Clear Sky Science · ru
Определение визуальной информации и вопросы-ответы по носителям нематериального культурного наследия с использованием улучшенной графово-поисковой архитектуры
Перевод скрытых традиций в цифровую эпоху
По всей Китаю мастера традиционной оперы, вырезки из бумаги, театр теней и другие живые ремёсла сохраняют навыки, передающиеся из поколения в поколение. Тем не менее большая часть сведений о таких носителях хранится лишь в разбросанных файлах и изображениях в сети, что затрудняет поиск надёжной информации как для широкой публики, так и для исследователей. В этой статье представлен новый компьютерный фреймворк, который автоматически считывает «визитные карточки» носителей нематериального культурного наследия (НКН) и затем с помощью современных языковых моделей отвечает на вопросы и формирует читабельные отчёты о них.
От карточек с картинками к структурированным знаниям
Многие культурные учреждения публикуют цифровые карточки, объединяющие текст, макет и простую графику для представления каждого носителя: имя, ремесло, место, биография и прочее. Люди могут пробежать по ним взглядом, тогда как компьютерам это даётся сложно: карточки поступают из разных регионов, используют разнообразные оформления и часто содержат пропавший или повреждённый текст. Авторы создали крупный датасет из 5 237 таких карточек носителей НКН Китая, каждая из которых помечена десятью ключевыми типами информации — например, номер проекта, название проекта, регион, пол, место работы и короткое описание. Они сначала используют оптическое распознавание текста (OCR), чтобы считать текст и зафиксировать, где на карточке расположен каждый фрагмент, затем привлекают крупные языковые модели для стандартизации меток, после чего верификацию проводят эксперты-человеки.
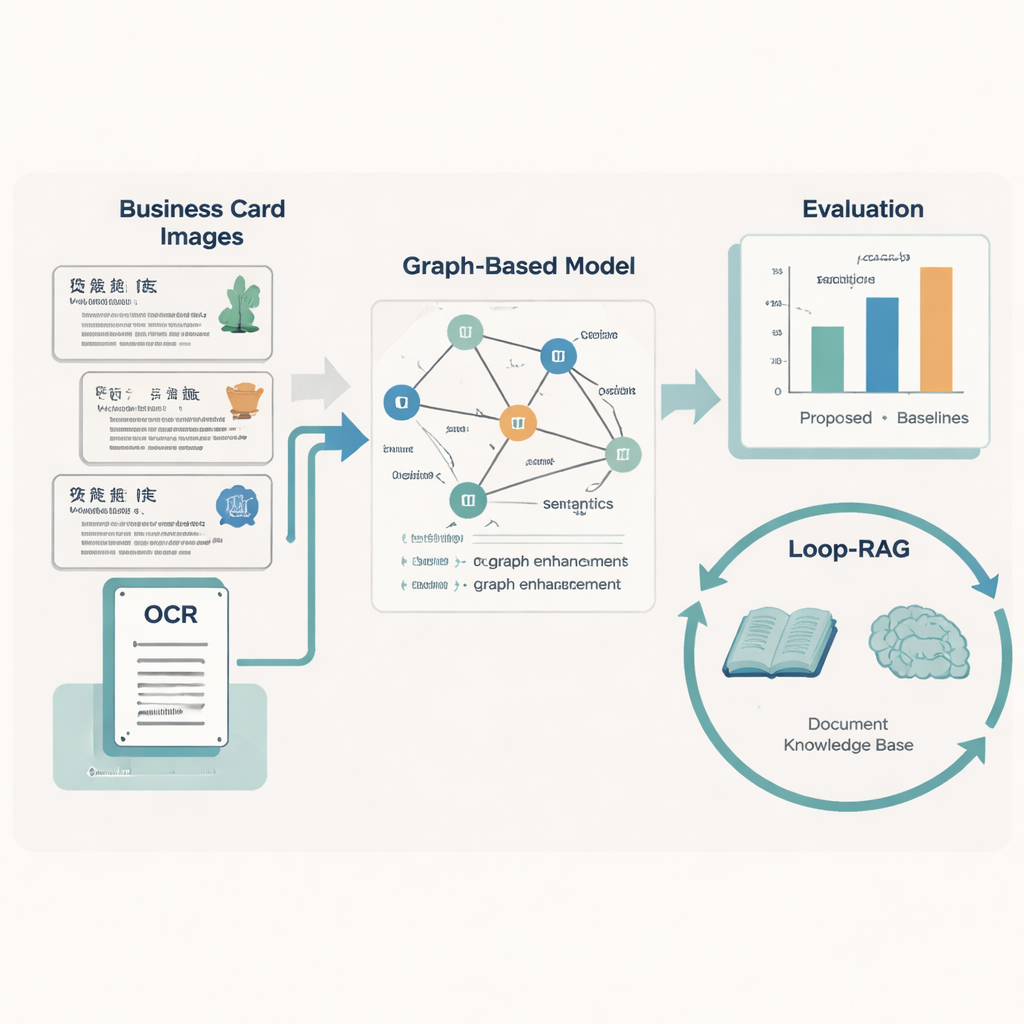
Обучая машины понимать разметку и смысл
Чтобы преобразовать каждую карточку в аккуратные структурированные данные, команда разработала модель «Graph-Retrieval», имитирующую то, как люди учитывают и слова, и расположение. Каждый текстовый фрагмент на карточке становится узлом в графе, а пространственные отношения между фрагментами — слева, справа, выше, ниже — формируют ребра. Языковой компонент на базе RoBERTa и двунаправленного LSTM изучает смысл текста, поддерживаемый пользовательским словарем почти из 5 000 терминов, специфичных для НКН, чтобы правильно обрабатывать редкие названия ремёсел и местные выражения. Поверх этого графовая нейронная сеть распространяет информацию по соседним узлам, улучшая предсказания о том, что представляет собой каждый текстовый фрагмент (например, решение, является ли топоним регионом или организацией).
Повышение устойчивости системы к реальной неряшливости данных
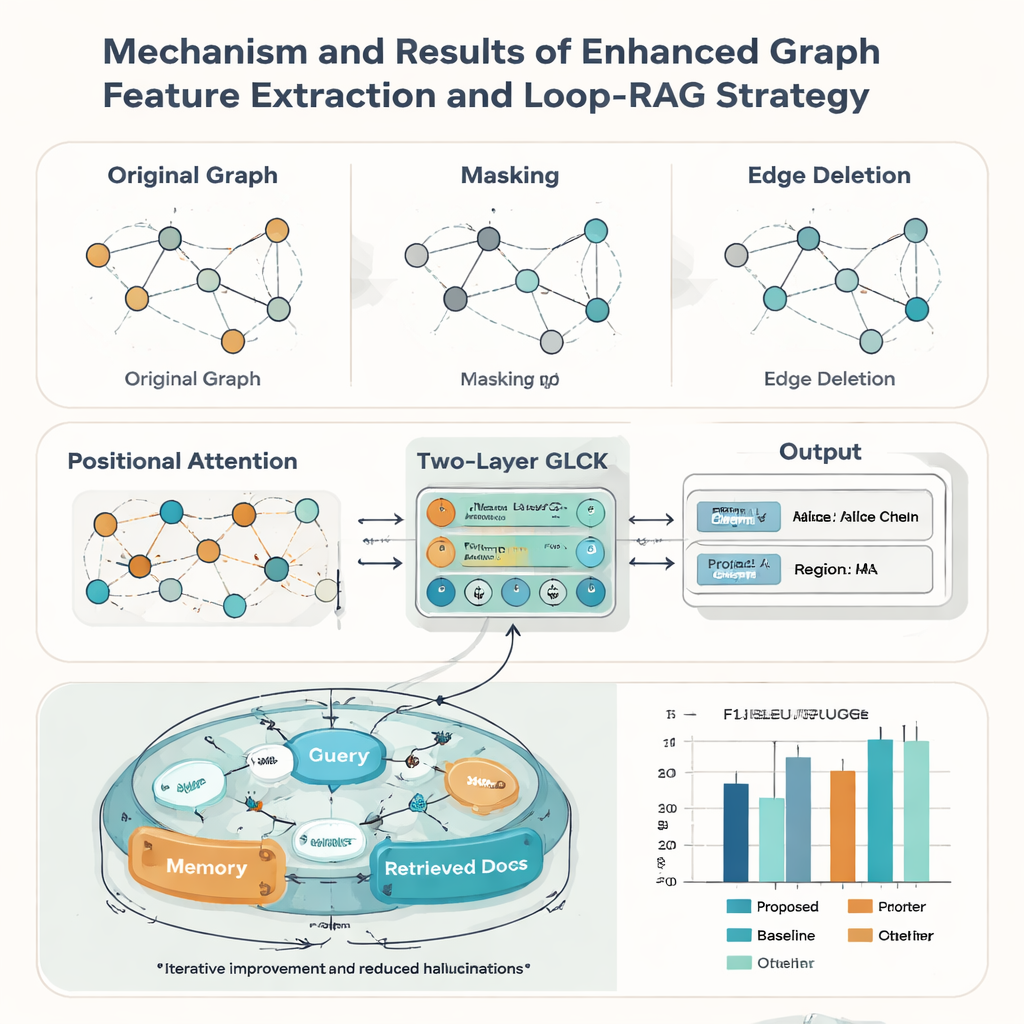
Реальные карточки наследия редко бывают идеальными: они могут быть изношенными, обрезанными или плохо отсканированными. Чтобы справиться с этим, авторы усиливают свою графовую модель тремя идеями, заимствованными из аугментации данных. Они случайным образом маскируют некоторые узлы, чтобы система училась выводить недостающую информацию из контекста; случайно удаляют некоторые ребра, чтобы модель выдерживала изменения в макете; и добавляют позиционный механизм внимания, улавливающий общий «порядок чтения» элементов на карточке. В совокупности эти приёмы помогают модели обобщать на множество стилей и качеств документов. В испытаниях против девяти известных конкурирующих методов новый подход достигает наивысшего макро-среднего F1 (0.928) на наборе карточек НКН и выигрывает также на пяти публичных бенчмарках документов, что указывает на его широкую применимость за пределами наследственных задач.
Более умные ответы на вопросы с цикличным поиском
Распознавание текста — лишь половина задачи; второе вкладение статьи — стратегия Loop-RAG (Loop Retrieval-Augmented Generation), работающая с крупными языковыми моделями, такими как GPT-4, Llama и ChatGLM. Традиционные системы с дополнением поиска один раз извлекают фоновые документы и затем генерируют ответ, который всё ещё может быть неполным или неверным. В отличие от них, Loop-RAG добавляет внутренний цикл, который повторно проверяет, достаточно ли у языковой модели информации для текущего ответа, и, если нет, запускает ещё один целевой поиск в векторизованной базе знаний по НКН. Внешний цикл затем анализирует многие прошлые взаимодействия, чтобы выяснить, какие пути поиска и стили подсказок работают лучше всего, постепенно уменьшая лишние запросы и фактические ошибки.
От сырых записей к заслуживающим доверия культурным историям
Используя этот комбинированный фреймворк, система может автоматически создавать короткие отчёты о носителе — суммировать его ремесло, регион, репрезентативные работы и статус — и отвечать на тысячи фактических вопросов о людях и практиках. По стандартным метрикам качества языка, таким как BLEU, METEOR и ROUGE, Loop-RAG с GPT-4 превосходит как простые языковые модели, так и более простые схемы поиска, при этом достигая лучшей точности (F1 до 0.941) в задачах вопрос-ответ даже при наличии всего нескольких примеров. Для неспециалиста это означает, что будущие платформы культурного наследия смогут по требованию предлагать интерактивные, заслуживающие доверия объяснения традиционных искусств, превращая разрозненные цифровые записи в насыщенные, удобные для навигации истории, которые помогают сохранять видимость и ценность живых традиций.
Цитирование: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Ключевые слова: нематериальное культурное наследие, извлечение информации, графовые нейронные сети, генерация с поддержкой поиска, цифровые гуманитарные науки