Clear Sky Science · ru
Оценка и редактирование освещения для динамического дисплея светового поля по одному виду
Почему ваш виртуальный мир должен соответствовать вашей гостиной
Каждый, кто надевал шлем виртуальной или смешанной реальности, сталкивался с этим: цифровой объект выглядит неуместно — освещение и тени не соответствуют вашей комнате. В этой работе решается именно эта задача. Авторы предлагают способ, позволяющий шлемам «понимать» освещение в реальной среде по одному лишь виду с камеры, а затем использовать это знание, чтобы виртуальные объекты выглядели так, будто действительно принадлежат вашему миру — без специальных световых зондов, сложных съемок или длительной перенастройки.
Упрощение работы со светом в пространстве
В физике и компьютерной графике внешний вид сцены определяется полным «световым полем»: всеми световыми лучами, проходящими через пространство во всех направлениях. Точное восстановление этого поля обычно требует большого объема данных — множества изображений и тщательных измерений. Современные 3D-техники, такие как нейронные поля излучения, хранят сцены в нейросетях, но обычно «впечатывают» освещение, присутствовавшее при съемке. Это означает, что виртуальная сцена выглядит правильно только при тех исходных условиях и теряет правдоподобие, когда освещение в реальной комнате меняется. Авторы ставят цель сломать это ограничение, найдя компактное представление реального освещения по минимальным данным и используя его для гибкого пересвещения света в нейронной 3D-сцене.
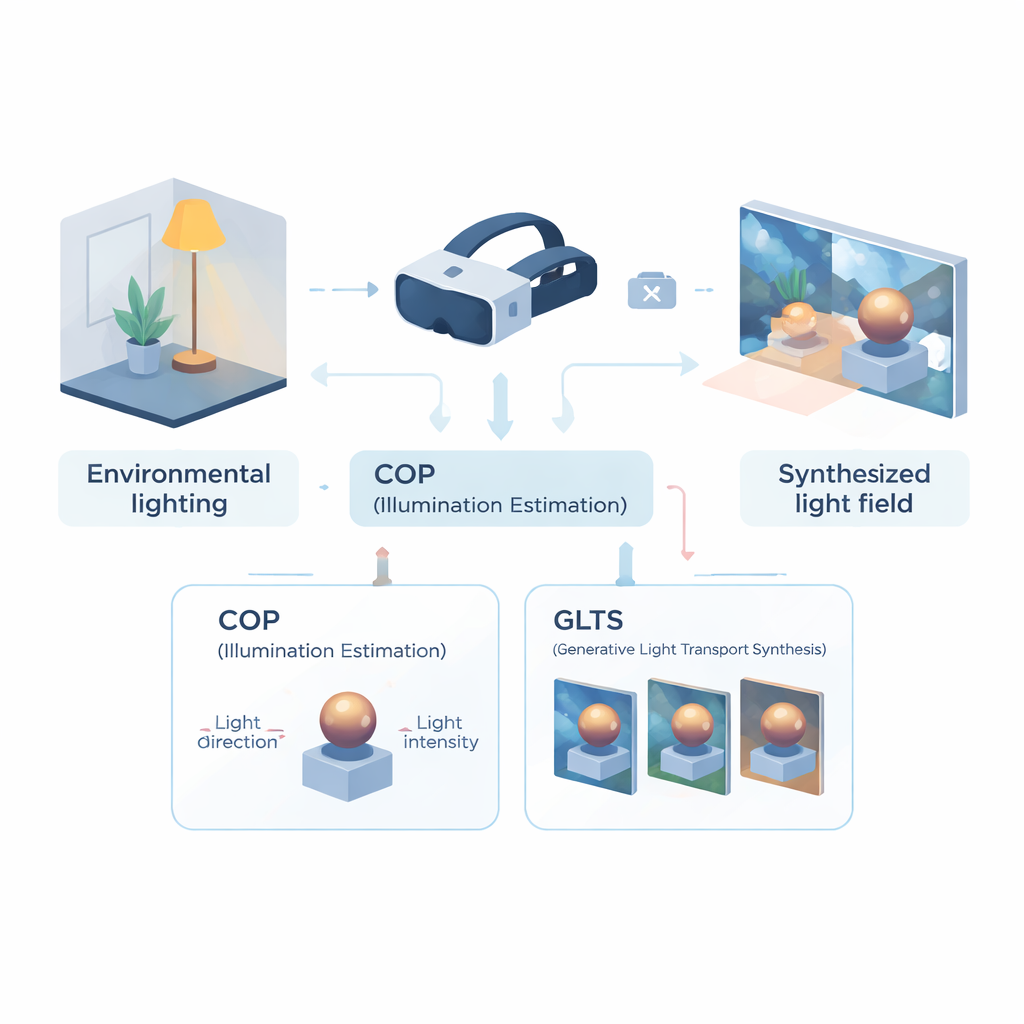
Обучение шлема «читать» комнату
Первая часть фреймворка — модуль вычислительного оптического восприятия (COP), предназначенный для чтения освещения по одному виду с камеры. Вместо попытки восстановить все световое поле COP фокусируется на доминирующем источнике света: его направлении и интенсивности. Многоуровневая нейросеть сканирует входное изображение в поисках физических подсказок — ярких бликов, градиентов затенения и теней — а специальный шаг интерполяции корректирует нелинейную компрессию яркости камерой. Это дает численные оценки направления и интенсивности света, более верно отражающие реальную энергию в сцене. Второй этап, называемый семантическим интерпретатором, затем уточняет эти значения и формирует короткое текстовое описание освещения (например, что свет идет сверху и справа). Такое сочетание чисел и слов делает оценку более стабильной и удобной для дальнейшего использования.
Перерисовка объектов под новым светом
Вооружившись компактным описанием освещения, берет на себя вторую часть — генеративный синтез переноса света (GLTS). GLTS начинает с существующего нейронного 3D-представления объекта или сцены, однажды отрендеренного при «запеченном» освещении. Под руководством найденного направления и интенсивности света, а также текстового описания, генеративная сеть «перерисовывает» этот вид, чтобы блики и тени соответствовали новой среде. Чтобы сохранить реализм и индивидуальность объекта, GLTS комбинирует два вида управления: глобальные параметры освещения и тонкие детали, извлеченные прямо из наблюдаемого изображения. Через специальный процесс обучения, сосредоточенный именно на реакции одного объекта на разные условия освещения, модель учится сдвигать отражения и смягчать края теней физически правдоподобным образом, а не просто применять общий стилевой фильтр.
Построение согласованного 3D-светового поля из множества видов
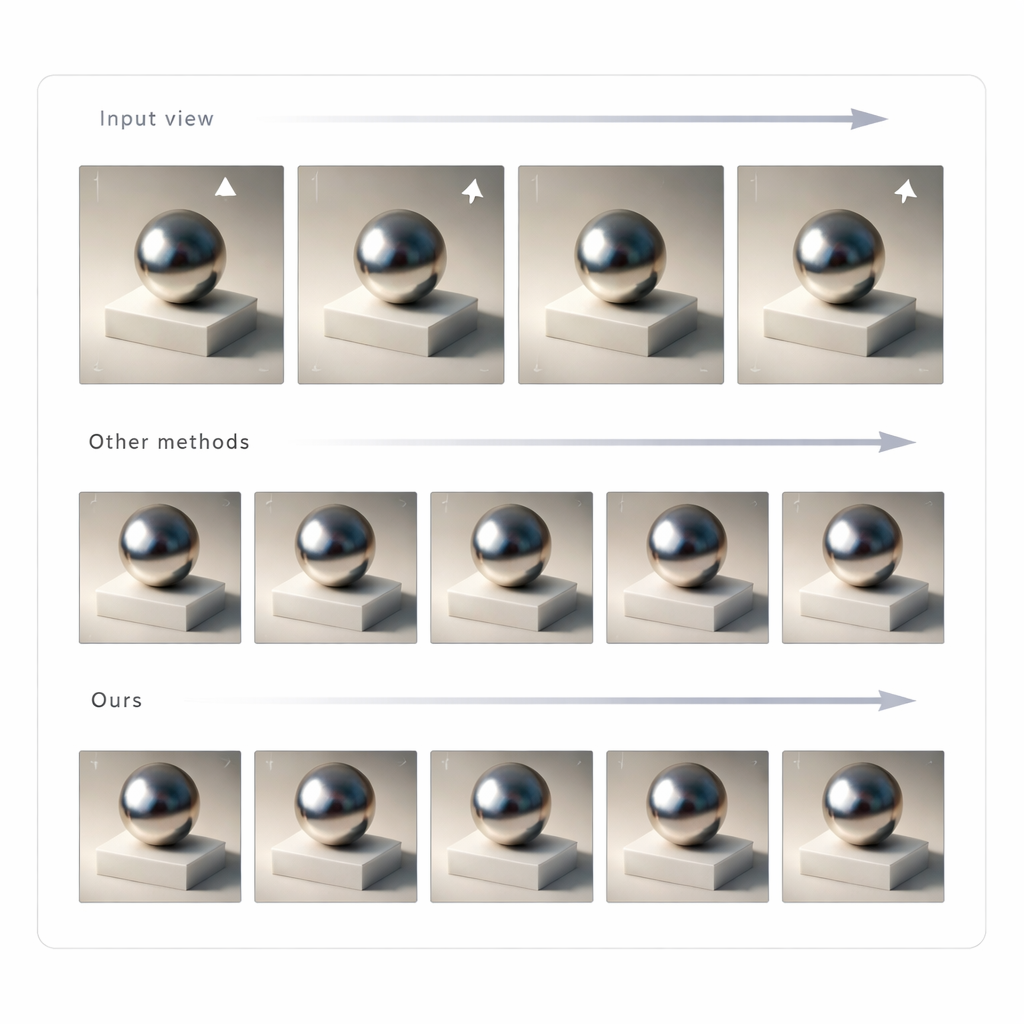
Изменения одного изображения недостаточно для убедительной смешанной реальности — освещение должно оставаться согласованным, когда вы двигаете головой. Для этого авторы используют GLTS, чтобы сгенерировать набор пересвеченных изображений с разных точек обзора, а затем рассматривают их как цели для воссоздания 3D-сцены. Совместный процесс оптимизации одновременно настраивает нейронное 3D-представление и виртуальные позиции камер так, чтобы рендер новой модели воспроизводил все синтезированные виды. Этот шаг исправляет тонкие искажения, вносимые генеративной сетью, и дает целостный 3D-объект, внешний вид которого остается стабильным и правдоподобным под любым углом. Команда протестировала свой метод в сравнении с несколькими современными подходами к пересвету и обнаружила, что он обеспечивает более точное совпадение с эталонными изображениями и более естественные тени и отражения по пиксельным и перцепционным метрикам.
Что это значит для будущих шлемов
Для неспециалистов главный вывод в том, что эта работа демонстрирует, как будущие устройства VR, AR и смешанной реальности смогут подстраивать виртуальный контент под реальное освещение по одному быстрому взгляду камеры шлема. Вместо трудоемкой съемки или перенастройки индивидуальных моделей для каждой новой сцены система оценивает основные условия освещения, регенерирует вид сцены при этих условиях и восстанавливает согласованное 3D-представление. В результате виртуальные объекты по яркости, блеску и теням реагируют на окружение почти как реальные предметы, что прокладывает путь к смешанной реальности, которая ощущается не как поверхностная графика, а как подлинное дополнение к физическому миру.
Цитирование: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Ключевые слова: освещение смешанной реальности, нейронные световые поля, пересвет по одному виду, дисплеи виртуальной реальности, вычислительная съемка