Clear Sky Science · ru
Создание корпусa «Двадцати четырех историй» с разметкой частей речи для древнего и современного китайского
Почему старинные хроники важны в эпоху ИИ
Более двух тысяч лет китайские историки фиксировали войны, придворные события, неурожаи и повседневную жизнь в обширном своде, известном как «Двадцать четыре истории». Сегодня эти классические тексты заново открывают не только исследователи, но и компьютеры. В этой работе описывается, как учёные превратили древние хроники и их современные китайские переводы в тщательно размеченную языковую базу данных. Этот ресурс помогает искусственному интеллекту точнее читать, переводить и анализировать исторические тексты — и делает далёкое прошлое гораздо более доступным для широкой аудитории.
От пыльных томов к цифровому тексту
Проект начинается с простой, но трудоёмкой задачи: превратить миллионы напечатанных знаков в чистый, точный цифровой текст. Команда опиралась на два источника — авторитетное современное издание «Двадцати четырёх историй» и крупную онлайновую коллекцию — чтобы прогнать их через систему оптического распознавания текста. Затем они кропотливо убирали искажённые фрагменты, исправляли неверно распознанные знаки и удаляли шум вроде заголовков и колонтитулов. В результате получился параллельный набор файлов — один на древнем китайском, другой на современном — который точно соответствовал оригинальным книгам и был готов для вычислительного анализа. 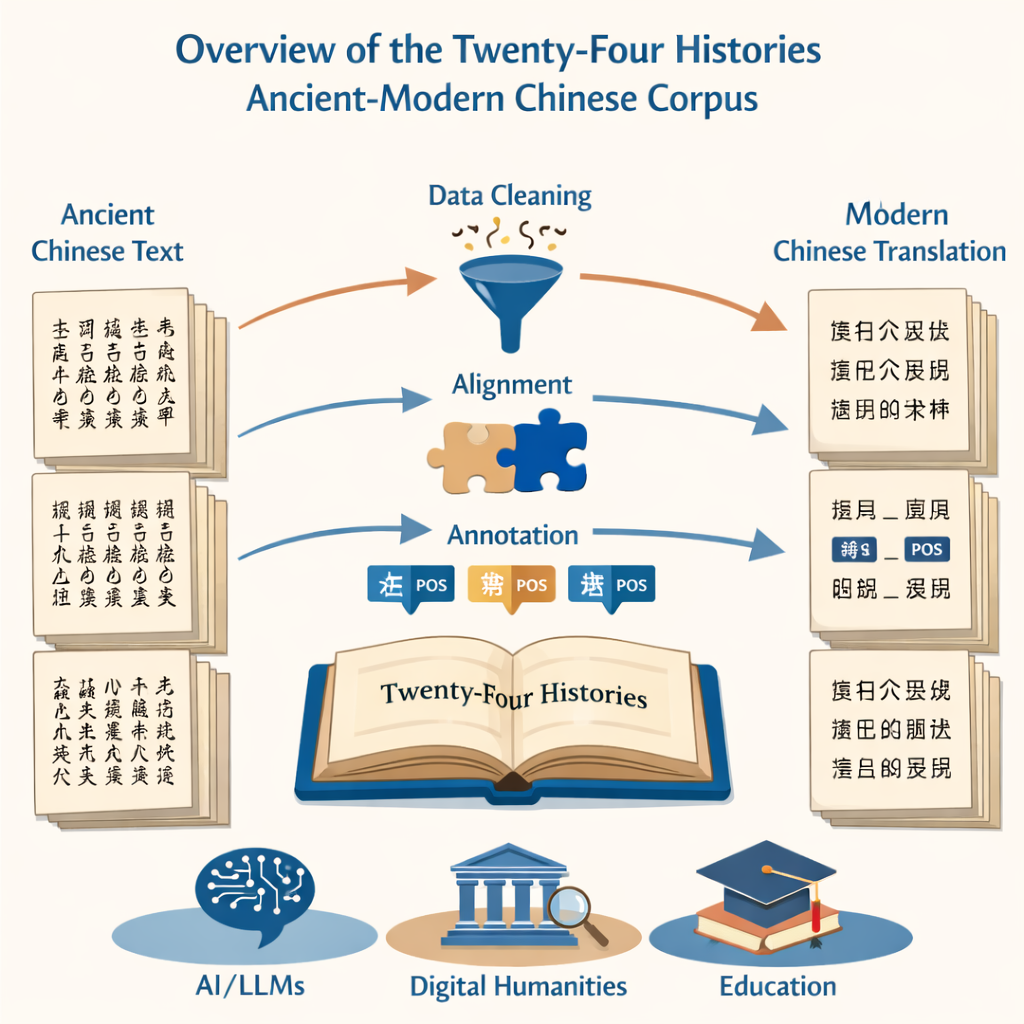
Сопоставление древних предложений с современными
Поскольку цель заключалась в сравнении изменения языка во времени, было важно выровнять старые и новые версии по предложениям. Исследователи использовали специализированное программное обеспечение для выравнивания: сначала оно соотносило абзацы, затем делило их на соответствующие предложения. Автоматические инструменты выполняли основную работу, но эксперты-человеки проверяли каждую предложенную пару, так как грамматика древнего китайского может сильно отличаться от современной. Там, где программа ошибалась — разрезала мысль в неправильном месте или неверно распознала знак — аннотаторы сверялись с оригинальными отсканированными страницами и корректировали цифровой текст, чтобы каждое древнее предложение точно соответствовало своему современному эквиваленту.
Обучение компьютеров распознавать грамматику
Помимо простой транскрипции, ядром проекта стала грамматическая разметка. Каждое слово в древних и современных текстах было помечено тегом части речи, указывающим, является ли оно, например, существительным, глаголом или словом времени. Поскольку для древнего китайского не существует единого стандарта, команда привязала свою систему к современным национальным рекомендациям, а затем адаптировала их для древних употреблений. Они разработали схему из 22 тегов, включающую специальную метку для уникальных древних глагольных значений, таких как «давать жизнь» или «умирать за страну». Кастомная нейросеть — построенная на языковой модели для древних текстов с последовательным слоёвым разметчиком — выдала начальные теги, которые затем проверялись и исправлялись большой командой хорошо подготовленных аспирантов. Строгие тесты согласованности между аннотаторами показали очень высокую степень совпадения, что подтверждает: финальный размеченный корпус одновременно велик и надёжен.
Что открывает новый ракурс
Имея размеченный корпус, авторы проанализировали некоторые видимые в нём закономерности. В древнем китайском доминируют односимвольные слова, что отражает известную компактность письменной формы, тогда как в современном китайском чаще встречаются двусимвольные слова. Наиболее распространённые древние элементы — мелкие грамматические частицы, такие как «之» и «以», в то время как глаголы и обычные существительные вместе составляют около половины всех слов в обеих эпохах. Данные также показывают, какие слова склонны встречаться вместе — например, конструкции, описывающие должностных лиц, армии или дипломатические миссии. Сравнивая теги в парах «древнее — современное», команда проследила, как смещались функции со временем: некоторые старые предлоги и наречия теперь соответствуют полным современным глаголам, а некоторые глаголы закрепились в виде фиксированных титулов или юридических терминов. В одном из кейсов были извлечены все географические названия и нанесены на карту их кластеры по разным династиям, что выявило перемещение политических и экономических центров с северо-запада к нижнему течению Янцзы и далее. 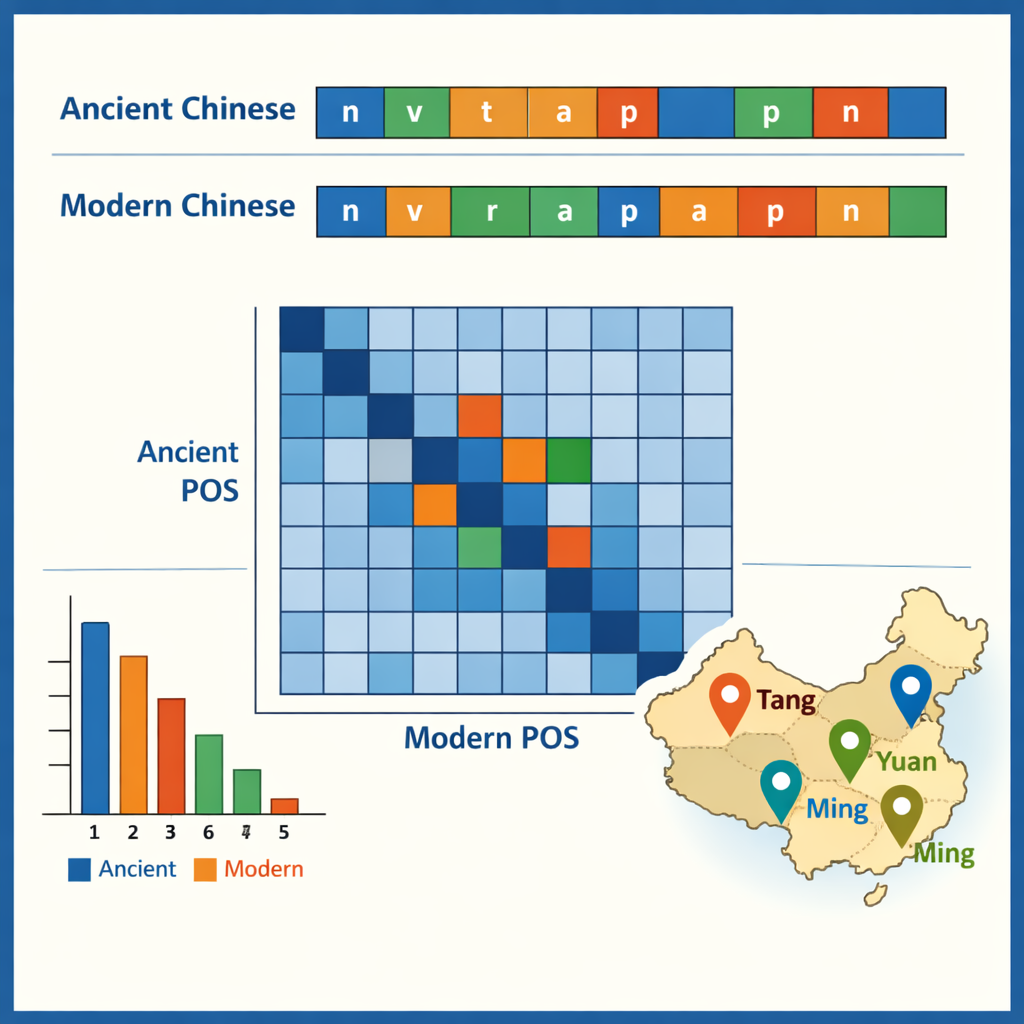
Перенос прошлого в цифровое будущее
Проще говоря, этот проект превращает внушительный массив классической прозы в структурированные данные, с которыми могут работать и люди, и машины. Для историков и лингвистов он предоставляет мощный инструмент для отслеживания эволюции слов, грамматики и даже государственных границ на протяжении столетий. Для разработчиков ИИ — качественный обучающий материал для создания языковых моделей, которые действительно умеют работать с классическим китайским, а не рассматривают его как бессистемное множество знаков. А для студентов и широкой аудитории параллельная построчная привязка древнего и современного текста снижает барьер к чтению классики. Благодаря тщательной разметке и выравниванию «Двадцати четырёх историй» авторы создали мост от рукописных свитков прошлого к интеллектуальным системам настоящего и будущего.
Цитирование: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Ключевые слова: корпус древнекитайских текстов, разметка частей речи, цифровые гуманитарные науки, параллельные тексты, исторические изменения языка