Clear Sky Science · ru
Высокоточная 3D-реконструкция объектов культурного наследия с помощью суперразрешения и прогрессивного Gaussian splatting
Почему важна более четкая цифровая копия реликвий
Музеи и археологи по всему миру спешат создавать точные 3D-копии хрупких артефактов — от фарфоровых ваз до храмовых ворот. Эти цифровые аналоги позволяют изучать, демонстрировать и сохранять культурные ценности, не касаясь оригиналов. Но в реальности фотографии объектов наследия часто тёмные, размытые или сделаны с неудобных ракурсов, что приводит к искажениям или неполноте при современном 3D-воссоздании. В этой работе предложен новый подход, который решает эту проблему комплексно: улучшает исходные снимки и стабилизирует процесс 3D-моделирования.
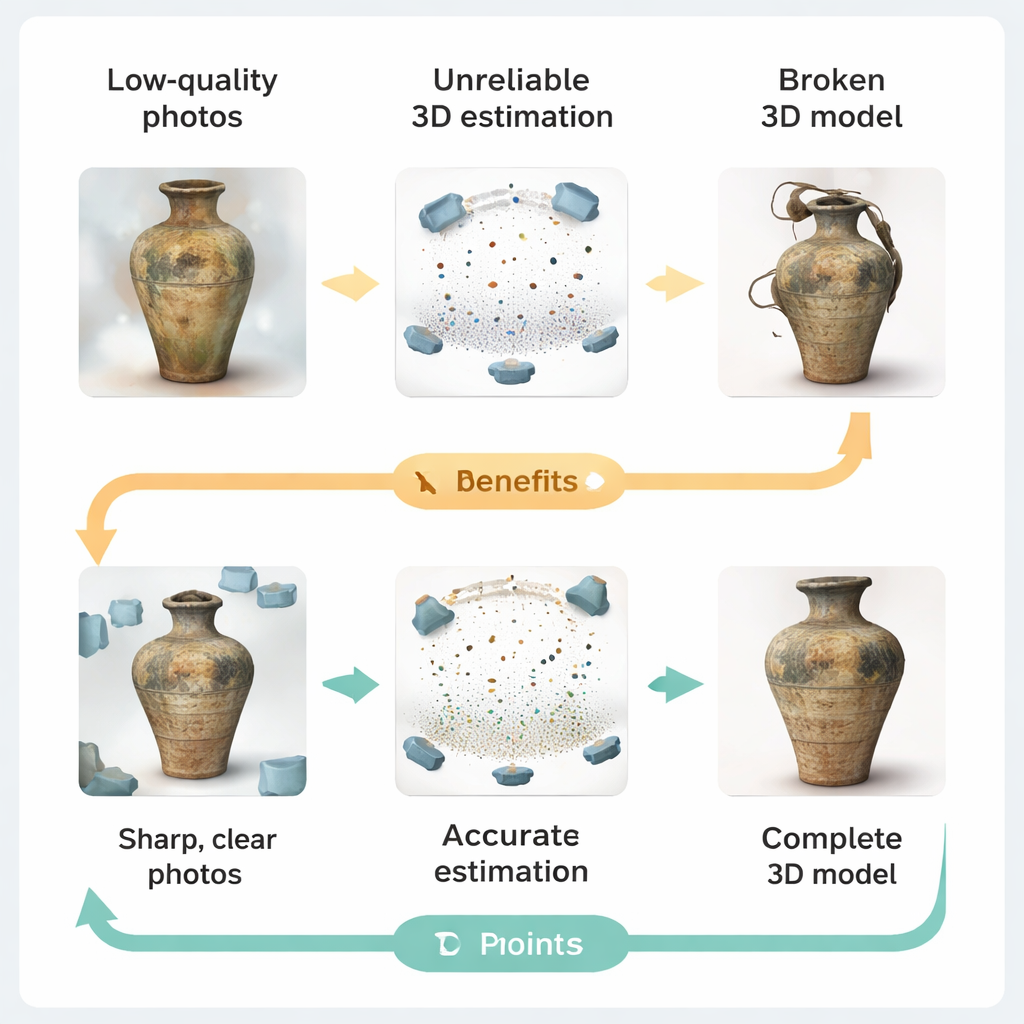
Когда плохие фотографии ломают 3D-модели
Типичные конвейеры 3D-сканирования следуют простой идее: сделать много снимков, оценить положение камер, восстановить форму объекта и отрендерить 3D-модель. На практике места наследия редко имеют студийное качество съёмки. Слабое освещение, изношенные или неровные поверхности, отражения от витрин и ограничения на расположение камеры ухудшают изображения. Авторы показывают, как эти дефекты распространяются по конвейеру. Размытые или низкокачественные кадры затрудняют сопоставление признаков между видами, что ведёт к ошибкам в позах камер и «пробоинам» в оценках глубины. Когда такие ненадёжные измерения попадают в современные рендереры на основе «Gaussian splatting» — системы, строящие сцену из тысяч мелких цветных «капель» — это вызывает нестабильную оптимизацию, избыточные «капли» и заметные искажения геометрии.
Улучшение фото с помощью более умного повышения разрешения
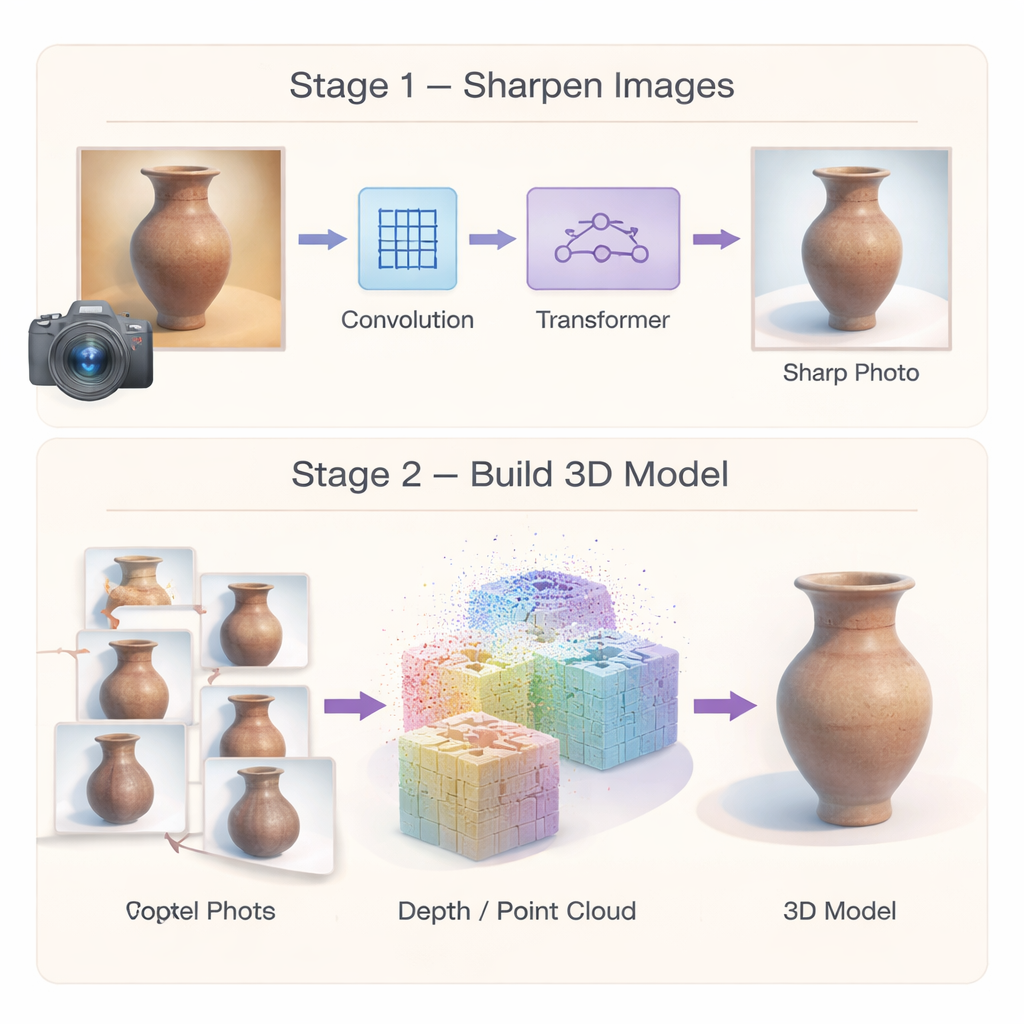
Чтобы остановить ошибки в корне, авторы сначала создают специализированную сеть суперразрешения, которая превращает низкокачественные фотографии объектов наследия в более чёткие и детализированные. Вместо опоры на один тип обработки сеть объединяет два подхода. Многомасштабный сверточный модуль фокусируется на локальных деталях — трещинах, мазках кисти или резных линиях — анализируя изображение на нескольких уровнях соседних областей одновременно. Эффективный модуль Transformer затем улавливает более широкие паттерны, такие как повторяющиеся мотивы или длинные кривые, проходящие по объекту. Третий компонент выборочно усиливает действительно схожие регионы изображения и подавляет шум, так что слабые текстуры проясняются, а не размываются. Вкупе эти элементы создают высокоразрешённые изображения, сохраняющие и тонкий орнамент, и общую структуру, давая последующим 3D-этапам значительно лучшее исходное представление.
Построение более устойчивых 3D-форм из множества видов
Одного улучшения снимков недостаточно; сама 3D-реконструкция тоже должна быть надёжной. Вторая часть фреймворка пересматривает, как инициализируется и оптимизируется 3D-модель. Вместо опоры на разреженный набор сопоставленных точек авторы используют «плотное» сопоставление, которое с самого начала формирует богатые облака точек и более надёжные позы камер. Эти плотные точки служат прочным геометрическим скелетом сцены. Поверх этого они вводят гибридное представление: пространство вокруг артефакта разбито на грубые 3D-ячейки, а общий декодер предсказывает детализированный цвет и форму множества мелких «капель» внутри каждой ячейки. Поскольку параметры в основном разделяются, а не дублируются, метод уменьшает использование памяти и поощряет гладкие, связные поверхности, делая итоговую модель менее подверженной случайным выступам и дыркам.
Обучение мягкими шагами вместо всего сразу
Авторы также меняют процедуру обучения системы. Вместо того чтобы сразу требовать от модели соответствия и внешнего вида, и геометрии — сценарий, ведущий к застреванию в плохих решениях — они применяют триэтапную стратегию. Сначала система учится только воспроизводить цвета входных снимков, обеспечивая глобальную визуальную согласованность. Затем постепенно добавляется информация о глубине, полученная из плотных облаков точек, что направляет модель к правдоподобным поверхностям. На финальном этапе уточняются мелкие детали путём обеспечения согласованности между перекрывающимися фрагментами изображений из разных видов. Протестированная на новом наборе данных Cultural-Relics, включающем фарфор, мебель, ремёсла и текстиль, а также на стандартном бенчмарке сложных внешних сцен, эта поэтапная методика не только улучшает визуальное качество, но и сокращает время обучения и расход памяти по сравнению с ведущими альтернативами.
Что это означает для сохранения прошлого
Для неспециалистов основной посыл прост: этот фреймворк помогает превращать несовершенные музейные или полевые фотографии в более чистые и точные 3D-копии объектов культурного наследия без физического контакта с ними. Благодаря повышению чёткости низкокачественных снимков, старту от более прочного геометрического скелета и поэтапному обучению 3D-модели метод создаёт цифровые артефакты, лучше передающие мелкий декор и общую форму при меньших вычислительных затратах. На практике это упрощает музеям, реставраторам и исследователям создание надёжных виртуальных коллекций из обычных фотосъёмок, помогая защищать хрупкие предметы и широко делиться ими с учёными и публикой.
Цитирование: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Ключевые слова: оцифровка культурного наследия, 3D-реконструкция, суперразрешение изображений, Gaussian splatting, цифровое сохранение