Clear Sky Science · ru
Комплексная карта динамики модификаций РНК и их взаимодействий с помощью глубокого обучения и прямого нанопорового секвенирования РНК
Скрытая пунктуация РНК
Молекулы РНК в наших клетках — это не просто последовательности A, C, G и U. Они украшены множеством мелких химических меток, которые действуют как знаки препинания: помогают регулировать, какие гены включаются, как синтезируются белки и как клетки реагируют на стресс и болезни. До сих пор учёные в основном изучали эти метки по одной, что затрудняло понимание их совместной работы по всему геному. В этой статье представлен ORCA — система глубокого обучения, которая считывает нативные молекулы РНК напрямую и строит глобальную многослойную карту этих химических меток и их взаимодействий.
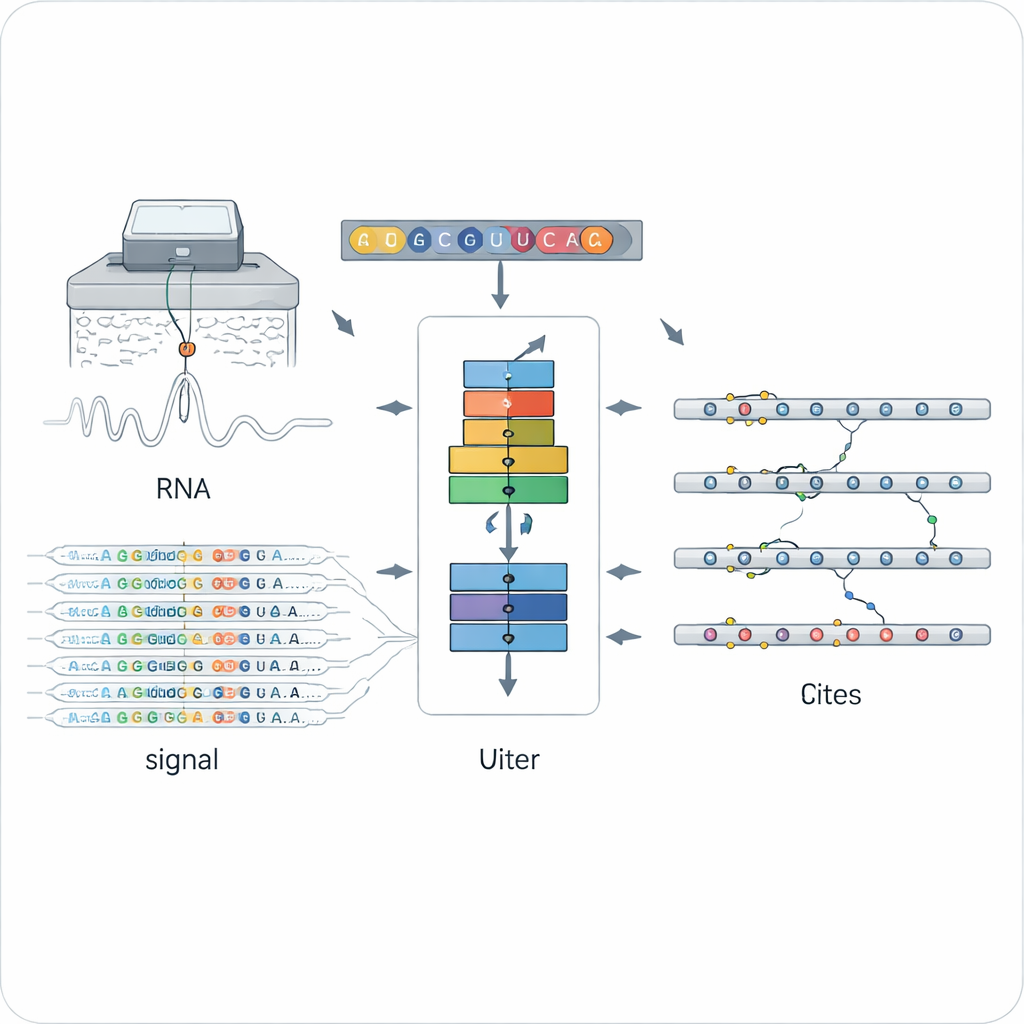
Новый способ читать химические метки на РНК
Традиционные методы обнаружения модификаций РНК обычно опираются на специальные антитела или химические реакции, настроенные на один тип метки, например широко изучаемое N6‑метиладенозин (m6A). Это делает их мощными, но узконаправленными: каждый метод выявляет лишь один вид метки, зачастую в одном экспериментальном контексте. Прямое нанопоровое секвенирование РНК открывает другой путь: молекула РНК протягивается через крошечное отверстие, и измеряются изменения электрического тока, зависящие от точной химической структуры основания. Модифицированные и немодифицированные буквы искажают сигнал и базовый вызов по-разному; однако интерпретация этого шумного, высокоразмерного сигнала для множества типов модификаций остаётся серьёзной задачей.
Обучение нейросети распознавать любые метки
ORCA (Omni‑RNA modification Characterization and Annotation) решает эту задачу в два этапа. Сначала модель сосредотачивается на небольшом окне вокруг каждой позиции в РНК и агрегирует как сырые электрические сигналы, так и паттерны ошибок секвенирования по многочисленным чтениям. Поскольку лишь часть копий РНК несёт конкретную метку, по-настоящему модифицированные сайты демонстрируют более смещённые распределения сигналов и более частые ошибки базового вызова в этой позиции. ORCA использует глубокую рекуррентную нейросеть, обучаемую с «адверсариальной» стратегией, что позволяет ей выучивать общие паттерны, отличающие модифицированные и немодифицированные сайты, не зацикливаясь на одном известном химическом типе. Это даёт возможность присваивать каждой позиции оценку модификации и оценочную долю молекул с модификацией.
Определение типа каждой метки
На втором этапе ORCA учится определять, какой именно химический тип метки присутствует. Авторы подают модели набор высоконадежных сайтов из общедоступных баз данных, где традиционные эксперименты уже идентифицировали m6A, 5‑метилцитозин (m5C), псевдоуридин (Ψ), инозин, 2′‑O‑метилирование и несколько редких модификаций. ORCA сжимает шаблоны сигналов, последовательностный контекст и короткие «мотивы» вокруг каждой позиции в пространство меньшей размерности, а затем дообучается предсказывать тип модификации и точную основание, на котором она располагается. Важный момент: немаркированные сайты также используются как «фоновые» примеры, что помогает модели не отождествлять неизвестные метки с неправильными категориями. После обучения ORCA может переносить эти ярлыки на десятки тысяч ранее неаннотированных позиций по всему транскриптому.
Одновременное обнаружение множества модификаций
Применяя ORCA к человеческим и мышиным клеткам, авторы демонстрируют, что система не только соответствует или превосходит по точности ведущие инструменты для отдельных меток, таких как m6A, m5C и Ψ, но и способна обнаруживать метки, на которых её прямо не обучали. Например, даже когда данные по m6A были исключены из обучения, ORCA восстановила большинство независимо измеренных сайтов m6A и правильно отличила их от похожих немодифицированных последовательностных мотивов. Аналогично происходило для 2′‑O‑метильных групп, сайтов редактирования инозина и широкого набора химических изменений в рибосомной РНК, включая многие редкие модификации, измеренные масс-спектрометрией. В целом ORCA существенно расширяет известный каталог сайтов модификаций РНК, обеспечивая многократный рост аннотаций m5C, Ψ, m7G и других низкоабундантных меток по сравнению с существующими базами данных.
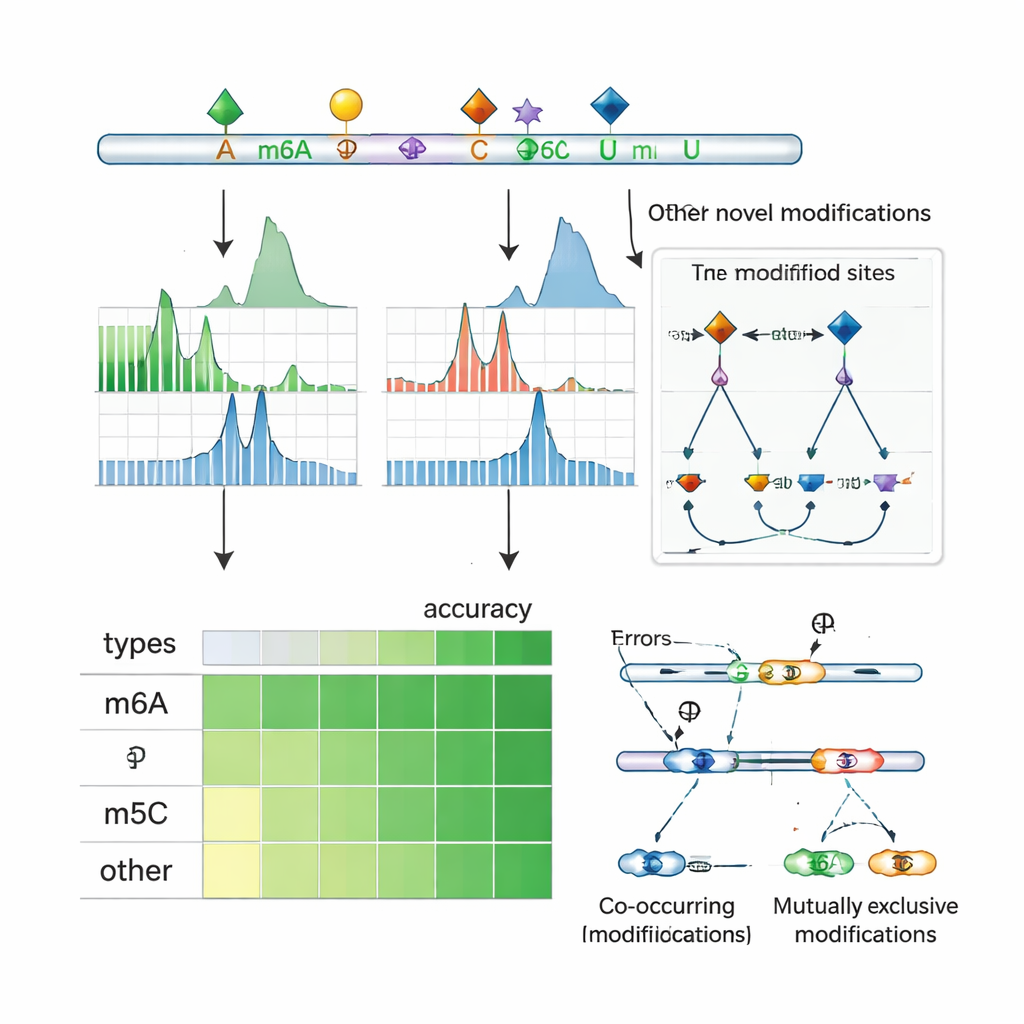
Выявление взаимодействий и контроля сплайсинга
Поскольку нанопоровое секвенирование считывает целые молекулы РНК, ORCA может анализировать, какие метки встречаются совместно на одном транскрипте и какие, напротив, взаимно исключают друг друга. Авторы группируют близко расположенные метки вдоль РНК и используют вероятностную модель, чтобы выводить, являются ли пары сайтов часто со-модифицированными или взаимоисключающими на отдельных молекулах. Они обнаруживают частое совместное появление m6A с m5C и другими метками, а также множество регионов, где одна позиция модифицируется только тогда, когда соседняя — нет. В человеческих клеточных линиях эти паттерны часто лежат рядом с экзонами, которые включаются или пропускаются альтернативно, и перекрываются с сайтами связывания регуляторов сплайсинга и «ридеров», распознающих модифицированную РНК. Для отдельных генов ORCA показывает, что определённые сплайс-варианты обогащены одним набором меток, тогда как альтернативные варианты несут другой набор, связывая локальную химическую маркировку РНК с тем, как сообщения разрезаются и сшиваются.
Почему это важно для биологии и медицины
Комбинируя прямое секвенирование РНК с гибким глубоким обучением, ORCA превращает сложный электрический сигнал в богатую многослойную карту химических меток по всему транскриптому. Для неспециалистов главный вывод в том, что теперь учёные могут видеть не только где появляются отдельные модификации РНК, но и какие разные метки украшают одну и ту же молекулу и как эти комбинации соотносятся с регуляцией генов, особенно сплайсингом РНК. Эта платформа позволяет изучать «эпигенетику» РНК во многих типах клеток и условиях без необходимости разрабатывать новый эксперимент для каждой метки, что открывает путь к открытиям о том, как эти мелкие химические правки влияют на развитие, функцию мозга и болезни, такие как рак и неврологические расстройства.
Цитирование: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Ключевые слова: модификации РНК, нанопоровое секвенирование, глубокое обучение, эпитранскриптом, альтернативный сплайсинг