить трудно и дорого, обучение становится специфичным для конкретного устройства, и полученные параметры обычно нельзя перенести на другой номинально идентичный чип. В обоих случаях небольшие изменения после развертывания — например крошечный температурный сдвиг или потеря выравнивания — могут резко снизить точность и потребовать дорогостоящего дообучения.
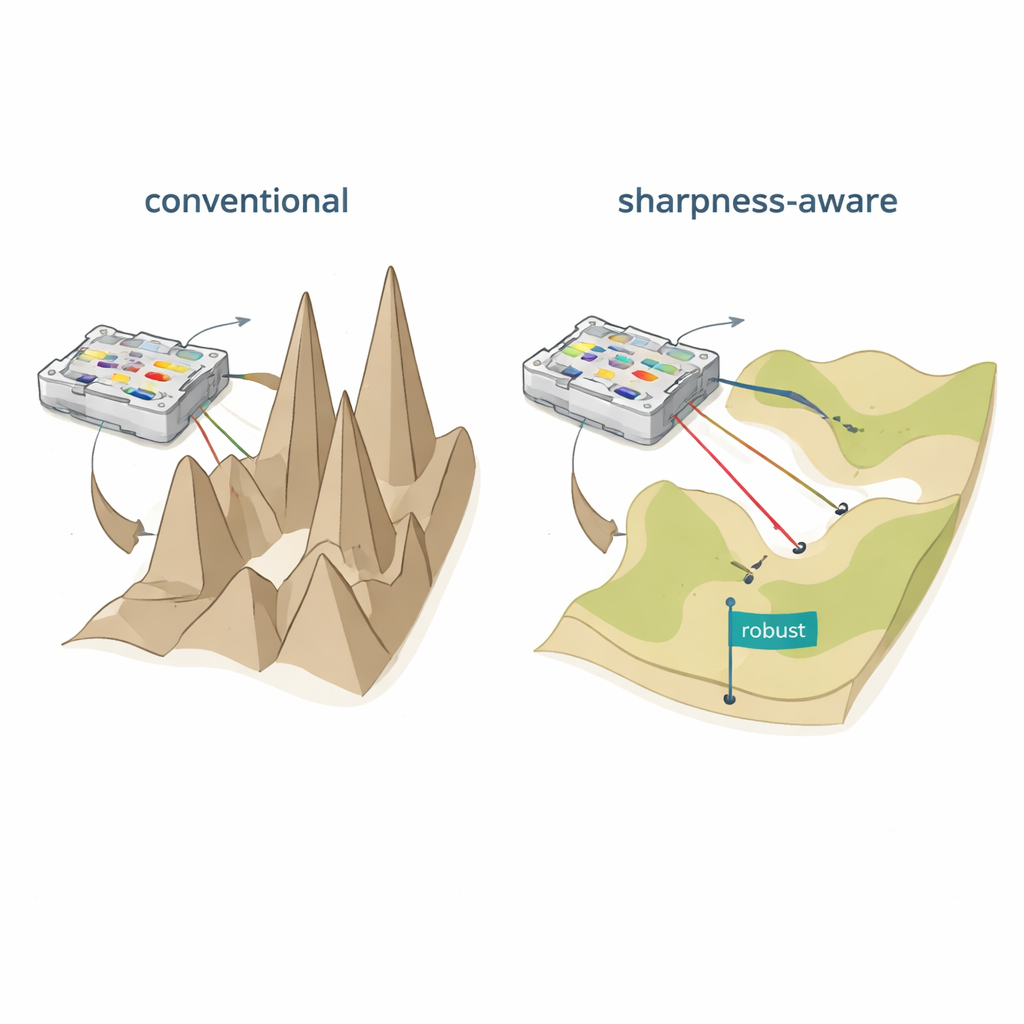
Выравнивание ландшафта потерь
Авторы предлагают обучение с учётом остроты (SAT), вдохновлённое идеей в машинном обучении под названием sharpness-aware minimization. Вместо того чтобы лишь находить настройки с низкой ошибкой на тренировочных данных, SAT ищет участки, где ошибка медленно меняется при небольших возмущениях физических параметров. Геометрически традиционное обучение часто приводит в глубокую, но узкую впадину на «ландшафте потерь», где даже крошечные сдвиги в токах, фазах или положениях приводят к падению эффективности. SAT целенаправленно ищет широкие, плоские впадины, где производительность остаётся высокой при подобных возмущениях. Математически это достигается добавлением в целевую функцию члена, штрафующего резкие, сильно искривлённые области в пространстве параметров, а этот штраф эффективно аппроксимируется двумя хитро подобранными шагами градиента вместо дорогостоящих расчётов вторых производных.
Доказательство устойчивости на разных оптических платформах
Чтобы показать, что SAT не привязан к какому‑то одному устройству, авторы применяют его к трём разным оптическим платформам нейронных сетей. На банках весов с микрокольцевыми резонаторами — крошечных кремниевых петлях, направляющих свет на разных длинах волн — они демонстрируют, что системы, обученные с помощью SAT, сохраняют высокую точность классификации даже при температурных дрейфах в несколько градусов Цельсия, тогда как стандартное обучение и методы с введением шума терпят серьёзные неудачи. Они расширяют это на более требовательные задачи, такие как классификация изображений на CIFAR-10, сжатие и восстановление изображений и генерация изображений, где SAT удерживает стабильную производительность, тогда как обычные методы ломаются при умеренных тепловых сдвигах. В моделях сеток интерферометров Маха–Цендера SAT-обученные модели значительно более толерантны к реалистичным погрешностям производства и, что важно, параметры, обученные на одном устройстве, можно переносить на другие чипы с иными дефектами без потери точности. Наконец, в системе с дифракционной оптикой в свободном пространстве, использующей OLED‑дисплей, линзы и пространственный модулятор света, SAT повышает устойчивость к физическим рассогласованиям — таким как поворот, сдвиги пикселей и масштабирование — даже несмотря на то, что точная связь между этими рассогласованиями и параметрами сети явно не моделировалась.
Практический путь к надёжному физическому ИИ
Проще говоря, эта работа показывает, как обучать аппаратные нейронные сети так, чтобы они «прощали» неизбежные особенности реальных устройств. Направляя обучение к плоским, стабильным регионам ландшафта ошибок, обучение с учётом остроты делает физические нейронные сети более точными и более устойчивыми к вариациям производства, температурным изменениям и механическим рассогласованиям. Поскольку метод можно применять с моделью или без неё и он работает на нескольких типах оптического оборудования, SAT предлагает практичный рецепт для масштабирования быстрых энергоэффективных физических ИИ‑систем от лабораторных демонстраций до реальных приложений.
Цитирование: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Ключевые слова: физические нейронные сети, фотонные вычисления, устойчивое обучение, оптимизация с учётом остроты, нейроморфное оборудование