Clear Sky Science · ru
Демонстрационная модель машинного обучения для краткосрочной стратификации риска суицида у депрессивной молодёжи
Почему это важно для семей и опекунов
Суицид — один из самых пугающих рисков для подростков и молодых взрослых с депрессией. Семьям и клиницистам часто трудно определить, кто находится в непосредственной опасности, а кто относительно безопасен после лечения. В этом исследовании изучается, может ли компьютерный поиск закономерностей — так называемое машинное обучение — помочь быстро разделить молодых пациентов по краткосрочным уровням риска, потенциально направляя более пристальное наблюдение за теми, кто в нём больше всего нуждается.

Более пристальный взгляд на молодых людей после лечения
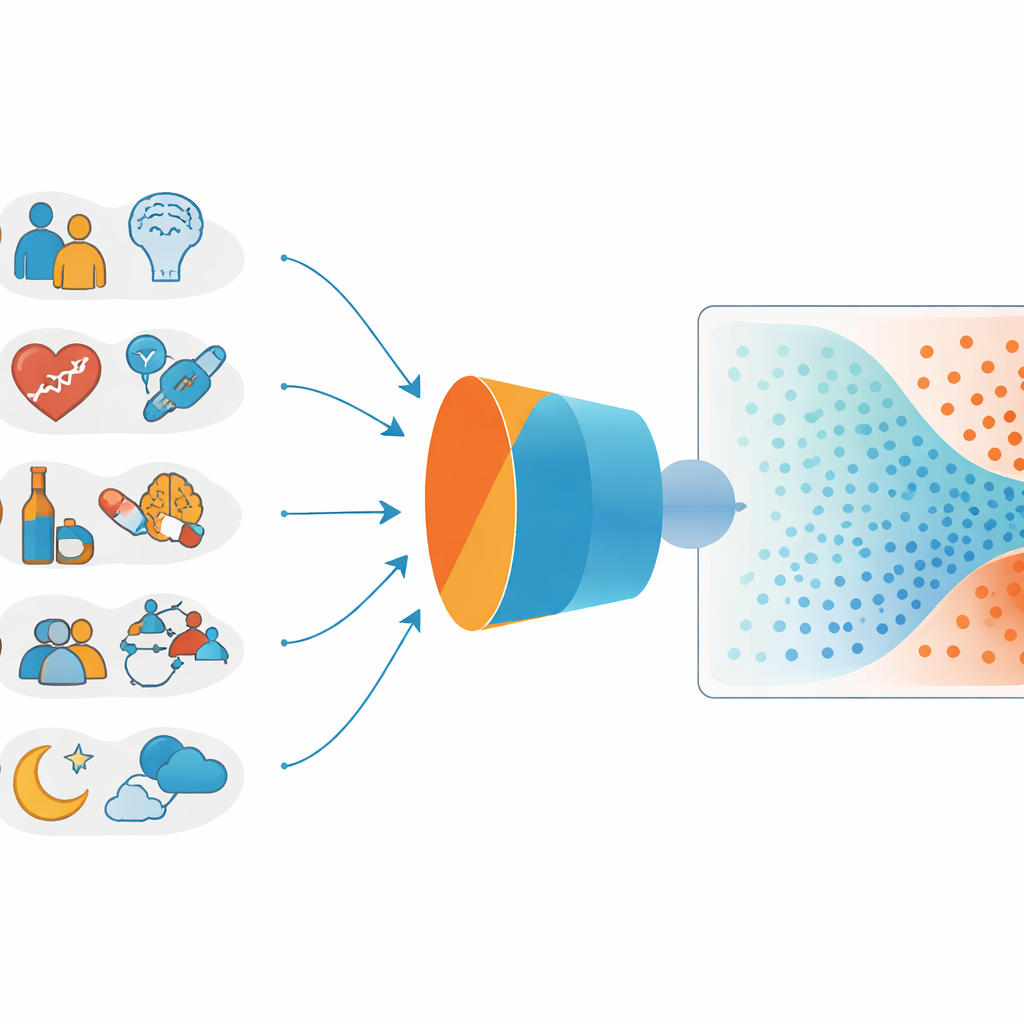
Исследование проследило за 602 подростками и молодыми взрослыми в Китае в возрасте от 15 до 24 лет, все они получали помощь при депрессивных расстройствах в больницах и клиниках. В течение 30 дней после лечения команда проверяла, совершал ли каждый пациент попытку самоубийства. Во время визитов пациенты заполняли широкий набор анкет и проходили интервью о настроении, тревоге, сне, стрессе, истории самоповреждений, семейном фоне и повседневном функционировании, а клиницисты фиксировали медицинские детали, такие как статус стационарного или амбулаторного лечения и приём лекарств. Эта богатая смесь данных создала подробную картину жизни и симптомов каждого пациента в момент их обращения за помощью.
Обучение компьютеров обнаруживать скрытые закономерности
Затем исследователи обучили несколько типов моделей машинного обучения прогнозировать, кто совершит попытку самоубийства в течение месяца после лечения. Они подавали моделям по 102 различным показателя на пациента и разделили выборку так, чтобы большая часть пациентов использовалась для обучения моделей, тогда как отдельная меньшая группа оставалась для проверки того, как модели работают на новых случаях. Вместо стремления к излишней сложности команда сосредоточилась на подходах, позволяющих моделям оставаться проще и меньше поддаваться случайному шуму в данных.
Что модели могли и чего не могли
Из семи протестированных подходов наилучшие результаты показали два относительно простых метода — так называемые опорные векторы (support vector machines) и эластичная сетка (elastic net regression). В комбинированном ансамбле они достигли высокой способности различать пациентов с более высоким и более низким риском. Модель особенно хорошо выявляла небольшую подгруппу, примерно каждого десятого пациента, у которой риск попытки самоубийства был в несколько раз выше, чем у остальной части группы. В то же время её предсказания были более надёжны для исключения непосредственной опасности, чем для точного указания, кто именно совершит попытку, то есть многие помеченные как высокорисковые всё равно не причинят себе вреда.
Сигналы, заметные в повседневной жизни
Исследование также прояснило, какие типы информации имели наибольшее значение для решений компьютера. Некоторые факторы были фиксированными, такие как пол, уровень образования или широкая семейная история психических заболеваний. Другие были изменяемыми и тесно связаны с повседневной жизнью: насколько тяжёлая у человека депрессия, употребляет ли он алкоголь, насколько добросовестно принимает назначенные препараты, насколько интенсивно он погружён в негативные размышления и насколько близкими и поддерживающими кажутся семейные отношения. Разные алгоритмы выделяли слегка разные детали, но оба согласились, что текущая тяжесть депрессии является центральным фактором, подчёркивая важность агрессивного лечения симптомов и поддержания здоровых распорядков.
Ограничения и дальнейшие шаги
Несмотря на обнадёживающие результаты, авторы подчёркивают, что их модель не готова самостоятельно руководить клиническими решениями. В исследовании было всего 30 попыток самоубийства, что делает любую модель хрупкой, и все участники происходили из одной страны и в основном из похожих клинических условий. Модель тестировали только в течение 18 месяцев, поэтому неясно, насколько хорошо она будет работать по мере изменения практик лечения и социальных факторов. Эта работа должна восприниматься как доказательство концепции: она показывает, что комбинирование детальной клинической и жизненной информации с тщательно подобранными методами машинного обучения может осмысленно разделять молодых пациентов по краткосрочному риску суицида и указывает на конкретные, изменяемые области — такие как тяжесть депрессии, употребление алкоголя, привычки приёма лекарств и семейная поддержка — где целевая помощь может помочь сделать уязвимых молодёжь безопаснее.
Цитирование: Sun, B., Zhang, J., Ma, Y. et al. A proof-of-concept machine learning model for short-term suicide risk stratification in depressed youth. Transl Psychiatry 16, 187 (2026). https://doi.org/10.1038/s41398-026-03944-4
Ключевые слова: депрессия у молодёжи, риск суицида, машинное обучение, прогноз риска, скрининг психического здоровья